【不周山之操作系统】Linux 概念指南
如果说计算机科学的三大浪漫是操作系统、编译原理和计算机图形学的话,谈及操作系统,Linux 就一定是那个程序员对它又爱又恨的存在。本文带大家了解 Linux 中的基本概念和原理,正所谓知其然也要知其所以然。
更新历史
- 2016.12.03: 初稿完成
系列目录
- Linux 概念指南
任务目标
- 了解 Linux 的基本概念
- 理解 Linux 的架构和背后的设计思考
- 初步掌握文件系统的操作和原理
- 对管道、进程和进程间通信有简单的感性认识
当我们谈论 Linux 时我们在谈论什么
Linux 的出现其实是一位大学生的心血来潮,Linus Torvalds(就是 Linux 之父)不满意当年学习操作系统时所使用的 Minix 系统,在其代码的基础上参考 Unix 的设计,写出了第一版 Linux 内核。之后 Linus 开源了代码,随着网络时代的大幕逐渐揭开,Linux 和 GNU 金风玉露一相逢,在开源协议下迅速发展成熟。
正所谓『不懂 Unix 的人注定最终还要重复发明一个蹩脚的 Unix』,通过学习 Linux 来掌握 Linux/Unix 的核心思想其实是非常有意义的。作为诸多天才的智慧结晶,能够从中偷师一星半点,也能受益匪浅。(新闻插播:2016.12.03 Solaris 操作系统将终止开发)
准确来说,Linux 其实只是一个内核,负责管理硬件和为上层应用提供接口。不过随着 Linux 概念的不断外延,现在提到 Linux,更多是指以 Linux 内核为基础配上各种应用的 Linux 发行版本(比如 Ubuntu, Debian 等等)。这个系列的文章不会过多着眼于各个发行版,而是专注于 Linux 内核和系统基本概念本身,比如操作系统中重要的抽象:文件系统、输入输出操作、进程、线程和进程间通信。
常见 Linux 发行版简介
因为 Linux 开源的特性,各种不同的发行版层出不穷,感兴趣的同学可以在 维基百科 - Linux 发行版列表 这个条目中看到各式各样的发行版及简介,也可以在 distrowatch.com 查看更加详细的排名,这之中比较流行的发行版有:
- ArchLinux,一个基于 KISS(Keep It Simple and Stupid) 的滚动更新的操作系统。
- CentOS,从 Red Hat 发展而来的发行版,由志愿者维护,旨在提供开源的,并与 Red Hat 100%兼容的系统。比较稳定,不用动不动就升级。
- Debian,一个强烈信奉自由软件,并由志愿者维护的系统。
- Elementary OS:基于 Ubuntu,接口酷似 Mac OS X。
- Fedora,是 Red Hat 的社区版,会经常引入新特性进行测试。
- Gentoo,一个面向高级用户的发行版,所有软件的源代码需要自行编译。
- Linux Mint,从 Ubuntu 派生并与 Ubuntu 兼容的系统。
- openSUSE,最初由 Slackware 分离出来,现在由 Novell 维护。用起来还是比较生涩。
- Red Hat Enterprise Linux,Fedora 的商业版,由 Red Hat 维护和提供技术支持。
- Ubuntu,一个非常流行的桌面发行版,由 Canonical 维护。基本上日常常用的就是它了。
因为手头上只有基于 Ubuntu 的虚拟机(包括 Win10 中自带的 Linux),所以接下来的示例都是基于 Ubuntu 14.04 LTS 的。
按下开机键之后
虽然现在我们使用的云主机基本都已经预装好了 Linux,也不需要自己去操心开机,但是操作系统毕竟不是凭空出现的,了解从按下开机键到操作系统启动之间的过程有助于我们深入理解计算机系统。整个过程的步骤如下:
- 按下开机键
- BIOS 步骤 :计算机从主板的 BIOS(Basic Input/Output System) 中读取存储的程序
- MBR 步骤 :该程序从存储设备中读取起始的 512 字节数据(称为主引导记录 Master Boot Record, MBR)
- Boot Loader 步骤 :MBR 告诉计算机从哪个分区(Partition)来载入引导加载程序(Boot Loader),Boot Loader 保存了操作系统的相关信息
- Kernel 步骤 :Boot Loader 根据所存储的信息加载内核(Kernel),内核主要的任务是管理计算机的硬件资源
- Init 步骤 :内核会为自己预留内存空间,然后进行硬件检测,之后启动 init 进程(1 号进程),之后的操作会由 init 进程来接管
- 初始化脚本步骤 :如果没有进入单用户模式,就会为操作系统启动做各种初始化工作,包括计算机基本信息、文件系统、硬盘、清理临时文件、设置网络等等
- 登录步骤 :操作系统准备好之后,我们就可以用用户名和密码登录到计算机中,我们成为了一个用户,属于某个用户组
Linux 的架构
现在我们有了一个可以运行的 Linux 操作系统,具体它是怎么工作的呢?这就要从架构说起了。

最底层是硬件,硬件之上是内核,前面说内核负责管理所有的硬件资源的意思是,所有的计算机操作都需要通过内核传递给硬件。如果接触过硬件的同学一定知道,硬件本身是颇为复杂的,即使有了内核代为管理,仍旧非常繁琐,所以在内核之上我们有了系统调用。我们不需要了解内核和硬件的细节,就可以通过系统调用来操作它们,系统调用是操作系统的最小组成单位,也就是说,计算机能做的所有操作,最终能且仅能分解成已有的系统调用。
我们可以看到,内核实际上是硬件的抽象,而系统调用是内核的抽象,在这之上的 shell 和 library 甚至应用程序其实是更高层次的抽象,正是通过这样一层一层的抽象,计算机才得以发展成为如今这么庞大却简洁的系统。
我们在命令行中输入 man 2 syscalls 就可以浏览系统调用的说明了,顺着列表往下滑,就可以看到一些我们常常使用的命令了,比如 chmod , fork , kill 等等。反应快的同学应该已经意识到了,这些命令不就是我们在 shell 中常常使用的嘛,原来它们就是系统调用!
现在最常用的 shell 叫做 bash,其他诸如 zsh, fish 等也各有各的拥趸。这里要具体说一下 shell 和终端(Terminal)的不同,在大型机时代,终端是一个硬件设备,用来进行输入输出,而随着计算机硬件的发展,终端已经慢慢从实体变成了一个概念。我们打开 Gnome Terminal 的 About 页面,就可以发现下面的介绍是这样写的:
注意这个说法 “A terminal emulator for the GNOME desktop”,什么是 emulator 呢?中文翻译叫做仿真器,等于是说,这个程序是一个仿真终端的程序。与 emulator 相关的一个非常容易混淆的概念是 simulator(模拟器),他们的差别在于:
- 仿真器。通过软件方式,精确地在一种处理器上仿真另一种处理器或者硬件的运行方式。其目的是完全仿真被仿真硬件在接收到各种外界信息的时候的反应。
- 模拟器。通过某种手段,来模拟某些东西。不一定要完全正确的原理,追求的只是尽可能的相像。
我们找一个 Mac OS 上最流行的终端的介绍来看看,同样会发现,这是一个仿真器:

所以可以这样理解,现代计算中的终端是一个用软件仿真的终端,我们在这上面输入输出的命令会传给具体执行这些命令的 shell 程序,再由 shell 程序执行对应的系统调用。重要的事情说三遍:终端不是 shell,终端不是 shell,终端不是 shell。
因为系统调用是操作系统的最小功能单位,所以一般来说提供的功能是非常零碎的,我们完成一个操作一般需要多个系统调用进行配合,于是 Linux 定义了一些 library(库),将常见的系统调用组合打包成各种功能。如果说系统调用是笔画的话,那么库函数大概就是偏旁部首了。一般来说 Linux/Unix 系统都会有 ISO C 标准库和 POSIX 标准库,用来保证不同平台的兼容性。
在 shell 和 library 的基础上,我们就可以构造各式各样强大的应用了,当然除了这两种方式外,也可以根据需要自己进行系统调用。
至此,我们就简单介绍了 Linux 架构中的各个层级:
- 内核是软硬件的桥梁
- 系统调用是应用与内核的桥梁,一方面隐藏了内核的复杂性,另一方面提高了应用的可移植性
- 库实际上是系统调用组成的模块化功能
- shell 实际上是一种方便我们操作计算机的机制
在图形化界面出现之前,在命令行中输入命令是跟电脑交互的主要方式。而在图形化界面出现这么多年之后,命令行依然扮演者举足轻重的角色,一是因为简单粗暴,二是因为可以方便地自动化流程化。
文件系统
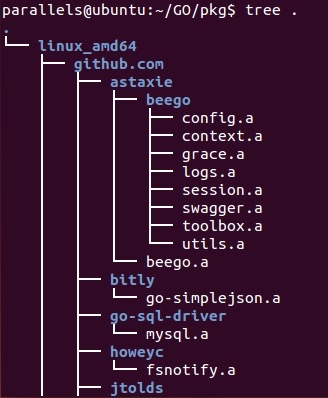
简单来说,文件系统是 0 与 1 的逻辑组织形式,常见的抽象是文件和目录。在 Linux 中,文件系统是一个树结构,树的根就是我们常常能看到的根目录 / ,每一个分叉表示一个文件夹,如下图所示:
文件名加上从根目录到该文件所在目录的目录名就构成了一个路径。对于目录来说,里面至少会包含两个条目:
. 指向当前目录 .. 指向父目录
当一个文件被放入到目录中,实际上就是建立了一个到该文件的硬链接(hard link),当对这个文件的硬链接数目为零的时候,文件实际上就被删除了。不过现在基本都使用软链接(soft link),类似于 windows 中的快捷方式,不会影响链接数目。
我们能对文件进行三种操作:
- 读取 Read: 获取数据
- 写入 Write: 创建新文件或在旧文件中写入数据
- 运行 Execute: 文件是可执行的二进制代码,那么会被载入内存进行执行
但是三种操作都有各自的权限,我们使用 ls -l filename 就可以看到详情,比如:
wdxtub@ubuntu:~/GO/bin$ ls -l -rwxrwxr-x 1 wdxtub wdxtub 11277064 Sep 14 10:35 bee wdxtub@ubuntu:~/GO$ ls -l bin drwxrwxr-x 2 wdxtub wdxtub 4096 Sep 14 10:35 bin
这里简单介绍下各个字段的含义:
- 第一个字符,如果是
-表示常规文件,如果是d表示目录 - 后面的九个字符表示 owner, owner group 和 other 的权限,rwx 分别代表读取、写入和执行,如果是
-则表示没有对应的权限 - 第二列的数字是 hard link 的数目
- 第三、四列是所属的用户和用户所在的用户组
- 第五列是文件大小,单位是字节 byte
- 最后的是上一次写入的时间
文件系统的使用基本上就是这些内容,但是这样的一个文件系统到底是怎么实现的呢?这又要从存储设备说起了。前面提到,存储设备的前 512 字节是 MBR,用于开机启动,剩余的空间可能会被分为多个分区(partition),每个分区有对应的分区表(partition table)来记录分区的相关信息(比如起始位置和分区大小)。需要注意的是,分区表并不保存在该分区中,不然万一分区挂了,连最关键的分区表都找不到了。
每个分区大概的样子是这样的:
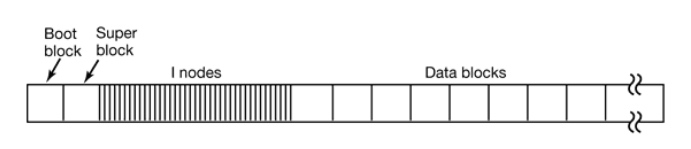
- Boot block 是为计算机启动而准备的,在 MBR 指定启动分区之后,就会把 Boot block 部分的程序读入内存执行。为了方便管理,即使该分区没有操作系统,仍然会预留 Boot block
- Super block 存储文件系统的信息,比如类型、inode 数目和数据块的数目
- inodes 是文件存储的关键,每个文件对应一个 inode,inode 中包含指向具体数据的指针,读取的时候根据这些指针进行数据读取即可
- Data blocks 就是具体的数据了,我们通过 inode 中的指针来进行访问
关于 inode 的具体实现细节这里因为篇幅所限就不展开了,会在系列后面的文章中进行介绍。
管道与流
在 Linux 中 “Everything is a stream of bytes”,用设计模式的话说其实这就是一个数据流导向的设计,信息在不同的应用之间流动,最终成为我们所需要的信息。Linux 在执行程序的时候,会自动打开三个流:
- 标准输入(Standard Input)
- 标准输出(Standard Output)
- 标准错误(Standard Error)
我们可以按需进行使用。而如果我们想把一个程序的标准输出作为另一个程序的标准输入,就需要使用管道(pipeline)了。而正是因为这样的机制,我们可以把诸多小功能组合成强大的应用,一个简单的例子是:
wdxtub@ubuntu:~$ cat hello.txt welcome to wdxtub.com wdxtub@ubuntu:~$ cat hello.txt | wc -w 3
进程与进程组
最基础的操作是指令,一堆指令在一起就是程序,而进程就是程序的具体实现,也就是把程序载入到内存中并执行的过程。操作系统的重要功能之一便是对进程进行从摇篮(分配内存空间)到坟墓(回收)的管理。我们先执行如下命令看看 ps -eo pid,comm,cmd (列出全部进程并展示 pid, command 和 cmd 信息)
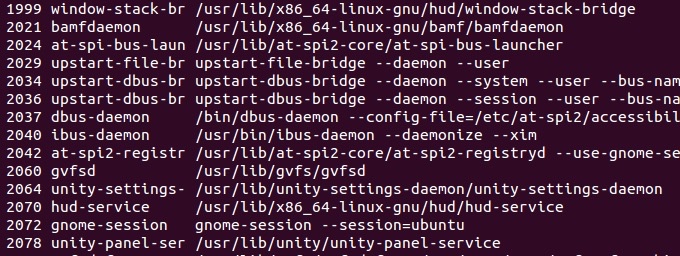
这里每一行都是一个进程,第一列是 pid,相当于身份证号;第二列是进程的简称;第三列是进程启动时候的命令。如果我们往上滚动,就会找到这样的一行 1 init /sbin/init ,这个就是内核建立的唯一一个进程了,剩下的进程都是 init 通过 fork 方式创建的,也就是说,所有的其他进程都是 init 的子进程。
子进程终结的时候会通知父进程进行内存空间的回收,而如果父进程比子进程还早终结,那么这个子进程就会被过继给 init 进程,并由 init 进程通过调用 wait 函数进行回收。如果无法正确回收,那么这个子进程就成为了僵尸进程,所占据的内存空间就无法被访问了。
除了父子进程的关系外,还有一个进程组(process group)的概念:每个进程组中有多个进程,进程组的 pid 由进程组 leader 的 pid 决定。而多个进程组还可以组成一个会话(session),会话使得前台和后台程序得以展示出来。当我们创建了多个终端窗口,实际上就创建了多个会话,每个会话都有其前台和后台进程。
进程间通信
前面介绍了进程,但是进程之前如果想要交互怎么办?除了管道之外,有没有其他方法?当然有也必须要有。其中最简单的一种就是信号,所谓信号就是一个整数,一个由进程 A 发送给进程 B 的整数。因为一个整数所能携带的信息量有限,所以一般用于系统管理。
信号的传递机制也很简单,由内核,或者由其他进程经由内核往目标进程发送信号,实际上是在该进程对应的表中写入信号。当进程执行完系统调用退出内核的时候,就会查看这个信号,然后根据信号的不同执行不同的操作。
具体什么整数表示什么意思可以通过 man 7 signal 来查看,常见的有:
-
SIGINT: 当键盘按下 CTRL+C 从 shell 中发出信号,信号被传递给 shell 中前台运行的进程,对应该信号的默认操作是中断(INTERRUPT)该进程 -
SIGQUIT: 当键盘按下 CTRL+/ 从 shell 中发出信号,信号被传递给 shell 中前台运行的进程,对应该信号的默认操作是退出(QUIT)该进程 -
SIGTSTP: 当键盘按下 CTRL+Z 从 shell 中发出信号,信号被传递给 shell 中前台运行的进程,对应该信号的默认操作是暂停(STOP)该进程 -
SIGCONT: 用于通知暂停的进程继续 -
SIGALRM: 起到定时器的作用,通常是程序在一定的时间之后才生成该信号
上面的介绍说『默认』操作,那么也就意味着我们是可以采取其他操作的,比方说直接无视掉,或者执行我们自定义的操作。
除了信号,消息队列(message queue)和共享内存(shared memory)也可以在进程间进行信息共享。不过因为这种机制比较复杂,尤其是涉及到同步的问题,所以在使用的时候需要多加注意。
试一试
- 试着自己安装一个 Linux 系统,尝试只使用终端来完成基本的文件夹查看操作
- 查看系统当前正在运行的进程
- 试着给某个进程发送一个信号
正文到此结束
- 本文标签: 排名 文件系统 Ubuntu tab ip 安装 空间 开源 删除 IO 目录 unix shell centos 设计模式 开发 http 处理器 云 测试 mina cat 时间 操作系统 queue linux 中文翻译 自动化 进程 代码 快的 主机 message 翻译 node 线程 管理 软件 src IOS 协议 windows 学生 IDE 组织 lib 文章 id 编译 cmd tar 数据 消息队列 dist Enterprise Master rmi IBM UI 程序员 同步
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

