机器学习与Dota2英雄属性
机器学习与Dota2英雄属性
 本文使用自然语言处理(NLP)方法对DOTA2 英雄角色属性做了简要的分析。
本文使用自然语言处理(NLP)方法对DOTA2 英雄角色属性做了简要的分析。
引言
如果有人问你“兔子”是什么意思,你会怎么回答?你可能会跑出去,每次看到一只兔子就指给那个人看,说“喏,那就是兔子。”当然那个人得和你三观相近,你才能解释得通。那如果对方对世界的认知方式和你不同,你要怎么向他解释?
这就是为什么要引入词向量(word vector)这个概念。词向量基于分布假定,即“语义相近的词语往往会出现在相似的内容中”。
在语言学中,如果你发现“negotiate”和“bargain”总是出现在相似的内容里,它们的语义就可能也是相近的。通过将词语向量化,再去计算向量化后“negotiate”和“bargain”的余弦相似度(一种测量两个向量间相似性的方法),你会发现相似度的值会接近1。词向量也常用于利用相似性去解释一些东西,比如说“皇帝”是“男人”,“皇后”就是“女人”。
从词向量到英雄向量:
那么词向量怎么帮助我们去认识 Dota2 中的队伍呢?你可以想象每只Dota2 的队伍配置都是由不同英雄做单词从而组成的句子,比如说:蝙蝠骑士、干扰者、拉席克、娜迦海妖、编织者,又或者:龙骑士、编织者、水晶室女、风行者、树精卫士。
正如上文提到的分布假定所说的那样,只是这次我们不通过每个词所在的句子去判断词语的意思,而是通过每个Dota2英雄所在的队伍去判断每个英雄的角色属性。具体来说,如果我们发现“巫医”和“莱恩”总是出现在相似的队伍里,那么他们可能就具有相似的角色属性。
本文使用datdota( http://www.datdota.com/)作为数据来源,并使用gensim library( https://radimrehurek.com/gensim/index.html)使我们的英雄向量化。
举例来说,通过对数据集的训练,“影魔”这个英雄向量化后大致如下:
[-0.06813218, -0.00902375, 0.10162564, -0.01908037, 0.03013835,
0.16538762, 0.03104097, 0.02496031, -0.16785616, 0.3313826 ,
-0.21904311, -0.07945664, 0.19140202, 0.12729862, 0.36308175,
0.19962946, 0.13561839, 0.23637122, -0.32607114, 0.05647549,
0.09655968, -0.21899879, 0.04926173, 0.12474103, 0.14504923,
0.06281823, 0.14728694, -0.03583163, -0.00227163, 0.1205247 ,
0.01127683, 0.01522848, 0.13806115, 0.0216765 , 0.13671157,
-0.1683237 , 0.00408782, 0.10514087, -0.17610508, 0.04697264,
-0.03406512, -0.14956233, 0.20201634, 0.00907436, -0.05804597,
-0.00481437, 0.11493918, -0.07718568, -0.13443205, -0.01155808]
这样,“影魔”这个英雄现在变成了50维空间里的一个点,但是把一个词变成50个数字并没有什么用处。现在来做一些炫酷的事吧!还是拿“影魔”为例,我们找出和它相似的一些英雄向量:
- 痛苦女王:0.9340388774871826
- 风暴之灵:0.9170020818710327
- 冥界亚龙:0.9082884788513184
- 狙击手:0.8958033919334412
- 宙斯:0.8526902794837952
(数字代表这些向量化后的英雄和“影魔”的余弦相似性)
下图则更直观地将结果进行展示,图中每行代表一个向量化后的英雄。

这就看起来有点感觉了,接下来再尝试一些更难的东西看看我们是不是能通过这些向量化后的英雄来解释它们之间的类比性,例如 “莱恩”相对于“敌法师”就相当于“巫医”相对于以下几个英雄:
- 幽鬼:0.9638912677764893
- 幻影长矛手:0.9185065031051636
- 幻影刺客:0.9039324522018433
- 变体精灵:0.858444333076477
- 噬魂鬼:0.8570600748062134
虽然这些分析可能不能帮助你打赢PPD,但至少下次你就知道该挑选哪些英雄来组队。
3. 全局视角:
我们可以把所有英雄同时展示在一张图里,但这难免让人眼花缭乱。
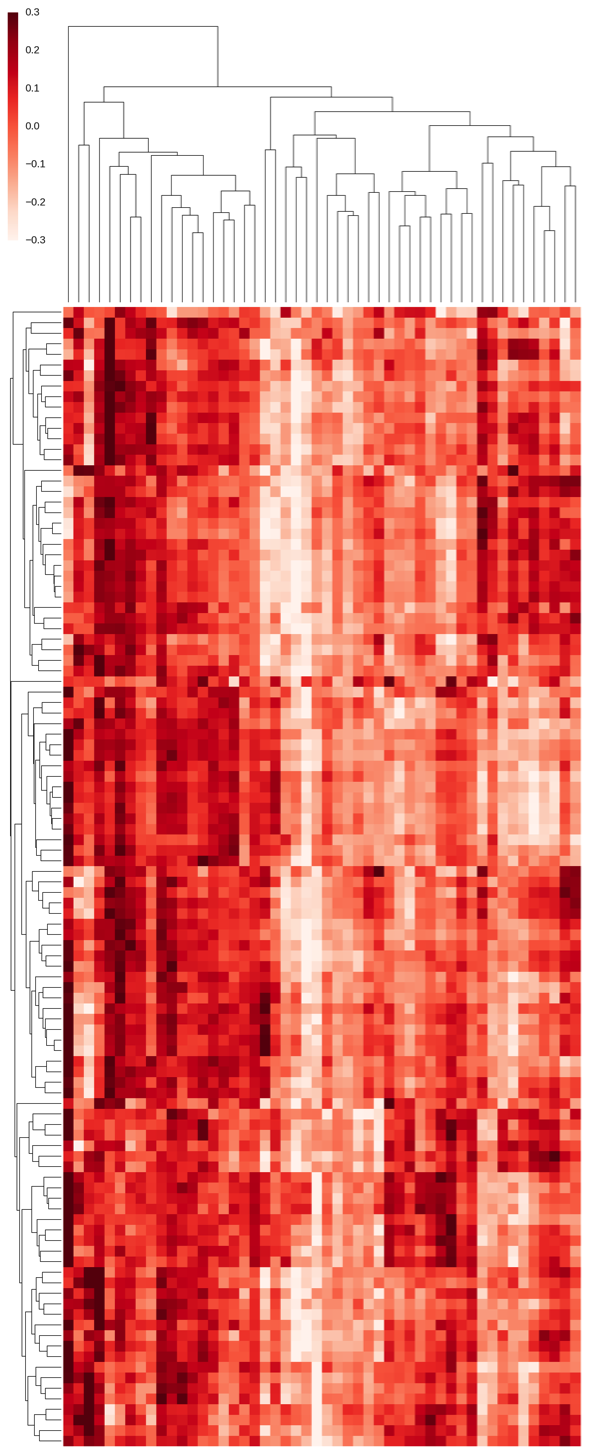
如上图所示,每一列对应一个英雄,并把行列以树状图的形式展示出来。不过除非你已经看惯了这些图,不然直观地分清哪些英雄是一类的或者判断出哪个英雄和别的相似还是挺难的。
我们将树状图精简展示出来,来看看那些英雄是相似的,结果如下图所示:

截至目前,我们已经得到了一些有意义(虽然并不完美)的英雄分类群体了,比如“劣势路三号位”群体包括了末日使者、司夜刺客、黑暗贤者、钢背兽和半人马战行者,“后期核心”群体包括了卓尔游侠、斯拉克、幻影长矛手和噬魂鬼,而“暴力型辅助”群体则包括了冥魂大帝、巨牙海民和亚巴顿。
当然有其他方式来展示分类的结果。我们可以使用 t-SNE ( https://lvdmaaten.github.io/tsne/) 将50维的数据以二维的形式展示出来。t-SNE 是一种在尽可能不破坏原有高维数据结构的基础上以低维形式展示数据的方法。
在对数据进行处理并在二维空间绘图后,我们可以得到下图:

图中英雄不同的颜色来自于上文的分类结果,直观地看这些离散分类还是具有一定意义的。
4. 向量到底代表什么?
那么我们给每个英雄赋的值到底代表什么呢?“影魔”在第一维空间里的值为-0.06813218,这个值代表什么意思?通常情况下,我们会说这些是潜在的属性值,就不再深究了。但在这个实例里,我们可以再深入一点。
Dota2 gamepedia( http://dota2.gamepedia.com/Dota_2_Wiki)给每个英雄都赋予了一系列角色属性。虽然这个属性有待商榷,而且在打完补丁之后有的英雄可能会从辅助变成核心,但是这仍然可以作为一个不错的出发点。
现在,我们已经为接下来的分析做好准备了。回想一下之前我们已经用50个数字来刻画每个英雄了,并且从dota2 gamepedia网站中也有了每个英雄对应的角色属性。
我们想验证向量维度和英雄的角色属性之间是否有一定的联系。有很多方法可以实现,但可能最简单的方式就是使用Logistic回归了。
为了能得到稀疏集,我们使用L1范数规则化。
结果如下图所示:
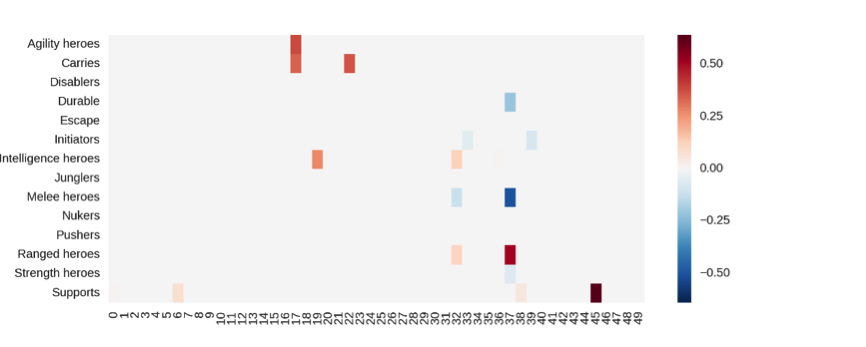
这幅图又意味着什么呢?我们可以看到第46个向量和“辅助”有很强的相关性,第38个向量和“远程英雄”联系紧密。下图是所有英雄第38和第46个向量值的散点图:
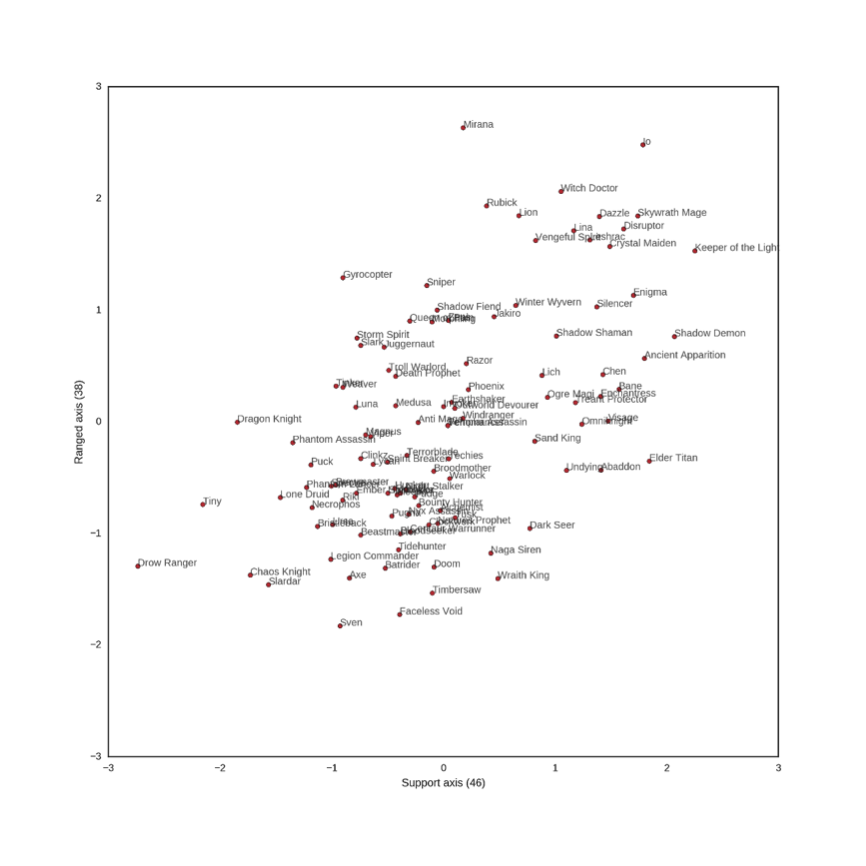
可以看出第46个向量值大的英雄很可能是辅助英雄。相似地,第38个向量值大的英雄很可能是具备远程攻击的能力。当然,你可能注意到这两个向量似乎有点相关(虽然相关性并不是那么强),不过这也正好与辅助英雄往往能够远程攻击的情况相符。上图也将不朽尸王、上古巨神、亚巴顿这些近战支援(辅助属性高,远程属性低)的英雄正确识别出来了,但卓尔游侠的向量值却和角色属性不符,小骷髅克林克兹也几乎被判断成了一个近战核心英雄(图中其第38和46个向量值都不高,与事实不太相符)。
5. 结论:
一旦涉及到计算机领域,每次英雄的选派都可以看作是没有实际意义的随机序列,但是从这里出发,却能得到可以被较好解释的信息。因此,在训练这些向量值时,我们并没有使用任何从Dota2得到的英雄属性信息。
我们可以将Dota2英雄的选派看作是我们不会说的一门外语。通过观察这些词的使用模式,找出词意相近的词语。
进一步地,通过连接在无监督学习下得到的分类特征,我们能够解释这些潜在属性。

原文链接: http://federicov.github.io/category/machine-learning.html
原文作者:Federico Vaggi
译者:Vector
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

