HBase Compaction的前生今世-改造之路
上一篇文章主要基于工作流程对compaction进行了介绍,同时说明了compaction的核心作用是通过合并大量小文件为一个大文件来减少hfile的总数量,进而保证读延迟的稳定。合并文件首先是读出所有小文件的KVs,再写入同一个大文件,这个过程会带来严重的IO压力和带宽压力,对整个系统的读请求和写请求带来不同程度的影响。
因此HBase对于compaction的设计总是会追求一个平衡点,一方面需要保证compaction的基本效果,另一方面又不会带来严重的IO压力。然而,并没有一种设计策略能够适用于所有应用场景或所有数据集。在意识到这样的问题之后,HBase就希望能够提供一种机制可以在不同业务场景下针对不同设计策略进行测试,另一方面也可以让用户针对自己的业务场景选择合适的compaction策略。因此,在0.96版本中HBase对架构进行了一定的调整,一方面提供了Compaction插件接口,用户只需要实现这些特定的接口,就可以根据自己的应用场景以及数据集定制特定的compaction策略。另一方面,0.96版本之后Compaction可以支持table/cf粒度的策略设置,使得用户可以根据应用场景为不同表/列族选择不同的compaction策略,比如:
alter ’table1’ , CONFIGURATION => {‘hbase.store.engine.class’ => ‘org.apache.hadoop.hbase.regionserver.StripStoreEngine’, … } 上述两方面的调整为compaction的改进和优化提供了最基本的保障,同时提出了一个非常重要的理念:compaction到底选择什么样的策略需要根据不同的业务场景、不同数据集特征进行确定。那接下来就根据不同的应用场景介绍几种不同的compaction策略。
在介绍具体的compaction策略之前,还是有必要对优化compaction的共性特征进行提取,总结起来有如下几个方面:
1. 减少参与compaction的文件数:这个很好理解,实现起来却比较麻烦,首先需要将文件根据rowkey、version或其他属性进行分割,再根据这些属性挑选部分重要的文件参与合并;另一方面,尽量不要合并那些大文件,减少参与合并的文件数。
2. 不要合并那些不需要合并的文件:比如OpenTSDB应用场景下的老数据,这些数据基本不会查询到,因此不进行合并也不会影响查询性能
3. 小region更有利于compaction:大region会生成大量文件,不利于compaction;相反,小region只会生成少量文件,这些文件合并不会引起很大的IO放大
接下来就介绍几个典型的compaction策略以及其适应的应用场景:
FIFO Compaction(HBASE-14468)
FIFO Compaction策略主要参考了 rocksdb的实现 ,它会选择那些过期的数据文件,即该文件内所有数据都已经过期。因此,对应业务的列族必须设置TTL,否则肯定不适合该策略。需要注意的是,该策略只做这么一件事情:收集所有已经过期的文件并删除。这样的应用场景主要包括:
1. 大量短时间存储的原始数据,比如推荐业务,上层业务只需要最近时间内用户的行为特征,利用这些行为特征进行聚合为用户进行推荐。再比如Nginx日志,用户只需要存储最近几天的日志,方便查询某个用户最近一段时间的操作行为等等
2. 所有数据能够全部加载到block cache(RAM/SSD),假如HBase有1T大小的SSD作为block cache,理论上就完全不需要做合并,因为所有读操作都是内存操作。
因为FIFO Compaction只是收集所有过期的数据文件并删除,并没有真正执行重写(几个小文件合并成大文件),因此不会消耗任何CPU和IO资源,也不会从block cache中淘汰任何热点数据。所以,无论对于读还是写,该策略都会提升吞吐量、降低延迟。
开启FIFO Compaction(表设置&列族设置)
HTableDescriptor desc = new HTableDescriptor(tableName); desc.setConfiguration(DefaultStoreEngine.DEFAULT_COMPACTION_POLICY_CLASS_KEY, FIFOCompactionPolicy.class.getName());
HColumnDescriptor desc = new HColumnDescriptor(family); desc.setConfiguration(DefaultStoreEngine.DEFAULT_COMPACTION_POLICY_CLASS_KEY, FIFOCompactionPolicy.class.getName());
Tire-Based Compaction(HBASE-7055)(HBASE-14477)
之前所讲到的所有‘文件选取策略’实际上都不够灵活,基本上没有考虑到热点数据的情况。然而现实业务中,有很大比例的业务都存在明显的热点数据,而其中最常见的情况是:最近写入到的数据总是最有可能被访问到,而老数据被访问到的频率就相对比较低。按照之前的文件选择策略,并没有对新文件和老文件进行一定的‘区别对待’,每次compaction都有可能会有很多老文件参与合并,这必然会影响compaction效率,却对降低读延迟没有太大的帮助。
针对这种情况,HBase社区借鉴Facebook HBase分支的解决方案,引入了Tire-Based Compaction。这种方案会根据候选文件的新老程度将其分为多个不同的等级,每个等级都有对应等级的参数,比如参数Compation Ratio,表示该等级文件选择时的选择几率,Ratio越大,该等级的文件越有可能被选中参与Compaction。而等级数、每个等级参数都可以通过CF属性在线更新。
可见,Tire-Based Compaction方案通过引入时间等级和Compaction Ratio等概念,使得Compaction更加灵活,不同业务场景只需要调整参数就可以达到更好的Compaction效率。目前HBase计划在2.0.0版本发布基于时间划分等级的实现方式-Date Tierd Compaction Policy,后续我们也重点基于该方案进行介绍。
该方案的具体实现思路,HBase更多地参考了Cassendra的实现方案:基于时间窗的时间概念。如下图所示,时间窗的大小可以进行配置,其中参数base_time_seconds代表初始化时间窗的大小,默认为1h,表示最近一小时内flush的文件数据都会落入这个时间窗内,所有想读到最近一小时数据请求只需要读取这个时间窗内的文件即可。后面的时间窗窗口会越来越大,另一个参数max_age_days表示比其更老的文件不会参与compaction。
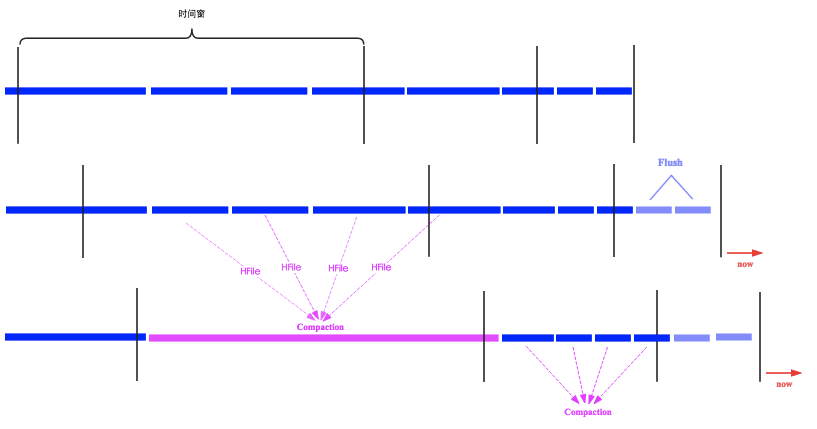
上图所示,时间窗随着时间推移朝右移动,图一中没有任何时间窗包含4个(可以通过参数min_thresold配置)文件,因此compaction不会被触发。随着时间推移来到图二所示状态,此时就有一个时间窗包含了4个HFile文件,compaction就会被触发,这四个文件就会被合并为一个大文件。
对比上文说到的分级策略以及Compaction Ratio参数,Cassendra的实现方案中通过设置多个时间窗来实现分级,时间窗的窗口大小类似于Compaction Ratio参数的作用,可以通过调整时间窗的大小来调整不同时间窗文件选择的优先级,比如可以将最右边的时间窗窗口调大,那新文件被选择参与Compaction的概率就会大大增加。然而,这个方案里面并没有类似于当前HBase中的Major Compaction策略来实现过期文件清理的功能,只能借助于TTL来主动清理过期的文件,比如这个文件中所有数据都过期了,就可以将这个文件清理掉。
因此,我们可以总结得到使用Date Tierd Compaction Policy需要遵守的原则:
1. 特别适合使用的场景:时间序列数据,默认使用TTL删除。类似于“获取最近一小时/三小时/一天”场景,同时不会执行delete操作。最典型的例子就是基于Open-TSDB的监控系统,如下图所示:
2. 比较适合的应用场景:时间序列数据,但是会有全局数据的更新操作以及少部分的删除操作。
3. 不适合的应用场景:非时间序列数据,或者大量的更新数据更新操作和删除操作。
Stripe Compaction (HBASE-7667)
通常情况下,major compaction都是无法绕过的,很多业务都会执行delete/update操作,并设置TTL和Version,这样就需要通过执行major compaction清理被删除的数据以及过期版本数据、过期TTL数据。然而,接触过HBase的童鞋都知道,major compaction是一个特别昂贵的操作,会消耗大量系统资源,而且执行一次可能会持续几个小时,严重影响业务应用。因此,一般线上都会选择关闭major compaction自动触发,而是选择在业务低峰期的时候手动触发。为了彻底消除major compaction所带来的影响,hbase社区提出了strip compaction方案。
其实,解决major compaction的最直接办法是减少region的大小,最好整个集群都是由很多小region组成,这样参与compaction的文件总大小就必然不会太大。可是,region设置小会导致region数量很多,这一方面会导致hbase管理region的开销很大,另一方面,region过多也要求hbase能够分配出来更多的内存作为memstore使用,否则有可能导致整个regionserver级别的flush,进而引起长时间的写阻塞。因此单纯地通过将region大小设置过小并不能本质解决问题。
Level Compaction
此时,社区开发者将目光转向了leveldb的compaction策略:level compaction。level compaction设计思路是将store中的所有数据划分为很多层,每一层都会有一部分数据,如下图所示:
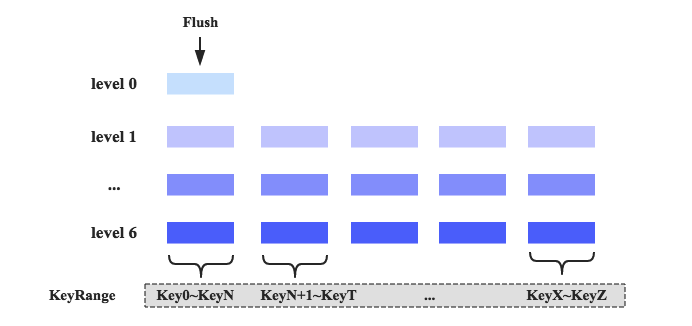
1. 数据组织形式不再按照时间前后进行组织,而是按照KeyRange进行组织,每个KeyRange中会包含多个文件,这些文件所有数据的Key必须分布在同一个范围。比如Key分布在Key0~KeyN之间的所有数据都会落在第一个KeyRange区间的文件中,Key分布在KeyN+1~KeyT之间的所有数据会分布在第二个区间的文件中,以此类推。
2. 整个数据体系会被划分为很多层,最上层(Level 0)表示最新数据,最下层(Level 6)表示最旧数据。每一层都由大量KeyRange块组成(Level 0除外),KeyRange之间没有Key重合。而且层数越大,对应层的每个KeyRange块大小越大,下层KeyRange块大小是上一层大小的10倍。图中range颜色越深,对应的range块越大。
3. 数据从Memstore中flush之后,会首先落入Level 0,此时落入Level 0的数据可能包含所有可能的Key。此时如果需要执行compaction,只需要将Level 0中的KV一个一个读出来,然后按照Key的分布分别插入Level 1中对应KeyRange块的文件中,如果此时刚好Level 1中的某个KeyRange块大小超过了一定阈值,就会继续往下一层合并。
4. level compaction依然会有major compaction的概念,发生major compaction只需要将部分Range块内的文件执行合并就可以,而不需要合并整个region内的数据文件。
可见,这种compaction在合并的过程中,从上到下只需要部分文件参与,而不需要对所有文件执行compaction操作。另外,level compaction还有另外一个好处,对于很多‘只读最近写入数据’的业务来说,大部分读请求都会落到level 0,这样可以使用SSD作为上层level存储介质,进一步优化读。 然而,这种compaction因为level层数太多导致compaction的次数明显增多,经过测试,发现这种compaction并没有对IO利用率有任何提升。
Stripe Compaction 实现
虽然原生的level compaction并不适用于HBase,但是这种compaction的思想却激发了HBaser的灵感,再结合之前提到的小region策略,就形成了本节的主角-stripe compaction。同level compaction相同,stripe compaction会将整个store中的文件按照Key划分为多个Range,在这里称为stripe,stripe的数量可以通过参数设定,相邻的stripe之间key不会重合。实际上在概念上来看这个stripe类似于sub-region的概念,即将一个大region切分成了很多小的sub-region。
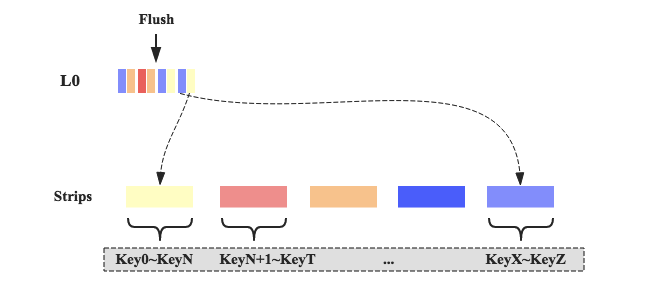
随着数据写入,memstore执行flush之后形成hfile,这些hfile并不会马上写入对应的stripe,而是放到一个称为L0的地方,用户可以配置L0可以放置hfile的数量。一旦L0放置的文件数超过设定值,系统就会将这些hfile写入对应的stripe:首先读出hfile的KVs,再根据KV的key定位到具体的stripe,将该KV插入对应stripe的文件中即可,如下图所示。之前说过stripe就是一个个小的region,所以在stripe内部,依然会像正常region一样执行minor compaction和major compaction,可以预想到,stripe内部的major compaction并不会太多消耗系统资源。另外,数据读取也很简单,系统可以根据对应的Key查找到对应的stripe,然后在stripe内部执行查找,因为stripe内数据量相对很小,所以也会一定程度上提升数据查找性能。
官方对stripe compaction进行了测试,给出的测试结果如下:
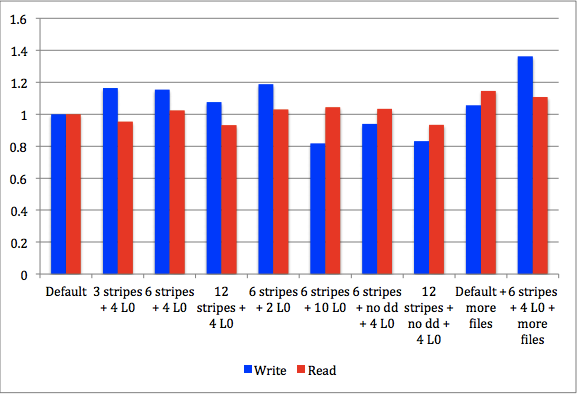
上图主要测定了在不同的stripe数量以及不同的L0数量下的读写延迟对比情况,参考对照组可以看出,基本上任何配置下的读响应延迟都有所降低,而写响应延迟却有所升高。
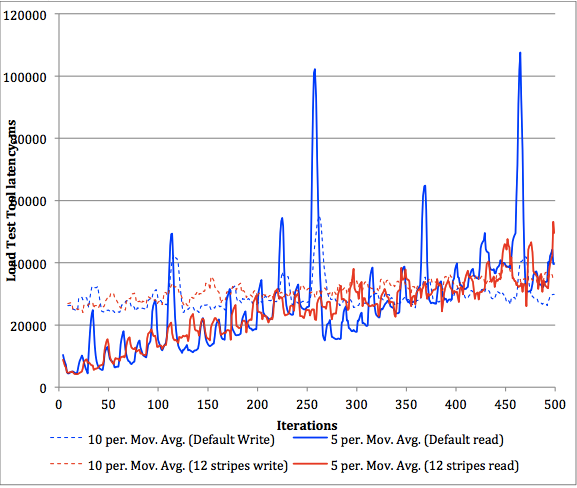
上图是默认配置和12-stripes配置下读写稳定性测试,其中两条蓝线分别表示默认情况下的读写延迟曲线,而两条红线表示strips情况下读写延迟曲线,可以明显看出来,无论读还是写,12-stripes配置下的稳定性都明显好于默认配置,不会出现明显的卡顿现象。
到此为止,我们能够看出来stripe compaction设计上的高明之处,同时通过实验数据也可以明显看出其在读写稳定性上的卓越表现。然而,和任何一种compaction机制一样,stripe compaction也有它特别擅长的业务场景,也有它并不擅长的业务场景。下面是两种stripe compaction比较擅长的业务场景:
1. 大Region。小region没有必要切分为stripes,一旦切分,反而会带来额外的管理开销。一般默认如果region大小小于2G,就不适合使用stripe compaction。
2. RowKey具有统一格式,stripe compaction要求所有数据按照Key进行切分,切分为多个stripe。如果rowkey不具有统一格式的话,无法进行切分。
上述几种策略都是根据不同的业务场景设置对应的文件选择策略,核心都是减少参与compaction的文件数,缩短整个compaction执行的时间,间接降低compaction的IO放大效应,减少对业务读写的延迟影响。然而,如果不对Compaction执行阶段的读写吞吐量进行限制的话也会引起短时间大量系统资源消耗,影响用户业务延迟。HBase社区也意识到了这个问题,也提出了一定的应对策略:
Limit Compaction Speed
该优化方案通过感知Compaction的压力情况自动调节系统的Compaction吞吐量,在压力大的时候降低合并吞吐量,压力小的时候增加合并吞吐量。基本原理为:
1. 在正常情况下,用户需要设置吞吐量下限参数 “hbase.hstore.compaction.throughput.lower.bound”(默认10MB/sec) 和上限参数 “hbase.hstore.compaction.throughput.higher.bound”(默认20MB/sec),而hbase实际会工作在吞吐量为 lower + (higer – lower) * ratio的情况下,其中ratio是一个取值范围在0到1的小数,它由当前store中待参与compation的 file 数量决定,数量越多,ratio越小,反之越大。
2. 如果当前store中hfile的数量太多,并且超过了参数 blockingFileCount,此时所有写请求就会阻塞等待compaction完成,这种场景下上述限制会自动失效。
截至目前,我们一直都在关注Compaction带来的IO放大效应,然而在某些情况下Compaction还会因为大量消耗带宽资源从而严重影响其他业务。为什么Compaction会大量消耗带宽资源呢?主要有两点原因:
1. 正常请求下,compaction尤其是major compaction会将大量数据文件合并为一个大HFile,读出所有数据文件的KVs,然后重新排序之后写入另一个新建的文件。如果待合并文件都在本地,那么读就是本地读,不会出现垮网络的情况。但是因为数据文件都是三副本,因此写的时候就会垮网络执行,必然会消耗带宽资源。
2. 原因1的前提是所有待合并文件都在本地的情况,那在有些场景下待合并文件有可能并不全在本地,即本地化率没有达到100%,比如执行过balance之后就会有很多文件并不在本地。这种情况下读文件的时候就会垮网络读,如果是major compaction,必然也会大量消耗带宽资源。
可以看出来,垮网络读是可以通过一定优化避免的,而垮网络写却是不可能避免的。因此优化Compaction带宽消耗,一方面需要提升本地化率(一个优化专题,在此不详细说明),减少垮网络读;另一方面,虽然垮网络写不可避免,但也可以通过控制手段使得资源消耗控制在一个限定范围,HBase在这方面也参考fb也做了一些工作:
Compaction BandWidth Limit
原理其实和Limit Compaction Speed思路基本一致,它主要涉及两个参数: compactBwLimit和 numOfFilesDisableCompactLimit,作用分别如下:
1. compactBwLimit:一次compaction的最大带宽使用量,如果compaction所使用的带宽高于该值,就会强制令其sleep一段时间
2. numOfFilesDisableCompactLimit:很显然,在写请求非常大的情况下,限制compaction带宽的使用量必然会导致HFile堆积,进而会影响到读请求响应延时。因此该值意义就很明显,一旦store中hfile数量超过该设定值,带宽限制就会失效。
写在最后
Compaction对于HBase的读写性能至关重要,但是它本身也会引起比较严重的写放大,本文基于此介绍了官方社区对Compaction进行的多种优化方案。希望大家在看完这些优化方案之后可以更好地理解Compaction!
正文到此结束
热门推荐









相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

