Logstash 指南
日志作为运维中非常重要的一环,往往只有在出了问题的时候才被重视起来,不同部门,不同项目的不同日志如果能够统一规范管理,对日常的开发和业务的运营都是有很大帮助的,这里我们来了解一下实时日志处理领域开源第一选择 - ELK 套餐中的 L - Logstash
简介
从 Logstash 的名字就能看出,它主要负责跟日志相关的各类操作,不过在此之前,我们先来看看日志管理的三个境界吧。
境界一:『昨夜西风凋碧树。独上高楼,望尽天涯路』,在各台服务器上用传统的 linux 工具(如 cat, tail, sed, awk, grep 等)对日志进行简单的分析和处理,基本上可以认为是命令级别的操作,成本很低,速度很快,但难以复用,也只能完成基本的操作。
境界二:『衣带渐宽终不悔,为伊消得人憔悴』,服务器多了之后,分散管理的成本变得越来越多,所以会利用 rsyslog 这样的工具,把各台机器上的日志汇总到某一台指定的服务器上,进行集中化管理。这样带来的问题是日志量剧增,小作坊式的管理基本难以满足需求。
境界三:『众里寻他千百度,蓦然回首,那人却在灯火阑珊处』,随着日志量的增大,我们从日志中获取去所需信息,并找到各类关联事件的难度会逐渐加大,这个时候,就是 Logstash 登场的时候了。
Logstash 的主要优势在我看来有俩,一个是在支持各类插件的前提下提供统一的管道进行日志处理(就是 input-filter-output 这一套),二个是灵活且性能不错。
架构
Logstash 是由 JRuby 编写的,使用基于消息的简单架构,在 JVM 上运行。理念非常简单,如果说 MapReduce 框架分为 Mapper 和 Reducer 两大模块,那么 Logstash 有仨:
- Collect: 数据输入。对应 input
- Enrich: 数据处理。对应 filter
- Transport: 数据输出。对应 output
虽然模块仅仅比 MapReduce 框架多了一个,但是无三不成几,通过不同的拓扑结构,可以完成各类数据处理应用。不过这里我们主要还是以日志汇总处理系统的思路来进行介绍,一个典型的架构为:
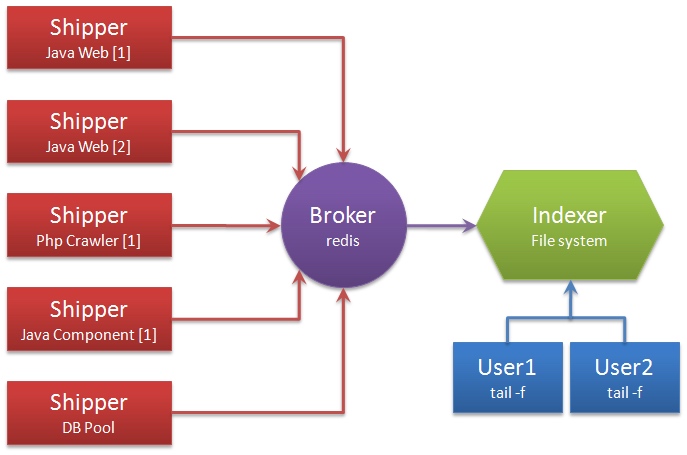
图中的三个组件为 Shipper, Broker 和 Indexer,这里我们结合上图分别来进行介绍
- Shipper 负责日志收集。职责是监控本地日志文件的变化,并输出到 Redis 缓存起来。实际部署是我们也可以考虑一些替代方案,比方说用
rsyslog来取代 Shipper,这样就可以减少在各个服务器配置 Logstash 的工作量,也可以结合logrotate进行版本管理,具体方式很多,可以根据需要选择最合适的方式,切换的成本也不会特别高,只要原始日志不丢,其他都好说。 - Broker 可以看作是日志集线器,可以连接多个 Shipper 和多个 Indexer。实际情况中是否需要采用 Redis 做存储集中,亦或是通过某台服务器来完成日志汇总,都是可以根据工作量来权衡的,不过如果对性能要求较高,可能需要接入 Redis。
- Indexer 负责日志存储。在这个架构中会从 Redis 接收日志,写入到本地文件。因为架构比较灵活,如果不想用 Logstash 的存储,也可以对接到 Elasticsearch,这也就是前面所说的 ELK 的套路了。
一个 Logstash 进程可以有多个输入源,同时也可以有多个输出源,输入输出均支持过滤和改写,非常灵活。如果需要 Broker 的话,官方推荐 Redis,因为其支持订阅发布和队列两种模式,能够自行根据需求选用。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

