揭开 Heron 性能面纱
Heron 自去年2015年6月公布出来,给整个业界注入了一缕新的活力, 随即我们团队, 仔细阅读了Heron 的论文, 发表 了一片关于 《深入浅出Heron》 (国内被墙的话,可以查看 http://www.blogchong.com/post/117.html )。 其中Topology Master、backpressure到Two-threaded approach instance,Stream Manager等概念还是非常有创新。
整体Heron 的架构设计就是Storm-on-Mesos 的架构。
这篇博文分为2部分
- 测试结果和测试过程
- Heron 性能分析
测试结果和测试过程
今年5月25号, Heron开源了他们的源码, 整个业界对Heron 的性能都非常感兴趣,我们花了3周的时间,完成heron的整个测试。
性能测试结果
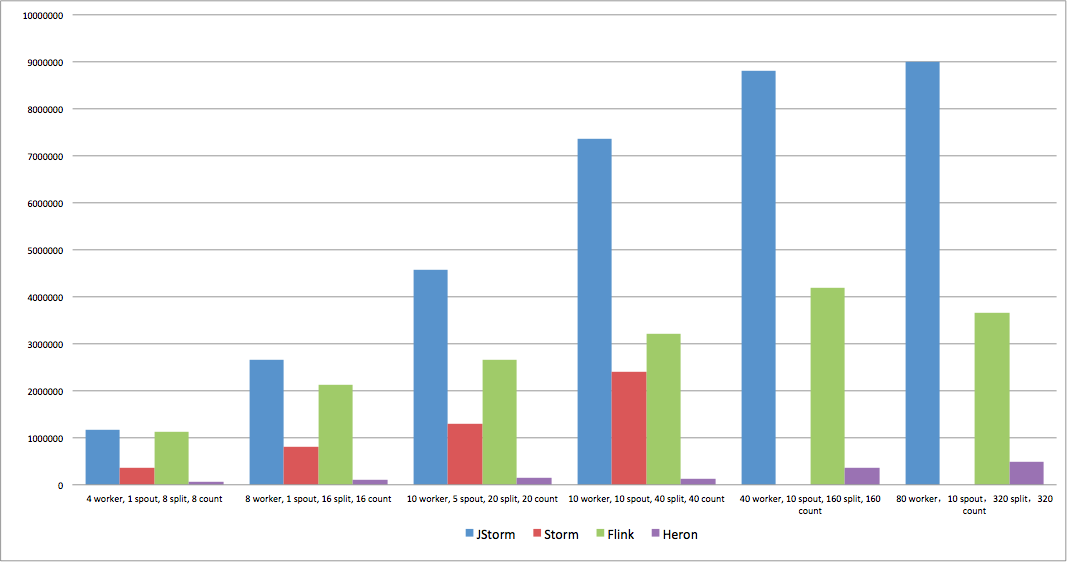
使用FastWordCount
FastWordCount 测试用例 分为3个stage spout-> split > count, 使用流计算中最常用的shuffler和fieldgrouping 方式。
使用WordCount
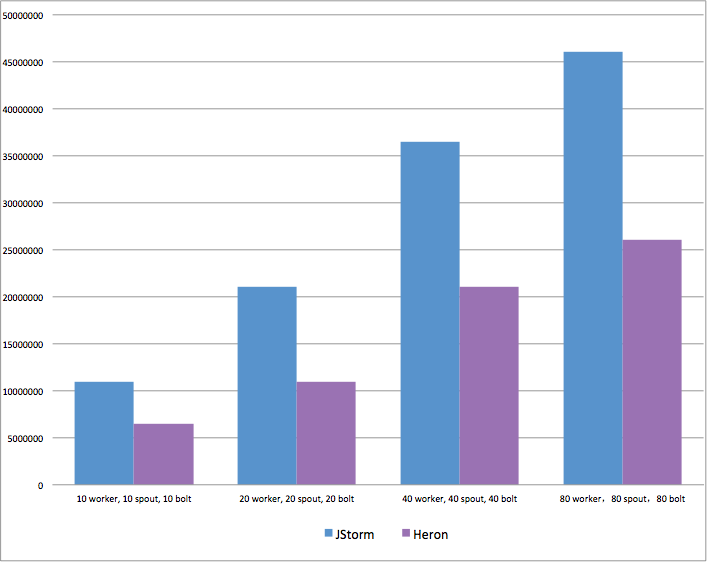
WordCount 是twitter 号称是storm 10倍性能的 官方测试用例 , 分为2个stage, spout -> count, 使用shuffle模式,并按照twitter给出的并发配置进行测试。
测试环境
- 10 台a8, 32 核/128g
- os: redhat rhel 7.2
- jdk: jdk8
- hdfs: 2.6.3
- mesos: 0.25.0
- aurora: 0.12.0
- jstorm: 2.2.0
- heron: 0.14.0 并打上heron最新性能优化patch
- flink: 1.0.3
- storm: 1.0.2
- worker/container 内存设置4g
测试过程
- 第一次跑,heron性能极差, 10个container只有2w qps, 咨询twitter, 告知,大量触发反压,可以打个patch 调整反压策略
- 第二次跑(打上patch后),10个container可以到10多万, 但其实和storm相比,也是差很多, 咨询twitter 人员, 告知一个container内部task太多,容易发生反压
- 第三次跑(修改container内部task数), 10个container 跑到20w qps, 但我们依旧不满意,咨询twitter, 他们告知 他们也就只能跑20w qps, 并且告诉 一个很大问题, container内部的stream-manager的瓶颈是50w qps, 也就是一个container所有内部通信和外部通信的总和上限就是50w。
分析
后面的分析,主要是分析Heron 最大的噱头 “10 倍storm性能” & “减少3倍storm资源”, Heron 有很多漂亮的设计, 这里不赘述, 读者可以自行阅读我们之前的文章。
性能分析
- heron 一直号称是storm 10倍性能, 但heron 对比的对象是storm 0.8.2, 这是3年前的storm,是上一代的storm, 而最新版storm 1.0.2 早已经是storm 0.8.2 的十倍性能。
- heron在性能上存在2个致命缺陷
- 失去了整个业界性能优化很大的一个方向, 流计算图优化。其核心思想就是让task尽量绑在一个进程中, 这样task之间的数据,可以直接走进程内通信,无需反序列化和序列化。
- 为了提高稳定性, heron将每个task 独立成为一个进程, 则会产生一个新的问题,就是task之间的通信都不会有进程内通信, 所有task通信都是走网络, 都要经过序列化和反序列化, 引入了大量额外的计算.
- 如果想要图优化, 则heron必须引入一层新的概念, 将多个task 链接到一个进程中, 但这个设计和heron的架构设计理念会冲突
- 每个container 的stream manager 会成为瓶颈, 一个container 内部的所有task 的数据(无论数据对外还是对内)通信都必须经过stream manager, 一个进程他的网络tps是有上限的, 而stream-manager的上限就是50w qps, 则表示一个container的内部通道和外部通道总和就是50w qps. 大家都必须抢这个资源。
- 原来的一次网络通信, 现在会变成3次网络通信, task -》 当前container的streammanager -》 目标container的stream manager -》 目标task
资源分析
Heron 突出的 “省资源3倍”, 这个论点和3年前的storm相比,确实是可以这么说,这个说法的背后技术:
- 反压;过去storm 应用,为了应对每天的高峰, 必须要多申请资源, 否则当流量高峰来临时, worker会爆掉。
- 大集群部署,利用大集群的削峰填谷能力和资源隔离能力。
- 对每个task的资源做限定, 限定cpu 用多少, 内存用多少,按需使用,无需超量申请。
但今天的storm已经今非昔比,而jstorm更是不一样了。 jstorm反压早就做到了第三版, 当下游数据发生堆积时, 上游spout早就做限流降级, 应用无需申请超量的资源。
今天jstorm-on-yarn/jstorm-on-docker, jstorm-on-yarn 已经上线,就是在大集群上部署多个逻辑集群, 让大集群削峰填谷和资源隔离都非常成熟。
jstorm 0.9.0/storm0.9.5 开始就有了task粒度资源调度器,就是task按自己需要,申请多少cpu和多少内存就分配多少内存。但jstorm从0.9.5 开始,调度的资源从task粒度恢复到worker粒度, 原因是:
- 集群跑一段时间后,容易出现碎片, 即有的机器上有cpu slot但没有内存 slot, 有的机器上有内存slot但没有cpu slot
- 业务方很少遵守task 粒度去申请资源,反而偏爱worker粒度,简单粗暴方式。
- 业务方有时超量申请资源, 只需要10个cpu slot,但却申请20个cpu
最终jstorm的方案是, 资源的粒度是到worker级别,但每台机器上配置动态监测, 实时根据负载情况调整自己的资源池策略, 很有效解决上述问题。
另外Heron 资源上其实会引入1个小问题, 单个heron container会比单个jstorm/storm worker更消耗资源。
假设3个task运行在一个worker或container中,每个task 需要2g内存, 如果是jstorm或storm, 可能5g 内存就够了, 每个task之间可以临时share一下, 而heron container 则需要7g 甚至8g, 每个task 都需要2g,而且不能相互share, 另外一个container中还有streammanager/metricsmanager, 他们都需要内存。
原本worker级别的公共线程,在heron中现在需要在每个task进程中都配置上, 比如netty进程池,心跳线程, metrics 线程等等, 这些都在消耗cpu。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

