Google Deepmind大神David Silver带你认识强化学习
Google Deepmind大神David Silver带你认识强化学习
引言:强化学习(Reinforcement learning)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。

David Silver在2013年加入Google DeepMind,是小组中AlphaGo项目的主程序员,也是 University College London的讲师。
| 背景
强化学习(Reinforcement learning)灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法具有普适性,因此在其他许多领域都有研究,例如博弈论、控制论、运筹学、信息论、模拟优化方法、多主体系统学习、群体智能、统计学以及遗传算法。
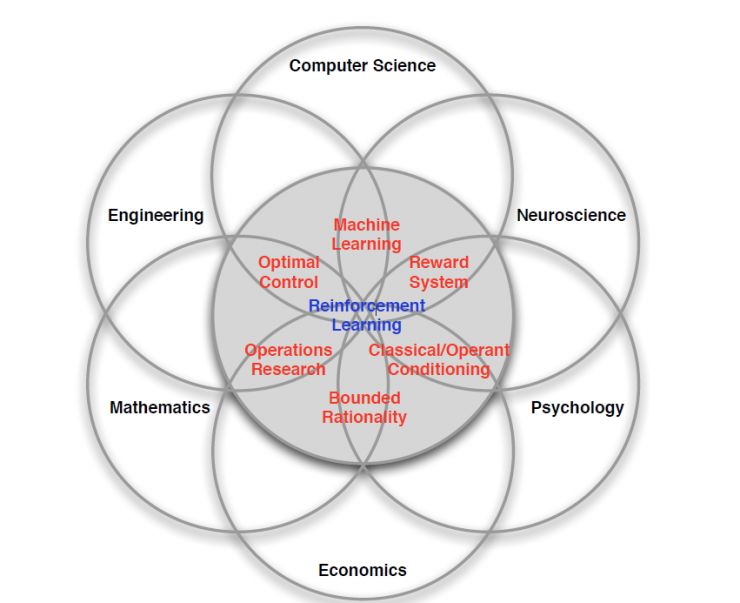
强化学习也是多学科多领域交叉的一个产物,它的 本质就是解决“决策(decision making)”问题 ,即学会自动进行决策。其在各个领域体现不同:
在计算机科学(Computer science)领域体现为机器学习算法;
在工程(Engineering)领域体现在决定序列行为(the sequence of actions)来得到最好的结果;
在神经科学(Neuroscience)领域体现在理解人类大脑如何做出决策,主要的研究是反馈系统(reward system);
在心理学(Psychology)领域,研究动物如何做出决策、动物的行为是由什么导致的;
在经济学(Economics)领域体现在博弈论的研究。
这所有的问题最终都归结为一个问题,人为什么能够做出最优决策,且人类是如何做到的。
| 原理
强化学习作为一个序列决策(Sequential Decision Making)问题,它需要连续选择一些行为,从这些行为完成后得到最大的收益作为最好的结果。它在 没有任何label告诉算法应该怎么做的情况下,通过先尝试做出一些行为——然后得到一个结果,通过判断这个结果是对还是错来对之前的行为进行反馈 。由这个反馈来调整之前的行为,通过不断的调整算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
强化学习与监督学习有不少区别,从前文中可以看到 监督学习是有一个label(标记)的,这个label告诉算法什么样的输入对应着什么样的输出。而强化学习没有label告诉它在某种情况下应该做出什么样的行为,只有一个做出一系列行为后最终反馈回来的reward signal,这个signal能判断当前选择的行为是好是坏。另外
强化学习的结果反馈有延时
,有时候可能需要走了很多步以后才知道之前某步的选择是好还是坏,而监督学习如果做了比较坏的选择则会立刻反馈给算法。强化学习面对的输入总是在变化,不像监督学习中——输入是独立分布的。每当算法做出一个行为,它就影响了下一次决策的输入。强化学习和标准的监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在Exploration(探索未知的领域)和Exploitation(利用现有知识)之间找到平衡。
| 实现过程
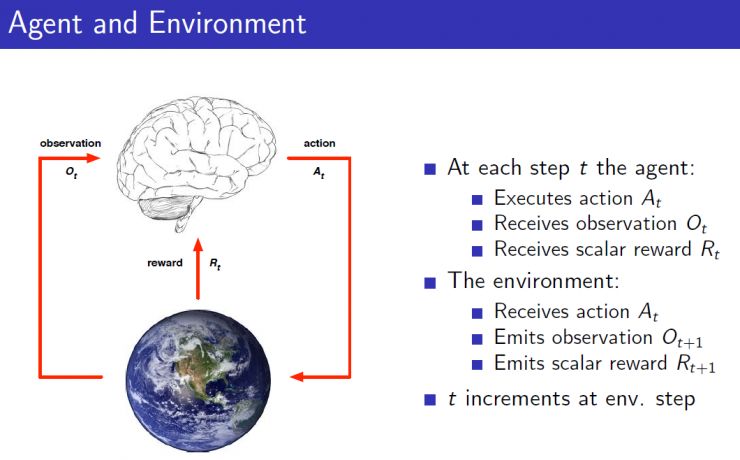
强化学习决策实现过程需要设定一个agent(图中的大脑部分),agent能够执行某个action(例如决定围棋棋子下在哪个位置,机器人的下一步该怎么走)。Agent能够接收当前环境的一个observation(观察),例如当前机器人的摄像头拍摄到场景。Agent还能接收当它执行某个action后的reward,即在第t步agent的工作流程是执行一个动作A t ,获得该动作之后的环境观测状况O t ,以及获得这个动作的反馈奖赏R t 。而环境environment则是agent交互的对象,它是一个行为不可控制的对象,agent一开始不知道环境会对不同action做出什么样的反应,而环境会通过observation告诉agent当前的环境状态,同时环境能够根据可能的最终结果反馈给agent一个reward,例如围棋棋面就是一个environment,它可以根据当前的棋面状况估计一下黑白双方输赢的比例。因而在第t步,environment的工作流程是接收一个A t ,对这个动作做出反应之后传递环境状况和评估的reward给agent。reward奖赏R t ,是一个反馈标量值,它表明了在第t步agent做出的决策有多好或者有多不好,整个强化学习优化的目标就是最大化累积reward。
强化学习中Agent的组成

一个agent由Policy(策略)、Value function(价值函数)、Model(模型)三部分组成,但这三部分不是必须同时存在的。
Policy(策略) :它根据当前看到的observation来决定action,是从state到action的映射。有两种表达形式,一种是Deterministic policy(确定策略)即 a=π(s)a=π(s) ,在某种状态s下,一定会执行某个动作a。一种是Stochastic policy(随机策略)即 π(a|s)=p[At=a|St=s]π(a|s)=p[At=a|St=s] ,它是在某种状态下执行某个动作的概率。
Value function(价值函数) :它预测了当前状态下未来可能获得的reward的期望。 Vπ(s)=Eπ[Rt+1+rRt+2+…|St=s]Vπ(s)=Eπ[Rt+1+rRt+2+…|St=s] 。用于衡量当前状态的好坏。
Model(模型) :预测environment下一步会做出什么样的改变,从而预测agent接收到的状态或者reward是什么。因而有两种类型的model,一种是预测下一个state的transition model即 Pass′=p[St+1=s′|St=s,At=a]Pss′a=p[St+1=s′|St=s,At=a] ,一种是预测下一次reward的reward model即 Ras=E[Rt+1|St=s,At=a]Rsa=E[Rt+1|St=s,At=a]
| 探索和利用
强化学习是一种试错(trial-and-error)的学习方式: 最开始的时候不清楚environment(环境)的工作方式,不清楚执行什么样的action(行为)是对的,什么样的action(行为)是错的。因而agent需要从不断尝试的经验中发现一个好的policy,从而在这个过程中获取更多的reward。
在学习过程中,会有一个在Exploration(探索)和Exploitation(利用)之间的权衡。
Exploration(探索) 会放弃一些已知的reward信息,而去尝试一些新的选择——即在某种状态下,算法也许已经学习到选择什么action让reward比较大,但是并不能每次都做出同样的选择,也许另外一个没有尝试过的选择会让reward更大,即Exploration希望能够探索更多关于environment的信息。
Exploitation(利用) 指根据已知的信息最大化reward。
举个例子,这两者在选择一家餐馆时——Exploration(探索)会选择你最喜欢的餐馆,而Exploitation(利用)则会尝试选择一个新的餐馆。
总结 :经过文中对于强化学习中背景、原理、实现过程以及相关概念的介绍,相信大家对于强化学习会有一个基础的认识。
PS : 本文由雷锋网 (搜索“雷锋网”公众号关注) 编译,未经许可拒绝转载!
via David Silver
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

