Urban Airship是如何在美国大选日支持了25亿条通知的
本文翻译自: How Urban Airship Scaled To 2.5 Billion Notifications During The U.S. Election ,已获得原网站翻译许可。
这是Urban Airship发过来的一篇投稿内容,原作者包括:Adam Lowry、 Sean Moran、Mike Herrick、Lisa Orr、Todd Johnson、Christine Ciandrini、Ashish Warty、Nick Adlard、Mele Sax-Barnett、Niall Kelly、Graham Forest和Gavin McQuillan。
大家都相信Urban Airship在手机上会有非常多的商业机会。Urban Ship是一家已有七年历史的老SaaS公司,她也提供了免费增值商业模式,所以你可以试试免费体验一下。要想了解更多信息请访问 www.urbanairship.com 。现在每天Urban Airship都平均要推送十亿以上条通知消息。本文关注Urban Airship在2016美国大选期间对通知消息的使用,讲述一下系统架构——核心推送管道——是如何为消息发布者发送了几十亿条实时通知的。
2016年美国总统大选
在选举日的24个小时中,Urban Airship共推送了25亿条通知消息,这是它有史以来的单日最高推送量了。这大概相当于为每个美国人推送8条通知消息,或者为这世界上每一个在网的手机号码都推送一条消息。由于Urban Airship在各个行业里共支持了约4.5万个手机应用,对选举日数据的分析表明有400多个媒体应用发送了这个消息量的60%,即在跟进选举过程和报告结果的过程中,一天就发送了15亿条通知消息。
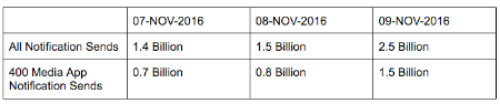
当大选结果尘埃落定之后,通知量急剧上升并达到了顶峰。
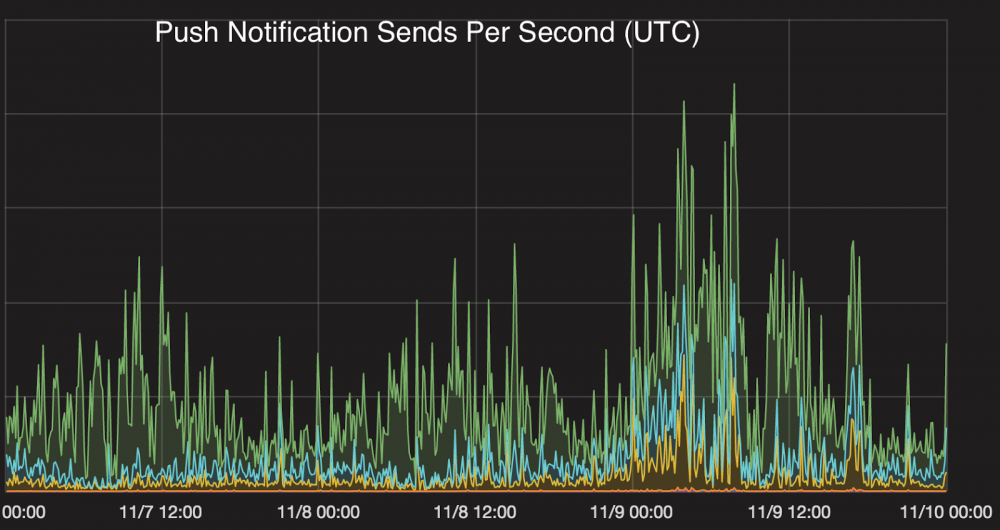
在大选过程中,通过HTTPS注入到Urban Airship API 的消息量达到了约每秒7.5万条的最高记录。其中大多数都来自于Urban Airship SDK ,它们与Urban Airship API通信。
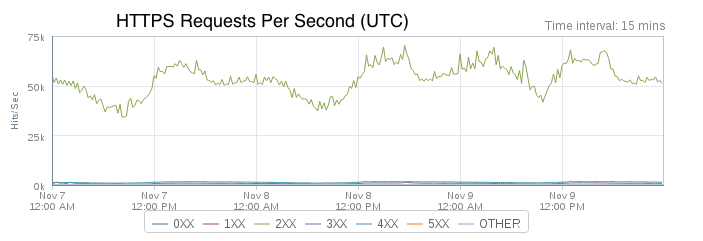
推送消息量也在快速剧增。最近推送量大增的主要事因有英国退出欧盟事件、奥林匹克运动会和美国大选。2016年十月的单月推送量与去年相比增加了150%。
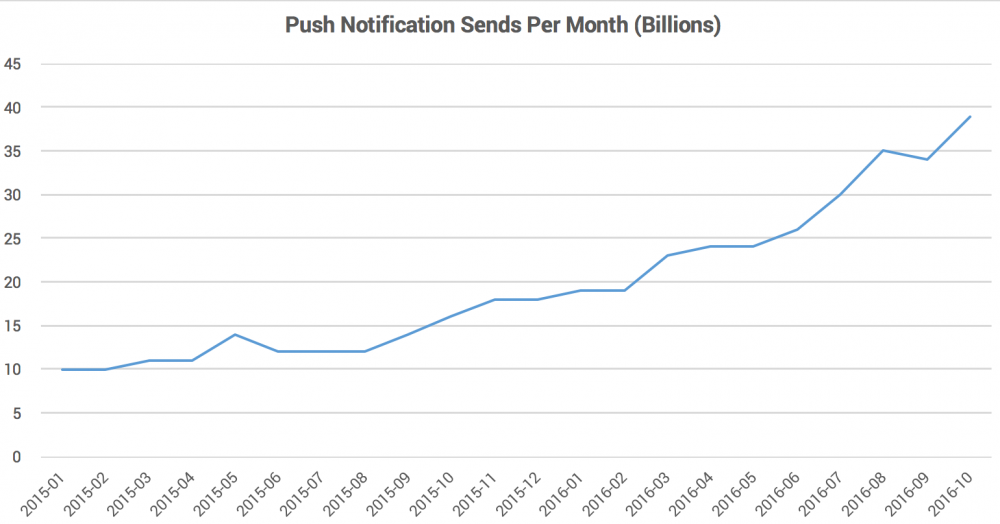
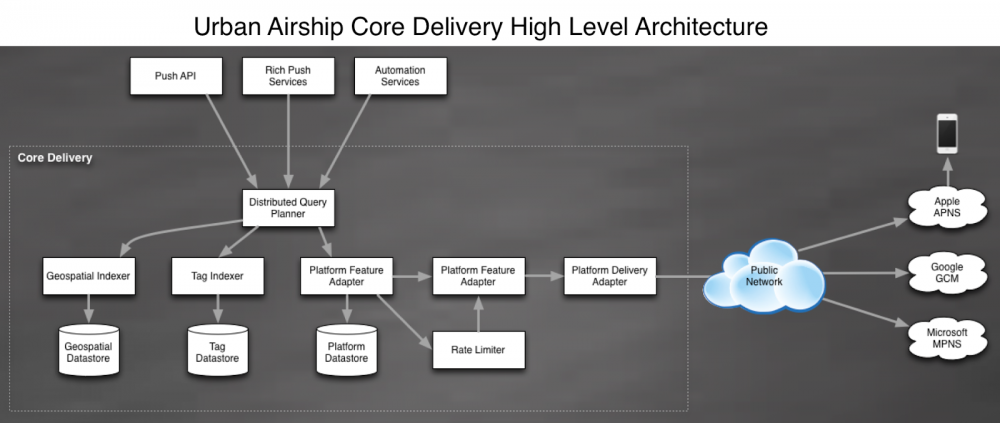
核心推送管道架构概览
核心推送管道(Core Delivery Pipeline,CDP)是在Urban Airship系统中负责从接收者选择器中物化设备地址并向其推送通知的系统。不管发送什么样的通知消息,我们都要追求低延迟,不管是要同时发送给几百万个用户,或者要发送到多个复杂的子系统中,或者包含个性化内容,或者任意上述的组合,等等。下面是对我们架构的一个概述,以及演进过程中我们总结的一些经验。
我们是怎么开始的
最初在2009年起步时只是一个Webapp,几个子模块慢慢演进成了面向服务的架构。当旧系统的几个部分开始遇上扩展难题时,我们从中提炼出了一个或几个新服务用于支持同样的功能,但规模更大并且性能更好。许多旧的API和子模块都是用Python写的,我们把它们换成了高并发的Java服务。最早时我们把设备数据保存在一些Postgres分区中,可是我们增加新分区的速度始终跟不上我们的业务规模扩展速度,因此我们就移到了一个基于HBase和Cassandra的混合数据库架构上来。
核心推送管道是一系列处理分片和推送通知消息的服务的集合。这些服务会为请求消息提供相同数据类型的回复消息,但每个服务的数据都是为了最佳性能而按不同方式索引的。比如,有个系统是负责处理广播消息的,就是把相同的通知消息发送给注册到相关应用上的所有手机。还有的服务是负责基于位置或其它用户个人属性而发送通知消息的,这些服务以及它们底层的数据存储的设计彼此不同。
我们把所有持续长期运行的进程都叫做服务。为了方便部署和运营,在指标、配置和记录日志等方面这些服务都使用了相同的模板。通常我们的服务都会属于下面两组之一:RPC服务或消费者服务。RPC服务对外提供一些命令,来与一些使用与GRPC很相近的内部库的服务交互。而消费者服务会则会从Kafka流中读出消息进行处理,并且依具体服务的不同而对这些消息进行处理。
(点击放大图像)
数据库
为了满足对性能和规模的需求,我们使用了非常大量的HBase和Cassandra来做数据存储。尽管HBase和Cassandra都是列存储型NoSQL数据库,它们在细节的侧重上还是各有不同,因此我们也会根据具体项目的需求选择和使用不同的数据库。
HBase非常适合用来做大吞吐量检索,期望的响应消息的势(cardinality)比较高,而Cassandra比较适合于低势检索,响应消息里应该只包含少量的数据结果。它们两个都可以进行大数据量的写入,这恰好是我们的需求之一,因为所有对用户的手机号码的更新操作都必须实时完成。
它们的缺点也互不相同。HBase在出现故障时支持一致性和分区容忍性,而Cassandra支持可用性和分区容忍性。每一种CDP服务都有非常独特的用例,因此也都有着非常专门设计的模式来方便进行数据访问,以及限制存储空间。作为一种通用的规则,每个数据库都只被一种单独的服务访问,并且通过一种比较通用的接口来为其它服务提供数据库访问。
强化这种一对一的服务和后台数据库之间的关系有一系列的好处。
- 通过把服务的后台数据存储当作一种实现细节来处理,而不是一种共享的资源,我们就获得了灵活性。
- 我们可以改变一个服务的数据模型,只需要修改一个服务的代码就可以。
- 利用率跟踪也是非常直白的,这就让存储空间计划更容易做。
- 调查问题很容易。有时候问题在于服务的代码,有时候是后台数据库的问题。把服务和数据库一起作为一个逻辑单元极大地简化了调查问题的过程。我们不必再费心去想“还有谁也在访问这个数据库,才让它成了现在这个样子?”相反,我们只依赖这个服务相关的应用级别的指标就可以了,只需要考虑一种访问模式。
- 因为只有一个服务会访问一个数据库,所以我们几乎不必付出任何停服时间就可以完成绝大部分的维护操作了。大型维护任务成了一些服务级别的考虑:数据修复、模式更改以及甚至迁移到一种完成不同的数据库上都可以不需要中断服务而完成。
的确,在把应用程序拆分成更小的服务时会带来一些性能上的损耗。可是,从我们在完成高扩展性和高可用性需求的方面获得的灵活性上来看,这样做是完全值得的。
数据模型
我们大多数的服务都处理的是相同的数据,只是格式不同而已。所有数据都必须是一致的。要保持所有这些服务的数据都是最新的,我们主要是要靠Kafka。Kafka速度快,可靠性高。速度快也带来了一些折衷。Kafka的消息只能保证是至少发送一次的可靠级别,而且并不保证会按顺序到达。
我们怎么应对这种情况呢?我们设计让所有的可能路径都是可替换的:数据更改操作可以按任意顺序应用,而最终都会保证相同的结果。它们这样也是幂等的。这样就带来了一个非常好的特性,我们可以把Kafka流重放,用作一次性的数据修复任务、回填甚至迁移。
为实现这样的功能我们利用了HBase和Cassandra共有的概念“Cell版本”。一般来说这是一个时间戳,但也可以是任意你喜欢的数字(有一些例外情况,比如,依你的HBase或Cassandra的版本不同以及你的模式处理删除操作的方式不同,MAX_LONG有可能会导致一些奇怪的行为)。
对我们来说,对这些Cell的一般规则就是它们可以有多个版本,而且我们对版本进行排序的依据就是它们提供的时间戳。有了这个意识,我们就可以把输入的消息拆分,存入一些具体的列中,也可以依据时间戳根据一些应用逻辑来把一些数据淘汰。这样就可以在保持数据完整性的同时,允许对底层存储的随意写入。
就这样随意写入Cassandra和HBase也并不是没有问题的。一个很典型的例子就是在重放时对相同数据的重复写入。因为操作是有幂等性的,那写入的数据就事实上不该改变,因此重复的数据就应该合并掉。在一些最极端的例子中,这些多余的记录可能会导致极严重的合并延迟和备份问题。考虑到这个细节,我们会密切地监控合并时间以及队列长度,因为由合并而导致延迟在Cassandra和HBase中都会导致非常严重的问题。
在保证流中的消息都遵守若干规则的前提下,以及设计消费者服务来处理乱序和重复的消息,我们可以保证许多独立的服务数据同步延迟只有一两秒。
服务设计
我们大多数服务的代码都是用Java写的,但具体风格却五花八门。我们制定了一系列的通用指导规则,供大家在设计Java服务时参考:
只做一件事,把它做好——在设计一个服务的时候,它应该只承担一个责任。可以由实现者来决定在这个责任里面加进些什么东西,但在代码审查会议上他必须能够说服大家这样做是合理的。
没有共享的操作状态——在设计一个服务的时候,要假设至少这个服务有三个实例在运行。不需要任何外部的协调,这个服务的一个实例可以处理某个请求,那另一个实例必须也可以。那些熟悉Kafka的人会想起来Kafka消费者会在外部协调一个Topic:Group对的分区对应关系。这个规则提的是一些特定服务相关的外部协调机制,而不是指利用库或客户端来在外部隐式地协调。
要给队列加限制——我们在各种服务中普遍使用了队列,用于缓冲请求和将请求分散给多个处理进程以避免处理过程会阻塞对外部的响应,在这方面队列是非常有效的。但所有的队列都必须加以限制。的确,给队列加限制会引发若干问题,可是:
- 当队列满时生产者又会怎样?它们该堵塞吗?还是丢弃消息?
- 队列该有多大?要回答这个问题,可以试着假设队列常常是满的。
- 我怎样才能干干净净地关闭服务?
- 每个服务都会对这些问题有自己的答案,因为它们的用例不同。
生成定制的线程池并注册UncaughtExceptionHandler——如果最终我们需要自己创建线程池,我们会使用 Executors 提供的构造函数或帮助方法来提供一个ThreadFactory。有了这个ThreadFactory,我们就可以恰当地命名自己的线程,设置它们的守候运行状态,并且注册 UncaughtExceptionHandler 以便在意外发生时可以进行处理。这些都让调试服务的过程变得更容易,也让我们避免了很多次熬夜的经历。
与可变的状态相比,我们更喜欢不变的数据对象——在一个高并发的环境中,可变状态是非常危险的。通常我们会把不可变的数据对象在内部子系统和队列之间传来传去。使用不可变的数据对象成了在子系统之间通信的主要形式,这让并发的设计变得更直白,也让调查问题变得更容易。
下一步该往哪里去?
现在Urban Airship已经可以通过手机钱包发送消息,已经支持网页通知和Apple新闻通知,也有开放式渠道可以把消息发往任意平台、设备或市场渠道,我们期望消息的发送量可以获得指数级地增长。要满足这个需求,我们还在继续向我们的核心推送管道架构、服务、数据库和基础设施加大投入。要想了解更多有关我们的技术的内容或者了解我们的发展方向,请关注 GitHub 、 开发者资源 、 文档 和我们的 招聘页面 。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

