Spark发布1.3.0版本
3月13日, Spark 1.3.0版本与我们如约而至 。这是Spark 1.X发布计划中的第四次发布,距离1.2版本发布约三个月时间。据Spark官方网站报道,此次发布是有史以来最大的一次发布,共有174位开发者为代码库做出贡献,提交次数超过1000次。
此次版本发布的最大亮点是新引入的DataFrame API。对于结构型的DataSet,它提供了更方便更强大的操作运算。事实上,我们可以简单地将DataFrame看做是对RDD的一个封装或者增强,使得Spark能够更好地应对诸如数据表、JSON数据等结构型数据样式(Schema),而不是传统意义上多数语言提供的集合数据结构。在一个数据分析平台中增加对DataFrame的支持,其实也是题中应有之义。诸如R语言、Python的数据分析包pandas都支持对Data Frame数据结构的支持。事实上,Spark DataFrame的设计灵感正是基于R与Pandas。
Databricks的 博客 在今年2月就已经介绍了Spark新的DataFrame API。文中提到了新的DataFrames API的使用方法,支持的数据格式与数据源,对机器学习的支持以及性能测评等。文中还提到与性能相关的实现机制:
与R/Python中data frame使用的eager方式不同,Spark中的DataFrames执行会被查询优化器自动优化。在DataFrame上的计算开始之前,Catalyst优化器会编译操作,这将把DataFrame构建成物理计划来执行。
由于Catalyst进行了两种类型的优化:逻辑优化与物理优化(生成JVM bytecode),因而相较于RDD而言,DataFrame有了更好的性能表现。性能对比如下图所示:
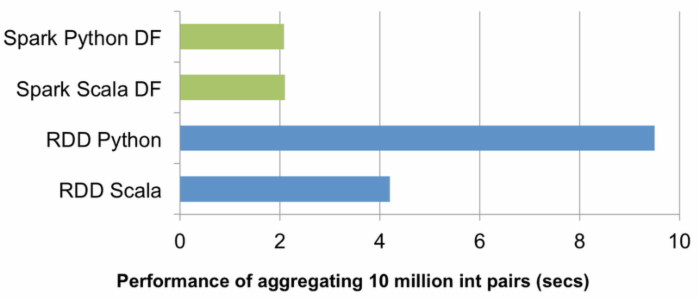
Spark的官方网站已经给出了 DataFrame API的编程指导 。DataFrame的Entry Point为Spark SQL的SQLContext,它可以通过SparkContext对象来创建。如果希望DataFrame与RDD互操作,则可以在Scala中引入隐式装换,完成将RDD转换为DataFrame。由于DataFrame提供了许多Spark SQL支持的功能,例如select操作,因此,它被放到Spark SQL组件中,而不是作为另一种RDD放到Spark Core中。
在Spark 1.3.0版本中,除了DataFrame之外,还值得关注的一点是Spark SQL成为了正式版本,这意味着它将更加的稳定,更加的全面。或许,是时候从HIVE转向Spark SQL了。根据我们的项目经验,代码库从HIVE向Spark SQL的迁移还是比较容易的,毕竟二者的SQL语法非常接近。官方文档也宣称它完全向后兼容HiveQL方言。当然,如果你还在使用Shark,就更有必要将其升级到Spark SQL。
对于其他组件,如Spark ML/MLlib、Spark Streaming和GraphX,最新版本都有各种程度的增强。由于目前Spark的版本发布是定期的三个月周期发布,因此除了每次发布版本的里程碑特性外,其余特性可能都是对现有组件的增强,尤其可能是增加新的算法支持(如机器学习中对LDA的支持)或者对第三方工具的支持(如Streaming中对Kafka的Python支持)。Spark社区还会在发布版本之前对将要发布的特性进行投票,这或许是非常好的开源产品管理实践。
若需了解最新发布的Spark 1.3.0的更多内容,可以访问 Spark官方网站的发布公告 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

