计算机也可以看“视频”,理解“视频”
联合编译: 高斐 章敏
摘要
我们将在文中介绍一种用于视频中动作检测的端对端方法,该方法用于学习直接预测动作的瞬时改变。我们认为,动作检测是一个对运动目标进行观察并细化假设的过程:观察视频中每一个动作变化瞬间,细化关于一个动作将何时发生的所有假设。基于该观点,我们将提出的模型视为一个基于递归神经网络结构的代理人程序,该代理人程序与视频进行交流互动。代理人程序观察视频帧序列,决定下一步观察哪里,何时对运动目标进行动作预测。由于反向传播算法在这种不可微的环境下不能得到充分利用,我们使用REINFORCE算法学习智能体的决策策略。我们的模型运用THUMOS’14和ActivityNet数据集,仅仅观测一小部分(2%或更少)视频帧序列就获得了state-of-the-art结果。
1 引言
在计算机视觉研究领域,要对现实世界中历时长的视频进行动作检测是一个颇具挑战性的科研难题。众多算法必须不仅能够推理得出一个动作是否会在视频中发生,也要能够预测该动作何时会发生。现有的文献[22,39,13,46]均采用构建帧级别分类器,在多个时间标尺下,详尽地在一个视频中运行这些分类器,并且运用后期处理方式,如时间先验和极大值抑制。然而,在精确度与计算效率方面,该间接动作定位模型不甚令人满意。
我们在本文中介绍一种端对端的动作检测方法,该方法能够直接推理得出动作的瞬时变化。我们的主要观点为,动作检测是一个具有连续性和惯性的观察细化过程。通过观察单个或多个帧序列,能够人为地对动作何时发生做出假设。然后,我们可以重复观察一些帧序列证实作出的假设,快速确定动作将要发生的位置(例如,图1所示挥动棒球棒这一动作)。我们能够有顺序地决定将目光投向哪个方向,如何采用与已有算法相比较为简化的搜索方法,来细化动作预测假设,获得精确的动作位置信息。
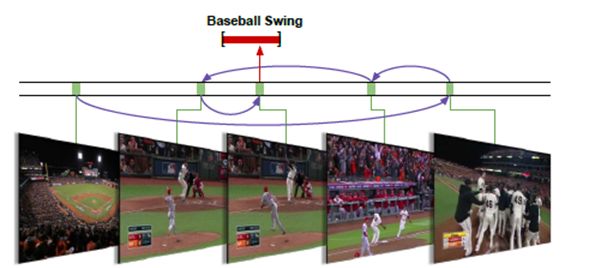
图1:动作检测是一个观察与细化的过程。有效地选取帧观察序列有助于我们快速确定何时挥动棒球棒。
基于上述观点,我们提出一个单一连续性模型,该模型需要一个历时较长的视频作为输入信息,输出检测所得的动作实例的瞬时变化。我们将提出的模型制定为一个代理人程序,该代理人程序可以学习策略,关于动作实例形成有序的假设,并对作出的假设进行细化。在一个递归神经网络结构中运用这一观点,我们采用反向传播算法与REINFORCE算法[42]相结合的方法全面端对端训练所提出的模型。
我们的模型是从一些研究文献中汲取灵感的,这些文献运用REINFORCE算法来学习对图像分类与加字幕的空间观测策略[19,1,30,43 ]。然而,动作检测仍面临另一个挑战,即如何处理一个结构化检测输出结果的变量集合。为了解决这一难题,我们提出一个既能够决定运用哪一个帧观测下一个潜在动作,也能够决定何时对动作变化作出预测。此外,我们介绍了一种奖励机制,使得计算机能够学习这一策略。就我们所知,这是首个学习视频动作检测的端对端方法。
我们认为,我们的模型具备有效推理动作瞬时变化的能力,并且能够运用THUMOS’14和ActivityNe数据集获得state-of-the-art性能。此外,我们的模型能够学习决定使用哪一个帧进行观测或实时观测,它也具备仅观测一部分(2%或更少)帧序列,便可学习决策策略的能力。
2 相关研究文献
视频分析与活动识别领域具有悠久的研究历史[20,449,2,31,17,8,10,112,50]。我们参考Poppe[24]与Weinland等人[40]的研究对该领域进行研究。这里我们将回顾近来有关瞬时动作检测的文献。 瞬时动作检测 该研究方向的典型研究成果当属Ke等人[14]。Rohrbach等人[27]与Ni等人[21]在一个固定摄像机厨房环境下,以手和物体为特征分别检测娴熟的烹饪动作。与我们当前研究更为相关的是无约束无修改设置的THUMOS’14动作数据集。Oneata等[22],王等[39],Karaman等[13],及Yuan等[46]在滑动窗口框架中使用密集轨迹,帧级别CNN特征,和/或声音特征检测瞬时动作。Sun等[34]基于网络图像提高检测性能。Pirsiacash与Ramanan[23]对复杂的动作建立语法结构,并及时检测子成分。
空间-时间动作检测方法也得到了发展。在“无约束”的网络视频环境下,发展这些方法需要有大量关于空间-时间动作假说的文献[44,16,36,9,7,45,41]。动作检测更为宽泛的检测场景分析也是一个活跃的研究领域。Shu等[32]在人群中进行推理,Loy等[18]运用多台摄像机场景进行推理,Kwak等[15]遵循基于二次编程的实例化原则进行推理。这些研究存在一个共同点,即在时间维度内典型地运用基于滑动窗口的方法,在空间-时间动作假说或人类轨迹的基础上进行推理。此外,这些研究是运用经过修剪或约束的视频剪辑开展来的。与之形成鲜明对比,我们运用无修剪,无约束的视频剪辑完成空间动作检测任务,提供了一种有效的方法来确定使用那些帧序列进行观测。
端对端检测我们直接推理动作的瞬时变化的研究目的与关于从整幅图像到物体变化的物体检测的研究工作具有相同的哲学意义[29,35,5,6,26,25]。相反,现有的动作检测方法主要运用详尽的滑动窗口方法和后期处理程序得出动作实例[22,39,13,46]。就我们所知,我们的研究工作是首个采用端对端框架学习瞬时动作检测的。
学习特定任务策略 我们从近期使用REINFORCE算法来学习特定任务策略的途径中获得研究灵感。Mnih等[19]学习图像分类的空间注意策略,Xu等[43]学习图像字幕生成。在非视觉化任务中,Zaremba等[47]学习REINFORCE算法神经图灵机策略。我们采用的方法是建立在这些研究方向之上,运用强化法学习处理动作检测任务的策略。
3 研究方法
我们的研究目的是运用一个长的视频序列,输出任意一个指定动作的实例。图2所示为我们的模型结构。我们将这个模型制定为一个REINFORCE算法代理人程序,该代理人程序与视频在特定时间段内进行交流沟通。代理人程序接收一系列视频帧序列V={v 1 ,…,v T }作为输入信息,能够观测固定比例的帧序列。该模型必须能够有效地利用这些观测结果,或帧观测结果,来推理动作的瞬时变化。
3.1结构
我们提出的模型由两个主要成分构成:一个观测网络(见3.1.1),一个递归网络(见3.1.2)。观测网络为视频帧的视觉表征编码。递归网络有序地加工这些观测结果,并决定运用哪一个帧序列观测下一个动作,何时对动作变化作出预测。我们现在将更为详细地描述这两个组成成分。之后在3.2,我们将阐释如何运用端对端的方法,结合反向传播算法与强化手段训练我们提出的模型。
3.1.1 观测网络
如图2所示,观测网络f 0 ,用参数θ 0 表示,在每一个时间步长中观察单一的视频帧。在该观测网络中,用特征向量O n 为帧编码,将该特征向量作为递归网络的输入信息。
重要的是,O n 表示在视频中何处进行观测及观测什么的编码信息。因而,观测网络的输入信息由观测的正常时间位置与相对应的视频帧构成。
观测网络结构受到文献[19]中涉及到的空间观测网络启发。L n 和v ln 被映射到一个隐蔽的空间内,然后,与一个全面的连接层相结合。在我们的实验中,我们从一个经过优化的VGG-16网络中提取得到f c7 特征。
3.1.2 递归网络
递归网络f h ,用参数o h 表示,是学习代理人程序的核心网络结构。正如可以在图2中观测到的,在每一个时间步长n中,该网络的输入信息为一个观测特征向量o n 。该网络的隐蔽空间h n ,o n 与先前隐蔽空间h n-1 ,为动作实例构建时间假说。
在代理人程序推理的过程中,每一个时间步长内输出三种信息:候选检测结果d n ,标志是否产出预测结果dn的二进制指示参数p n ,及确定观测下一个动作的帧的时间位置l n+1 。
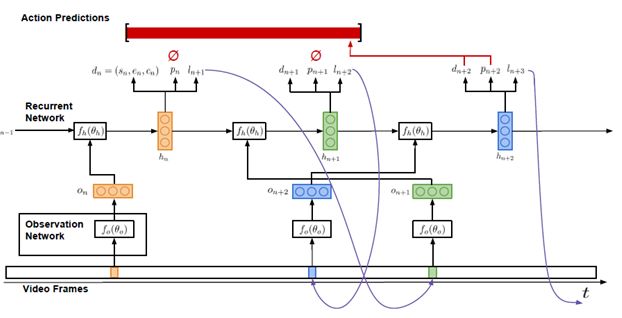
图2:该模型的输入信息为一系列视频帧序列,输出信息为一系列动作预测结果。
3.2 训练
我们的最终研究目的是学习输出一系列动作检测结果。为了实现这一目标,我们需要在代理人程序的递归网络中的每一步训练这三种输出信息:候选检测结果d n ,预测指示值p n ,及下一个观测位置l n+1 。鉴于对长视频中瞬时动作注释的检测,训练这些输出结果面临着设计合适的损失与奖励函数,处理不可微模型组成成分。我们运用标准的反向传播算法来训练d n ,运用强化手段来训练p n 和l n+1 。
3.2.1 候选检测结果
运用反向传播算法训练候选检测结果,以确保每一个候选检测结果的正确性。由于每一个候选结果都代表代理人程序关于动作作出的假设,不论每一个候选结果最终是否得到输出,我们都希望确保该结果最为正确。这便要求在训练过程中将每一个候选结果与一个ground truth实例相匹配。代理人程序应当在视频中最接近当前位置的地方对动作实例作出假设。这有助于我们设计出一个简单却有效的匹配函数。
与ground truth 相匹配 如果存在一个由递归网络中N个时间步长得出的候选检测结果集合D={dn|n=1,…,N}和ground truth 动作实例g1,…,M,那么每一个候选检测结果都将于一个ground truth实例相匹配;如果M=0,那么没有匹配结果。
我们定义匹配函数为
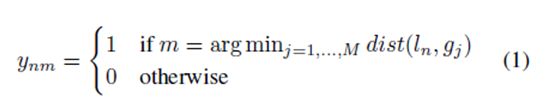
换句话讲,如果在时间步长n内,代理人程序的时间位置ln比任何一个ground truth实例都接近g m ,候选结果dn与ground truth g m 匹配。
损失函数 一旦候选检测结果与ground truth实例得以匹配,我们运用集合D来优化一个多重任务分类与定位损失函数:
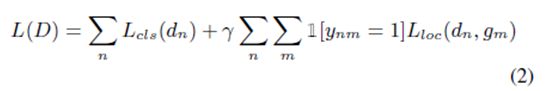
公式中的分类术语 是一个关于检测信度c n 的标准交叉熵损失值,如果检测结果d n 与一个ground truth实例相匹配,那么信度接近1;否则,信度为0。
我们运用反向传播算法优化该损失函数。
3.2.2 序列的观测与输出
观测定位与预测指数输出结果是我们的模型中不可微的组成成分,无法用反向传播算法训练这些输出结果。然而,强化手段是一种强有力的方法,能够实现在不可微的环境下进行学习。下文我们将简略描述这种强化手段。之后,我们介绍一种与强化手段相结合的奖励函数,学习观测与预测输出序列的有效策略。
强化手段 存在Α,一个动作序列空间,和一个Pθ(a),强化目标可以表示为
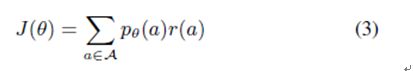
在该公式中r(a)为分配给每一个可能动作序列的奖励,J(θ)为每一个可能动作序列分布结果的预期奖励。我们希望学习网络参数θ,该参数使每一个位置序列和预期指示输出结果的预期奖励实现最大值。
目标梯度为
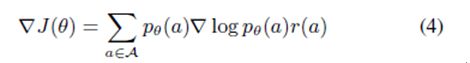
由于可能动作序列具有高维度空间,这将导致一个特殊的优化问题。强化手段通过使用蒙特卡洛样本和近似梯度方程学习网络参数,以解决这一问题。
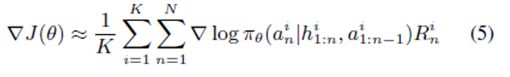
由于一个代理人程序与周围环境进行交流沟通,在我们的视频中,π θ 为代理人程序的策略。在每一个时间步长n内,a n 是该策略的当前动作,h 1:n 为包括当前状态在内的过去状态的历史记录,a 1:n-1 为过去动作的历史记录。通过在其所处环境中,经营一个代理人程序的当前策略,以获得K互动序列,最终计算得出近似梯度。
根据该近似梯度,强化手段学习模型参数。导致高未来奖励的动作的概率在不断增长,那些导致低奖励的概率将下降。可以运用反向传播算法对模型参数实施实时更新。
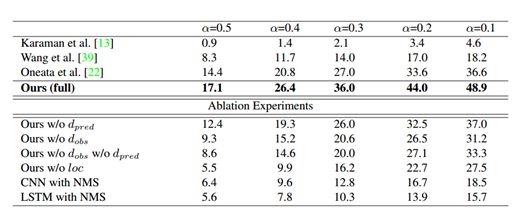
图1:THYMOS`14上的行动检测结果。与THUMOS`14挑战榜排行前3的性能进行比较,并且展示了消融模型。mAP报道了不同的交叉联合(intersection-over-union/IOU)阈值α
奖励函数 训练强化手段要求设计出一个合适的奖励函数。我们的目标是学习位置与预测指示输出结果的策略,这些输出结果将产生高回忆和高精确度的动作检测结果。因而,我们介绍一种能够使真肯定检测结果最大化,而使假肯定检测结果最小化的奖励函数:

所有的奖励都是在Nth(最后)时间步长时提供的,且n<N时为0,因为我们想找到一个可以共同产生高整体检测性能的方法。M是正确标注(ground truth)行为实例的数量,并且Np是代理发出预测的数量。N+是正的正样本(positive predictions)预测数量,N-是最小正的负样本(false positive)预测数量,并且R+和R-分别是每一个预测的正奖励和负奖励。如果一个预测与正确标注的重叠比阈值大,且比其他所有的预测还高,那么该预测就是正确的。为了鼓励代理人不过于保守,当视频包含正确标注实例(M > 0),但该模型没有发出任何预测(NP = 0)时,我们提供一个负面的奖励Rp。
我们使用有REINFORACE的函数训练位置和预测指标输出,并学习观测和排放政策(emission policies)以优化行动检测。
4.实验
我们在THUMOS`14和ActivityNet两个数据集评估了我们的模型。结果显示,我们的端对端的方法确保了模型可以最大幅度的在两个数据集产生最好的结果。此外,帧的学习策略即有效又高效;当观测到的视频帧只有2%或更少的时,模型达到了这些结果。
4.1实施细节
对于每一个行动级别我们都学习了1-vs-all模型。在观测网络中,我们使用了VGG-16网络优调数据集,以便从观测的视频帧中提取视觉特征。FC7-layer特征被提取并嵌入帧的时间位置到1024维的观测向量。
对于递归网络,我们使用了一个3层LSTM网络(在每一个层都有1024个隐藏单元)视频在THUMOS`14向下采样到5fps,在ActivityNe向下采样到1fps,并且在50帧的序列中进行。代理被给予了对于每个序列固定数量的观测,我们实验中代表性的数量是6。在视频序列中,所有的时间位置被归一化成[0,1]。任何预测重叠或交叉序列的边界都会被融合到一个简单的联盟规则。我们学习256序列中极小的一部分,并且在优化时使用RMSProp模拟预参数学习率(the perparameter learning rate)。其它的超参数通过交叉验证(cross-validation)来学习。序列的系数包含了每一个极小部分(mini-batch)的正实例,它是阻止模型过渡保守的一个非常重要的超参数。大概三分之一到一半的正实例被代表性的使用。
4.2.THUMOS`14数据集
THUMOS`14的行动检测任务包括20类运动,且表1显示了在这个数据集上的结果。因为该任务只包括数据集中101类动作的其中20类,我们第一次粗过滤了这些类测试视频的整个集,用视频水平的平均值池化类概率——每300帧计算一次(0.1fps)。我们报道了不同IOU阈值的αmAP,并与THUMOS`14挑战榜排名前3的性能进行了比较。所有这些方法计算密集的轨迹和/或时间窗口的CNN特征,并使用一个非最大抑制滑动窗口的方法获得预测。仅使用密集的轨迹,[使用时间窗口结合密集的轨迹和CNN特征,以及使用有着视频水平CNN分类预测的密集轨迹的时间窗口。
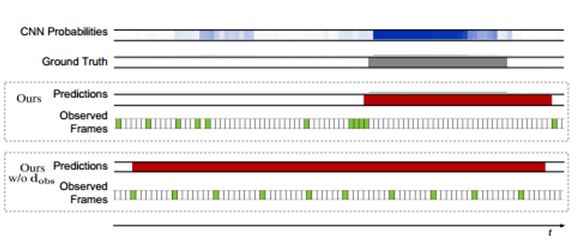
图片3:将我们的w / odobs描述与所有的模型进行比较。参考图5中图形结构的说明
和配色方案。每个模型的观测帧用绿色显示,预测程度用红色显示。允许模型选择要观测的帧,以确保行动边界上所需的分辨率。
我们的模型优于所有在α值处现存的方法。随着α的减少,相对利润率增加了,这表明我们的模型更频繁地预测接近于正确标注情况的行动,即使不精确定位的情况相。我们的模型使用它的学习观测策略进行到视频帧的2%时就实现了该结果。
消融(Ablation) 实验. 表1也显示了消融实验的结果,分析不同模型组件的贡献。消融模型如下:
· 我们的w/o dpred 移除预测指标输出。在每一个时间步长的候选检测都被发出,并与非极大值抑制合并。
· 我们的w/o dobs 移除了位置输出指标(下一个要观测哪一个地方)。观测不再是由均匀采样相同总数的观测决定。
· 我们的w/o dobs w/o dpred 移除了预测指标和位置预测输出
· 我们的 w/o loc移除 位置回归。所有发射检测都是训练集的中等长度,并集中在目前观测到的帧。
·有 NMS 的 CNN 移除了时间行动边界的直接预测。我们观测网络中VGG-16网络的预-帧类概率,是在多个时间尺度上密集获得的,并且聚合了非最大抑制,类似于现有的工作。
由于大量的正的负样本(false positives),相比于整个模型我们的w/o dpred获得了更低的性能。我们的w/o dobs同样更低效,因为均匀采样没有提供足够的分辨率来定位动作边界(图3)。有趣的是,移除dobs相比于比移除dpred对模型的损害更大,这突出了观测策略的重要性。如想象的一样,移除我们的w/o dobs和w/o dpred的输出进一步降低了性能。我们的w/o loc在α=0.5时性能最差,甚至低于CNN的性能,这反映出了时间回归的重要性。CNN减少相对差异,以及当我们减少α时的翻转,暗示出模型仍然检测出了行动大概的位置,但精确定位的影响。最终,有NMS的CNN相比于所有的消融模型(除了我们的w/o loc模型)达到了最低的性能,量化我们对于端对端框架的贡献。使用稠密轨迹和的ImageNet 预训练CNN特征,它的性能同样在除了更低的范围内。这表明,另外结合运动为基础的特征,将进一步提高我们模型的性能。
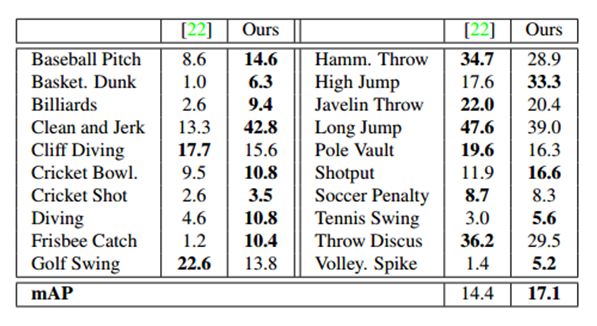
表2:在IOU α=0.5时,THUMOS`14的Per-class breakdown(AP)。
作为额外的基线,我们在LSTM的顶部执行了NMS,一个标准的时间网络,会产生帧级别的流畅性和一致性。尽管增加了更大的时间一致性,有NMS的LSTM相比于有NMS的CNN有着更低的性能。主要的原因可能是增加帧级别类概率的时间流畅性(精准定位时间边界所需要的),对于行动情况检测任务来说实际上是有害的,而不是有益的。

图4:THYMOS`14上的预测动作情况实例。每一行显示在检测动作的时间范围内,或只是在外面的采样帧。褪色的帧显示检测外的位置并说明了定位能力。
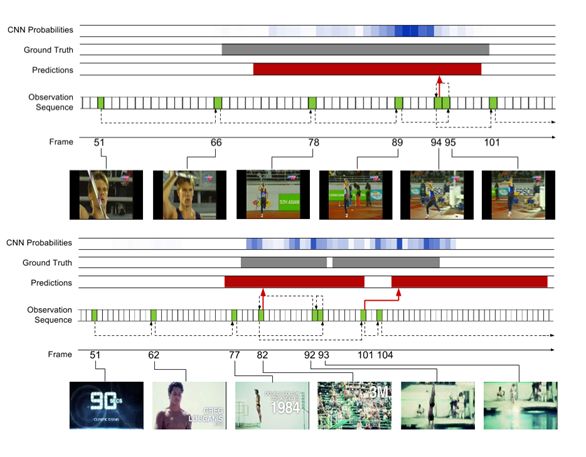
图5:THUMOS`14的学习观测策略实例。上面显示了掷标枪的例子和底部显示了潜水的例子。观测到的帧的颜色为绿色并用帧索引标记。红色表示预测范围,灰色表示正确的标示。为了参考,我们还展示了使用在我们观测网络中来自于VGGNet的帧水平的CNN概率;高强度表示更高的概率,并提供对类的帧级信号的洞察。虚线箭头表示观测序列,红色箭头指示发出预测的帧。
最终,我们实验了不同数量的观测前视频序列,如4,8和10.在该范围中,检测的性能没有实质性的不同。这是与其他使用在CNNs最大池化进行动作识别的工作一致,突出学习有效帧观测政策的重要性。
预-类分解(per-class breakdown).表2显示了我们模型的预-类AP分解,并且与THUMOS`14排行榜最好的性能进行比较。我们的模型产生20个类中的12个类。值得注意的是,它显示了一些数据集中最具挑战性的类表现出了很大的改善,如篮球,跳水,和接住飞盘。图4显示我们模型预检测的实例,包括这个来自挑战性类的检测。模型在行动程度整体合理化的能力,确保了它可以推测时间边界(甚至在帧是具挑战性的时候):例如,类似姿势和环境,或在第二个潜水的例子中场景突然变化。
观测策略分析.图5显示了我们模型学习的观测实例,以及伴随的预测。为了参考,我们还展示用于我们观测网络中VGGNet的帧水平的CNN概率,以提供行动帧水平信号的认知。上面是一个 掷标枪的例子,一旦人开始奔跑,该模型就开始进行更频繁的观测。接近行动的端边界,它退一步以完善其假设,然后在移动之前发出一个预测。下面潜水的例子是一个具有挑战性的情况下,其中两个动作实例发生的非常快速连续。而帧水平CNN的概率的强度超过序列,使得用标准滑动窗口的方法来处理变得非常困难,我们的模型能够分辨两个 单独的实例。该模型再次采取步骤向后完善其预测,包括一次(帧93)运动非常模糊,使得它很难从其它的帧中辨别出来。然而,预测在某些方面比正确标注要长,并且向上观测第二个情况的第一个帧(帧101),该模型立即发出的预测可媲美长于第一个帧,但持续时间稍。这表明,该模型可能学习时间的先验,同时极大受益,在这种情况下它过于强大。
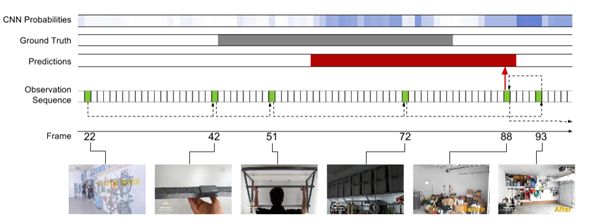
图6:ActivityNet上工作子集的学习观测策略实例。行动是组织箱。参考图5图形结构和色彩方案的解释。
4.3.ActivityNet数据集
ActivityNet动作检测数据集由849小时内未修剪的68.8小时的时间注释组成,无约束的视频。每个视频有1.41个动作实例,且每一个类有193个实例。表3和4分别显示了每个类和mAP在ActivityNet的子集“运动”和“工作,主要工作”的性能。并且超参数在训练集上进行交叉验证。

表3:IOU α=0.5时,ActivityNet Sports子集上的Per-class breakdown和mAP。
我们的模型优于现存的工作,它的基础是是通过大量的差数,结合密集轨迹,SIFT,和ImageNet-预训练CNN特征。它优于Sports子集21类中13类,和Work子集15类中10类。在工作子集上的改进是特别大的。这是部分归因于工作活动通常是不太明确的,并有较少的歧视性运动。图6 Organizing Boxes行动的训练实例中,在较弱的地方这是显而易见的——更扩散的帧水平CNN行动概率。而这给依靠后处理的方法就造成了一个挑战,我们的模型直接推理作用程度,确保它能够产生强烈的预测。
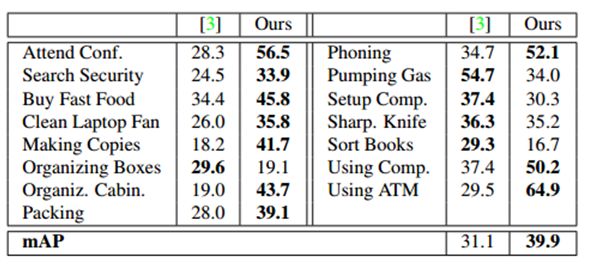
表4:IOU α=0.5时,ActivityNet Work子集上的Per-class breakdown和mAP。
5.结论
总之,我们已经介绍了一个针对视频中动作检测的终端到终端的方法,直接学习预测动作的时间界限。我们的模型在THUMOS`14和ActivityNet行动检测数据集上实现了最佳性能(只看一小部分的帧)。未来的工作方向是扩展我们的框架,学习联合时空观测策略。
哈尔滨工业大学李衍杰副教授的点评:在计算机视觉研究领域,对历时较长的视频进行动作检测是一个颇具挑战性的研究难题。这篇论文介绍了一种端对端的动作检测方法,该方法能够推理出每个时刻的动作检测的范围。动作检测是一个连续的反复的观察细化过程。我们人类能够通过观察单个或多个帧序列,对动作何时发生做出假设,从而略过一些帧迅速地缩小行动检测的范围,决定应该看哪些帧以及是否要改进自己的假设来增加动作检测的定位精度,从而避免了穷举式搜索。基于这种直观思想,本文模仿人的这种能力将一些帧序列作为输入,在观测神经网络和递归神经网络学习训练的基础上,得到了每个时刻动作检测范围,从而有助于提高动作检测的效率。在该方法中,将整个网络分为观测神经网络和递归神经网络,观测网络使用了已有的VGG-16网络,而递归网络则模仿人的假设预测定位过程分别使用了BP反向传播算法和REINFORCE算法来进行学习训练,最终通过实验验证了算法的有效性。
PS : 本文由雷锋网 (搜索“雷锋网”公众号关注) 独家编译,未经许可拒绝转载!
如需本文作多了解,请访问原文链接 细节
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

