UCloud 分布式消息队列 UMQ 设计与架构演进
肖丁,基础架构研发部工程师,负责 UCloud 公共组件、监控、消息服务等系统,专注于高可用高性能框架、中间件应用。2014年加入 UCloud,先后参与 UCloud 监控平台改造、内部 DNS 集群化、DB 服务集群化、golang 网络通信框架、通用 agent 等项目。
一、背景介绍
消息队列是企业架构演进过程中不可或缺的部分,其天生的灵活性、可扩展性、消息处理能力可以方便地帮助企业服务解耦,处理服务峰值压力。但构建与维护消息队列是很耗费时间与人力的事情。消息队列集群在使用和维护过程中,经常会遇到主节点性能瓶颈、容量规划、网络分区等问题,处理不当则可能导致消息丢失,进而影响服务。
1、消息队列应用场景
通常,我们将消息功能分为两大类:主动消费和被动消费。
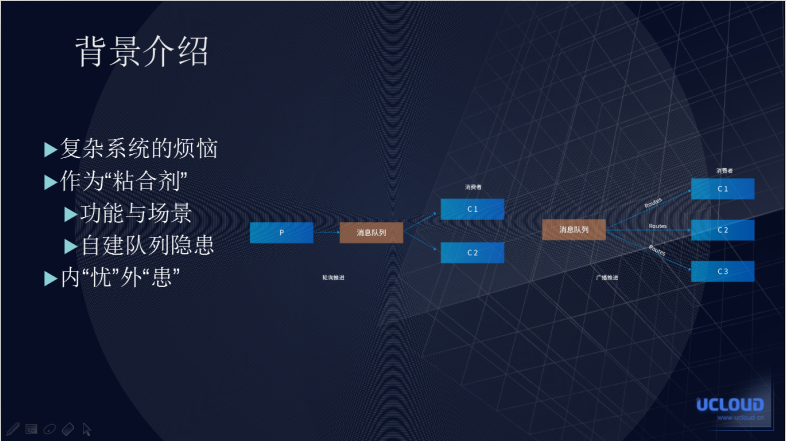
图中是两个被动消费的场景,即消费者首先要和消息队列产生一个长连接。当推送者向消息队列推送消息的时候,第一种场景是指要轮询推送给消费者,这是最常见的轮询负载均衡的方式;第二种是以广播的形式,如一个消息副本需要传递给多个子模块进行消费。如果没有消息队列的应用有些消息从 A 模块传递到 B 模块在传递到 C 模块,实现一个整体的链入的处理。
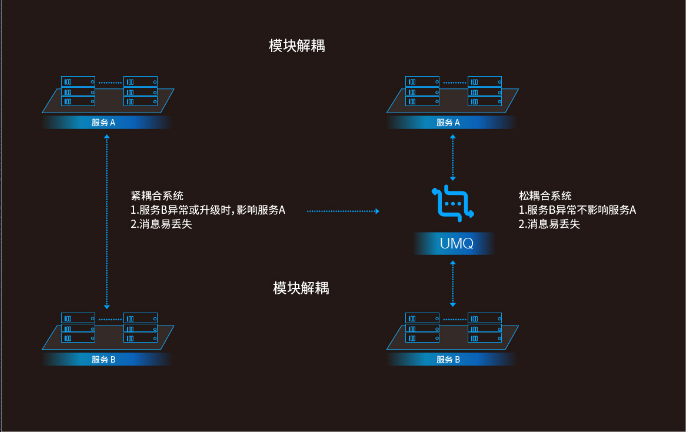
2、模块解耦
紧耦合系统:服务 A 依赖服务B的稳定性,当服务 B 异常或者日常升级时,服务 A 的请求将被丢弃。
松耦合系统:接入 UMQ 后,服务 A 的消息由 UMQ 缓存,当服务 B 异常时,服务 A 的消息不会丢失,待服务 B 恢复之后再做处理。
3、消息缓冲
无 UMQ 场景下,当服务请求量增加时,服务器压力与请求量为线性关系,且通常的做法是做服务的扩容,造成资源的浪费。
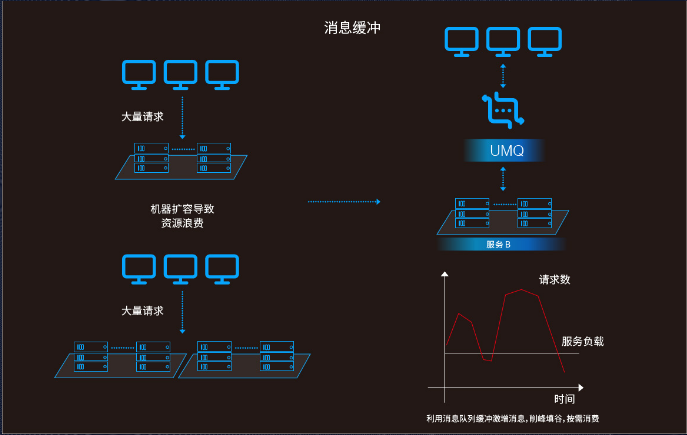
接入 UMQ 场景后,服务请求量的大幅波动不会影响服务的负载能力,帮助服务平滑处理所有请求。如,当大量消息同时涌进消息队列时,可能出现后台服务无法及时处理所有消息,导致回复等情况,这时后端子系统会根据根据用户的消费能力和消费水平批量筛选部分消息。
4、异步通知
无 UMQ 场景下,一次请求需要同步等待后端处理,得到响应后再执行其他任务,可能会出现延迟等待的情况;或者轮询后端任务结果,造成多余的请求。
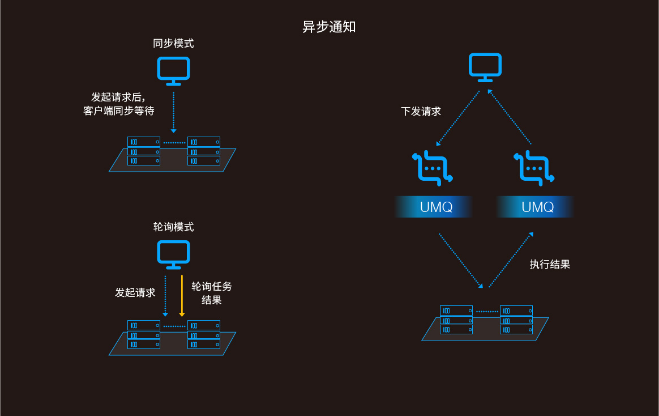
接入 UMQ 后实现异步通知,用户不需要同步等待,也不需要额外的轮询开销,通过异步的队列通知,获取结果集。它更适合后端研发人员使用,是优化后端系统的一种方式。如图所示,左边的同步模式和轮询模式,它们都需要客户端发送请求后等待服务端的返回,或客户端发送请求后要不断地轮询,这会对后端系统造成负载压力。异步通知的方式是基于两个消息队列,一个进行消费推送,一个进行 response 回执,这有利于实现后端系统负载的减轻。
二、项目构建过程
设计消息队列之初,我们没有考虑要自己”造轮子”,而是使用了一些现有的开源方案,如,RabbitMQ。但在搭建过程中遇到不少问题:整体的集群需要通过一套自有的共识算法来选出一个 master 节点做所有消息的一次性算法。但网络波动之后,我们发现整个消息队列的集群会出现脑裂的现象,如,不同的队列会被分配到不同的节点中,导致节点数据没法融合在一起,这对消息队列的设计产生了很大的困扰。未解决此类问题,在 RabbitMQ 脑裂的策略中我们必须舍弃一部分数据,再将它们合并到一个集群中等。
随后,我们也利用了 Golang 的高并发和 Channel 的一些特性来实现分布式的消息队列。
在我们决定造轮子时,我们会考虑哪种方式能最快实现消息队列,然后我们确定了两种模式,单体模式和微服务模式,如下所示,我对它们的优缺点进行了分析:

架构 v1.0 如图所示:
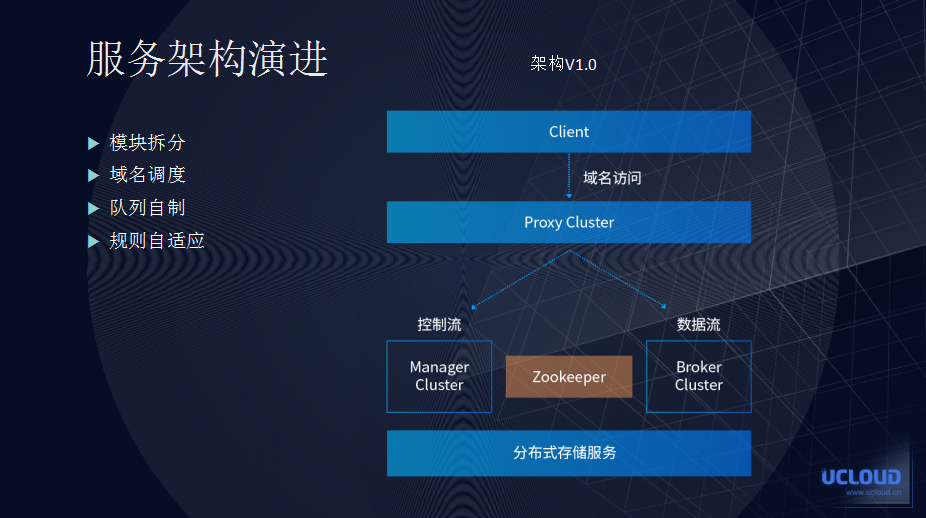
其中,Proxy 做揭露层的负载均衡,Broker 实现队列的核心逻辑,Manager 管理语言数据。第一版设计我们只用了运营访问的方式。因为我们已经使用了 Broker 的集群做队列的管理,所以整个队列集群需要有一套自适应的规则来进行管理所有节点。因此,在 Broker 和 Manager 节点内我们使用了一次性哈希算法,把不同的队列分配到不同的队列节点上处理。
当然,v1.0上也出现了一些问题,如:我们无从知道队列会落在那个队列节点上等。于是,根据这些问题,我们做了 v2.0 的改进:

此次改进引入了一个 ULB,它能快速实现后端服务的调度,请求的快速分配等。Controller 可人工控制 Proxy 下发队列信息到相应节点。底层的分布式存储也是 Redis 和 MySQL 的服务,这减轻了底层容量负担。这个架构目前也存在一些问题,如,Controller 是一个单点,当它失效时,如果没有及时回复,队列集群会不可控。其次,因为我们使用的是储备的 Broker,虽然它有自己的资源限定,但还是会对整体资源造成浪费。
在 v3.0 的时候我们最终确定了架构版本,我们重新用回原来的 Zookeeper 做 Broker 队列节点的信息上报和映射关系的处理。而 Proxy 和 Manager 是利用 Zookeeper 的 watch 特性获取队列关系的变化和队列节点的心跳变化,它能秒及地改变下发的策略。

在 Manager 中,我们把所有队列的控制规则和 Controller 进行合并,这样,当主 Manager 失效时,子 Manager 同样能注册成功。
而在 Bocker 方面,则用回之前的设计思路,即采用单点的方式,这样,当某个 Broker 失效时,Manager 会在感知到之后会将整个节点剔除,然后重新分配一个节点。
三、技术实践
1、Broker 模块的实现
因为整个内容是用 Golang 制作,所以 Broker 相应的具备了 Golang 的一些特性,如图所示:
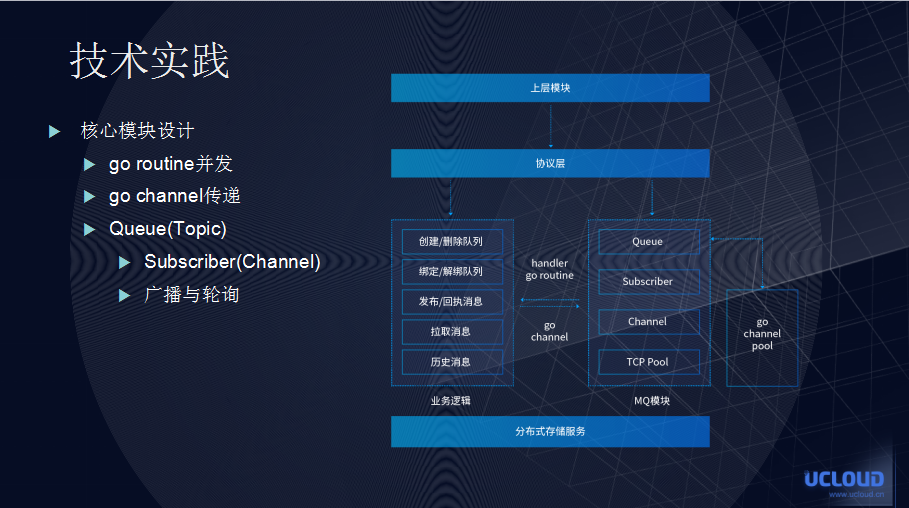
举例说明:上层模块(Proxy)将所有消息请求的透传至 Brocker,Brocker 在协议层做解析,然后将请求放置业务逻辑中,业务逻辑再选择对应的方法,交由 go routine 进行处理,随后生成的新队列节点判断是否接受消息,然后通过 go channel 层层传递至 Subscriber。最后推送的消息则需要利用 Brocker 和 Proxy 之间的连接池,它能最大限度提升性能。此外,当 TCP pool 开始服务时,Proxy 会向 Broker 主动申请产生连接。
2、整个系统的容灾和恢复
- 节点探测
- 连接恢复
- 跨机房容灾
节点探测
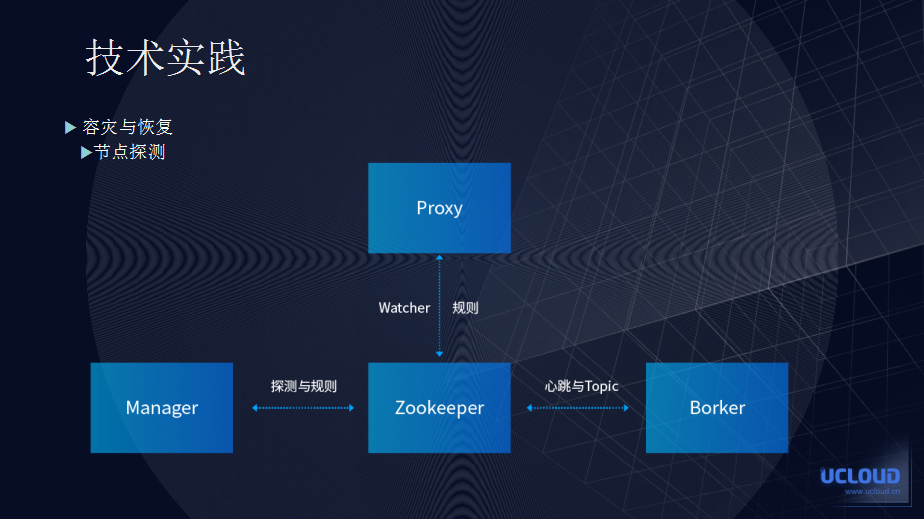
Proxy 与 Brocker 节点的探测:因为我们无法直接从连接层感知连接是否出现异常,所以需要在 receive 和 send 的过程中感知,随后再进行连接恢复的处理。
连接恢复

因 Proxy 会主动向 Brocker 发起 TCP 连接,所以每个连接都会通过 go routine 执行 receive 操作。当 receive 出现异常,Proxy 能感知并退出 go routine,之后重新建立连接放入 go routine。反之,当 Brocker 需要探测 Proxy 异常时,它会先从 TCP 连接池选出一项连接进行消息推送,如果推送失败,会反向删除原连接池的连接并重新选择连接,这两个过程相辅相成。
跨机房容灾
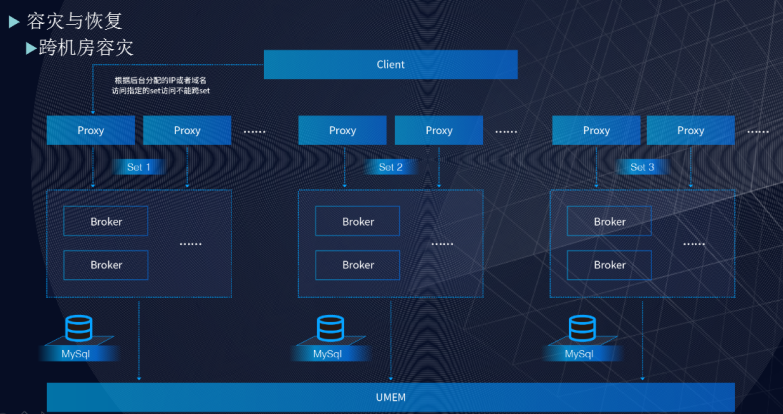
跨机房容灾是将不同用户分到不同的 set 内来做区分,它只能保证部分 set 内的用户不受影响。当整个数据中心出现问题时,图中左边整条链路都将失效。
四、经验和心得
在 UMQ 的设计和架构的演进过程中,我们虽然遇到了许多具有挑战性的问题,但最终还是克服了困难,并成功利用 UCloud IaaS 服务搭建了微服务架构,保证了服务的高可用,同时利用 golang 完成了 UMQ 核心模块的实现,实现了高性能。希望这些经验对你有帮助。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

