计算机程序的思维逻辑(49):剖析 LinkedHashMap
查看历史文章,请点击上方链接关注公众号。
之前我们介绍了Map接口的两个实现类HashMap和TreeMap,本节来介绍另一个实现类LinkedHashMap。它是HashMap的子类,但可以保持元素按插入或访问有序,这与TreeMap按键排序不同。
按插入有序容易理解,按访问有序是什么意思呢?这两个有序有什么用呢?内部是怎么实现的呢?本节就来探讨这些问题。从用法开始。
用法
基本概念
LinkedHashMap是HashMap的子类,但内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于这个双向链表中。
LinkedHashMap支持两种顺序,一种是插入顺序,另外一种是访问顺序。
插入顺序容易理解,先添加的在前面,后添加的在后面,修改操作不影响顺序。
访问顺序是什么意思呢?所谓访问是指get/put操作,对一个键执行get/put操作后,其对应的键值对会移到链表末尾,所以,最末尾的是最近访问的,最开始的最久没被访问的,这种顺序就是访问顺序。
LinkedHashMap有五个构造方法,其中四个都是按插入顺序,如下所示:
public LinkedHashMap()
public LinkedHashMap(int initialCapacity)
public LinkedHashMap(int initialCapacity, float loadFactor)
public LinkedHashMap(Map<? extends K, ? extends V> m)
只有一个构造方法,可以指定按访问顺序,如下所示:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder)
其中参数accessOrder就是用来指定是否按访问顺序,如果为true,就是访问顺序。
下面,我们通过一些简单的例子来看下。
按插入有序
默认情况下,LinkedHashMap是按插入有序的,我们来看代码:
Map<String,Integer> seqMap = new LinkedHashMap<>();
seqMap.put("c", 100);
seqMap.put("d", 200);
seqMap.put("a", 500);
seqMap.put("d", 300);
for(Entry<String,Integer> entry : seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
键是按照"c", "d", "a"的顺序插入的,修改"d"的值不会修改顺序,所以输出为:
c 100
d 300
a 500
什么时候希望保持插入顺序呢?
Map经常用来处理一些数据,其处理模式是,接受一些键值对作为输入,处理,然后输出,输出时希望保持原来的顺序。比如一个配置文件,其中有一些键值对形式的配置项,但其中有一些键是重复的,希望保留最后一个值,但还是按原来的键顺序输出,LinkedHashMap就是一个合适的数据结构。
再比如,希望的数据模型可能就是一个Map,但希望保持添加的顺序,比如一个购物车,键为购买项目,值为购买数量,按用户添加的顺序保存。
另外一种常见的场景是,希望Map能够按键有序,但在添加到Map前,键已经通过其他方式排好序了,这时,就没有必要使用TreeMap了,毕竟TreeMap的开销要大一些。比如,在从数据库查询数据放到内存时,可以使用SQL的order by语句让数据库对数据排序。
按访问有序
我们来看按访问有序的例子,代码如下:
Map<String,Integer> accessMap = new LinkedHashMap<>(16, 0.75f, true);
accessMap.put("c", 100);
accessMap.put("d", 200);
accessMap.put("a", 500);
accessMap.get("c");
accessMap.put("d", 300);
for(Entry<String,Integer> entry : accessMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
每次访问都会将该键值对移到末尾,所以输出为:
a 500
c 100
d 300
什么时候希望按访问有序呢?一种典型的应用是LRU缓存,它是什么呢?
LRU缓存
缓存是计算机技术中一种非常有用的技术,是一个通用的提升数据访问性能的思路,一般用来保存常用的数据,容量较小,但访问更快,缓存是相对而言的,相对的是主存,主存的容量更大、但访问更慢。缓存的基本假设是,数据会被多次访问,一般访问数据时,都先从缓存中找,缓存中没有再从主存中找,找到后,再放入缓存,这样,下次如果再找相同数据,访问就快了。
缓存用于计算机技术的各个领域,比如CPU里有缓存,有一级缓存、二级缓存、三级缓存等,一级缓存非常小、非常贵、也非常快,三级缓存则大一些、便宜一些、也慢一些,CPU缓存是相对于内存而言,它们都比内存快。内存里也有缓存,内存的缓存一般是相对于硬盘数据而言的。硬盘也可能是缓存,缓存网络上其他机器的数据,比如浏览器访问网页时,会把一些网页缓存到本地硬盘。
LinkedHashMap可以用于缓存,比如缓存用户基本信息,键是用户Id,值是用户信息,所有用户的信息可能保存在数据库中,部分活跃用户的信息可能在缓存。
一般而言,缓存容量有限,不能无限存储所有数据,如果缓存满了,当需要存储新数据时,就需要一定的策略将一些老的数据清理出去,这个策略一般称为替换算法。LRU是一种流行的替换算法,它的全称是Least Recently Used,最近最少使用,它的思路是,最近刚被使用的很快再次被用的可能性最高,而最久没被访问的很快再次被用的可能性最低,所以被优先清理。
使用LinkedHashMap,可以非常容易的实现LRU缓存,默认情况下,LinkedHashMap没有对容量做限制,但它可以容易的做的,它有一个protected方法,如下所示:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
在添加元素到LinkedHashMap后,LinkedHashMap会调用这个方法,传递的参数是最久没被访问的键值对,如果这个方法返回true,则这个最久的键值对就会被删除。LinkedHashMap的实现总是返回false,所有容量没有限制,但子类可以重写该方法,在满足一定条件的情况,返回true。
下面就是一个简单的LRU缓存的实现,它有一个容量限制,这个限制在构造方法中传递,代码是:
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private int maxEntries;
public LRUCache(int maxEntries){
super(16, 0.75f, true);
this.maxEntries = maxEntries;
}
@Override
protected boolean removeEldestEntry(Entry<K, V> eldest) {
return size() > maxEntries;
}
}
这个缓存可以这么用:
LRUCache<String,Object> cache = new LRUCache<>(3);
cache.put("a", "abstract");
cache.put("b", "basic");
cache.put("c", "call");
cache.get("a");
cache.put("d", "call");
System.out.println(cache);
限定缓存容量为3,先后添加了4个键值对,最久没被访问的键是"b",会被删除,所以输出为:
{c=call, a=abstract, d=call}
实现原理
理解了LinkedHashMap的用法,下面我们来看其实现代码。关于代码,我们说明下,本系列文章,如果没有额外说明,都是基于JDK 7的。
内部组成
LinkedHashMap是HashMap的子类,内部增加了如下实例变量:
private transient Entry<K,V> header;
private final boolean accessOrder;
accessOrder表示是按访问顺序还是插入顺序。header表示双向链表的头,它的类型Entry是一个内部类,这个类是HashMap.Entry的子类,增加了两个变量before和after,指向链表中的前驱和后继,Entry的完整定义为:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
recordAccess和recordRemoval是HashMap.Entry中定义的方法,在HashMap中,这两个方法的实现为空,它们就是被设计用来被子类重写的,在put被调用且键存在时,HashMap会调用Entry的recordAccess方法,在键被删除时,HashMap会调用Entry的recordRemoval方法。
LinkedHashMap.Entry重写了这两个方法,在recordAccess中,如果是按访问顺序的,则将该节点移到链表的末尾,在recordRemoval中,将该节点从链表中移除。
了解了内部组成,我们来看操作方法,先看构造方法。
构造方法
在HashMap的构造方法中,会调用init方法,init方法在HashMap的实现中为空,也是被设计用来被重写的。LinkedHashMap重写了该方法,用于初始化链表的头节点,代码如下:
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
header被初始化为一个Entry对象,前驱和后继都指向自己,如下图所示:
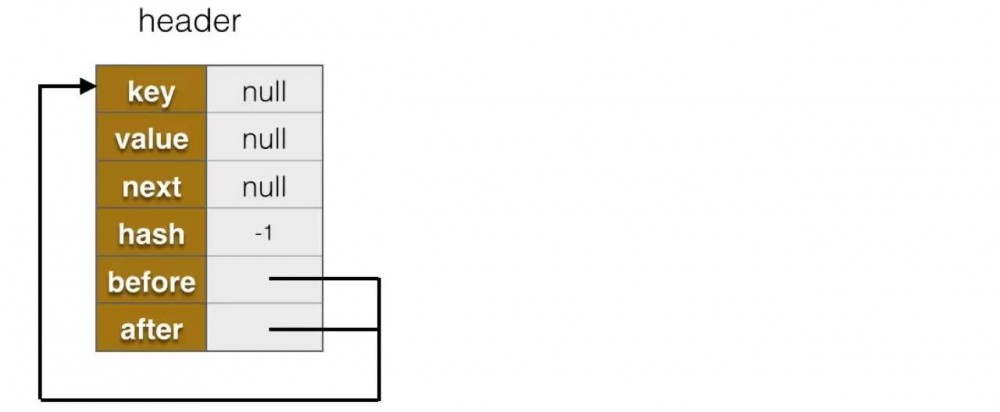 header.after指向第一个节点,header.before指向最后一个节点,指向header表示链表为空。
header.after指向第一个节点,header.before指向最后一个节点,指向header表示链表为空。
put方法
在LinkedHashMap中,put方法还会将节点加入到链表中来,如果是按访问有序的,还会调整节点到末尾,并根据情况删除最久没被访问的节点。
HashMap的put实现中,如果是新的键,会调用addEntry方法添加节点,LinkedHashMap重写了该方法,代码为:
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
它先调用父类的addEntry方法,父类的addEntry会调用createEntry创建节点,LinkedHashMap重写了createEntry,代码为:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
新建节点,加入哈希表中,同时加入链表中,加到链表末尾的代码是:
e.addBefore(header)
比如,执行如下代码:
Map<String,Integer> countMap = new LinkedHashMap<>();
countMap.put("hello", 1);
执行后,图示结构如下:
 添加完后,调用removeEldestEntry检查是否应该删除老节点,如果返回值为true,则调用removeEntryForKey进行删除,removeEntryForKey是HashMap中定义的方法,删除节点时会调用HashMap.Entry的recordRemoval方法,该方法被LinkedHashMap.Entry重写了,会将节点从链表中删除。
添加完后,调用removeEldestEntry检查是否应该删除老节点,如果返回值为true,则调用removeEntryForKey进行删除,removeEntryForKey是HashMap中定义的方法,删除节点时会调用HashMap.Entry的recordRemoval方法,该方法被LinkedHashMap.Entry重写了,会将节点从链表中删除。
在HashMap的put实现中,如果键已经存在了,则会调用节点的recordAccess方法,LinkedHashMap.Entry重写了该方法,如果是按访问有序,则调整该节点到链表末尾。
get方法
LinkedHashMap重写了get方法,代码为:
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
与HashMap的get方法的区别,主要是调用了节点的recordAccess方法,如果是按访问有序,recordAccess调整该节点到链表末尾。
查看是否包含某个值
查看HashMap中是否包含某个值需要进行遍历,由于LinkedHashMap维护了单独的链表,它可以使用链表进行更为高效的遍历,containsValue的代码为:
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}
代码比较简单,就不解释了。
原理小结
以上就是LinkedHashMap的基本实现原理,它是HashMap的子类,它的节点类LinkedHashMap.Entry是HashMap.Entry的子类,LinkedHashMap内部维护了一个单独的双向链表,每个节点即位于哈希表中,也位于双向链表中,在链表中的顺序默认是插入顺序,也可以配置为访问顺序,LinkedHashMap及其节点类LinkedHashMap.Entry重写了若干方法以维护这种关系。
LinkedHashSet
之前介绍的Map接口的实现类都有一个对应的Set接口的实现类,比如HashMap有HashSet,TreeMap有TreeSet,LinkedHashMap也不例外,它也有一个对应的Set接口的实现类LinkedHashSet。LinkedHashSet是HashSet的子类,但它内部的Map的实现类是LinkedHashMap,所以它也可以保持插入顺序,比如:
Set<String> set = new LinkedHashSet<>();
set.add("b");
set.add("c");
set.add("a");
set.add("c");
System.out.println(set);
输出为:
[b, c, a]
LinkedHashSet的实现比较简单,我们就不再介绍了。
小结
本节主要介绍了LinkedHashMap的用法和实现原理,用法上,它可以保持插入顺序或访问顺序,插入顺序经常用于处理键值对的数据,并保持其输入顺序,也经常用于键已经排好序的场景,相比TreeMap效率更高,访问顺序经常用于实现LRU缓存。实现原理上,它是HashMap的子类,但内部有一个双向链表以维护节点的顺序。
最后,我们简单介绍了LinkedHashSet,它是HashSet的子类,但内部使用LinkedHashMap。
如果需要一个Map的实现类,并且键的类型为枚举类型,可以使用HashMap,但应该使用一个专门的实现类EnumMap,为什么呢?让我们下节来探讨。
-- 长文连载,未完待续,敬请关注(点击文章头部公众号链接,或公众号搜索"老马说编程"或"laoma_shuo",或长按下图二维码关注)

用心原创,保留所有版权。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

