Voices:LinkedIn了解用户反馈的文本分析平台
大数据时代,各家公司都在收集更多自由文本格式的非结构化数据,内容从客服对话到市场研究调查均有涵盖。尽管这些用户反馈(VOM)包含宝贵的信息,但通常来说,如何大规模对这些数据进行最有效的分析还是比较模糊的。
找出用户反馈数据的主题非常关键,不仅能让我们了解用户的担忧及痛点,还能通过总结洞见以作出更好的商业决策,改进产品及用户体验。其中一些典型的案例包括:
-
在调查 净推荐值(NPS) 的市场研究中,我们希望了解用户向他人推荐品牌或网站的原因,即为公司提高NPS分数的动力是什么。在NPS调查中,类似“构建网络”这样的主题给了我们提示:用户喜欢能作为有效工具,构建自己社交网络的网站。
-
我们希望能从应用的评论中了解用户的应用体验,并用以修复问题、改善产品。例如,评论中关于“应用崩溃”的主题表明应用存在着潜在缺陷。
-
对于客户服务(CS)邮件来说,最主要的目的是找出报告最频繁的问题。例如,在客户服务邮件中“合并帐号”这个词出现的次数让我们知道,到底有多少用户拥有多个个人帐号与资料,以及相应问题的严重性。所有这些主题都会按照主体模式及相关操作分类。
文本挖掘又被称为文本分析,指的是运用高级数据挖掘与自然语言处理技术对非结构化的文本进行计算研究,这项技术在处理上述任务时有很大用处。文本挖掘的关键一般包括但不限于:主题挖掘、文本分类、文本聚类以及分类构建。
文本分析这个市场中有很多公司竞争(见下图),目前有很多可用的供应商及开源工具。既然选择有这么多,为什么我们还要构建自己的解决方案呢?主要的原因在于,我们希望这个解决方案具备可扩展性、灵活性与专注性:首先,由于我们要处理的是来自多个渠道、不同性质的大量数据,因此理想的解决方案应当是可扩展的;其次,由于调研和集成了不同的文本挖掘功能,我们还希望系统具备灵活性;最后,我们希望能专注于某一部分的数据,比如与LinkedIn相关的数据。在决定使用哪一种文本分析平台时,还需要考虑的其它重要因素包括时间、开发成本以及维护费用。

图一:文本分析供应商与开源工具
在LinkedIn,我们建立了Voices这个文本分析平台,通过它访问关于我们网站和主要产品的用户反馈非常简单。Voices聚合了来自内部(比如LinkedIn发布的信息、客户支持案例、NPS调查结果)及外部(比如来自Facebook、Twitter、新闻、论坛及博客等社交媒体)数据来源的非结构化文本,将来自各种渠道的结构化客户数据及非结构化文本数据录入 HDFS ,再使用一套文本挖掘功能来处理。通过Voices,我们可以从各个角度总结出相关的见解,比如价值定位、产品、情感、见解趋势还有很多其它的用例。
我们将内部的数据来源与从外部(从社交平台、在线新闻、博客、论坛等公开数据中所提取的相关信息)获得的数据进行集成。其它数据属性,比如地理位置、情绪、用户细分等方便使用者进行商业方面的深挖,Voices中数据还包括LinkedIn在苹果商店及Google Play获得的评论。
在Voices中的文本挖掘
文本挖掘是针对非结构化文本进行计算研究,以理解用户反馈,并为更好地作出商业决策获得洞见。如果让人类执行,需要数年、数百万量级的文本阅读量,对于任何公司来说都是无法等待的。因此,我们亟需能对大量的非结构化文本执行文本挖掘的有效、高效的功能。
在Voices,有三个关键的文本挖掘组件,见图二:
- 相关性的解决方案
- 分类引擎
- 主题挖掘
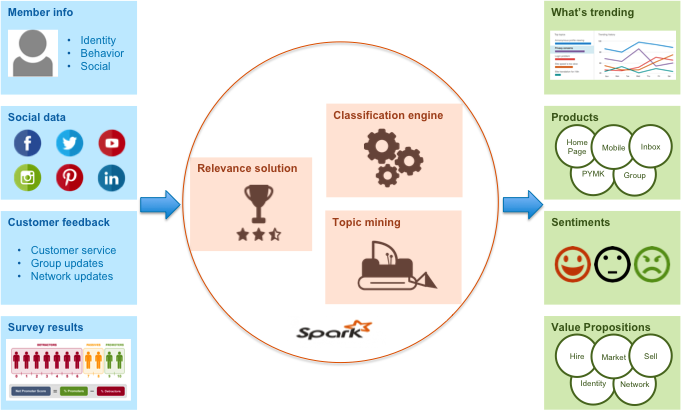
图二:Voices的文本挖掘架构
相关性的解决方案
在社交媒体中处理大量非结构化文本时,找出与LinkedIn、与我们的产品及服务相关的内容是非常关键的,而且这一步必须在其它分析开始前完成。在Voices,我们使用机器学习的方式来解决相关问题。基于曾经见过的案例——无论是否与LinkedIn相关,我们建立起模型,然后将学习到的模型应用到新的文档中,以预测这些文档各自的相关程度。
分类引擎
为了通过机器学习来完成相关性判断,我们开发了一个通用的文本分类框架,通过样例文档,使用预定义分类的已知标签(比如已知产品的客户服务表单列表,或者带有情感标签的应用评论列表)构建了 支持向量机(SVM) 模型,这个模型可以用于预测新文本文档。这个框架还有很多其它的应用,比如情感分析、产品分类以及价值定位分类。
主题挖掘
与文本分类引擎(以及相关性解决方案)不同,另一个关键的文本挖掘组件是主题挖掘。主题挖掘也被称为主题建模或主题识别,是一种从非结构化文本中提取最重要概念以及相关行为的技术。我们的主题挖掘系统是由多个 自然语言处理(NLP) 模块构成的管道,包括:1)词性(POS)标注;2)词性模式匹配;3)主题删减;4)主题排序。这个多模块管道的核心概念就是,任何一个模块单独运用时,所产生的主题混乱且不准确。
我们的方法在诸如论坛讨论、小组更新、博客等自然语言中,针对用户反馈数据的效果良好。系统产生的主题可用于:1)无需人工查看内容,便可理解并使用用户反馈中的信息;2)对用户投诉进行分类或者分组,以供客服代表进一步处理;3)识别主题相关的情绪;4)方便搜索用户投诉;5)为与主题相关的内容产生结论;6)用以实现文本分类功能,以减少功能,并提高效率。
讨论
在开发Voices系统时,我们获得了很多经验,希望与社区分享。首先,在进行文本挖掘时,我们时常要面对抉择,包括选择供应商产品、开源工具以及内部解决方案。不存在万能的解决方案,权衡关键的因素——比如质量、效率、灵活度、可扩展性、成本(包括开发成本与维护成本)非常重要。
其次,我们需要在质量与效率之间作出权衡,例如LDA是一个现成的主题建模方法,但计算花费过高、效率较低。在实践中,还有更多次优的方法在效率上和扩展性上都更胜一筹。在这些方面有所提高,同时也不会太损失质量的方案在实践中更受欢迎。
再次,如有可能,我们总是尽可能利用类似Hadoop及Spark这样的大数据基础架构来提供真正可缩放的文本挖掘功能。
最后但同样重要的是可视化,可视化对于显示文本挖掘的结果也很重要。例如,主题的显示有许多选项,包括关键字云或主题饼状图等。而最佳的可视化解决方案可以快速有效地阐述结果,方便决策制定,这对于产品及用户体验的改进都很有好处。
总结
我们构建了一个可扩展的文本分析平台,通过高级机器学习与自然语言处理技术,实现了创新性的文本挖掘解决方案。通过这样的平台,我们得以聆听社区的反馈意见,为更好的商业决策给出可执行的见解,最终为用户带来改善。
英文: Voices: a Text Analytics Platform for Understanding Member Feedback 译者: 孙薇 @Verawala
感谢陈兴璐对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

