微博某业务数据库连续两次 oom 问题分析
ACMUG征集原创技术文章。详情请添加 A_CMUG或者扫描文末二维码关注我们的微信公众号。有奖征稿,请发送稿件至:acmug@acmug.com。
3306现金有奖征稿说明: 知识无价,劳动有偿,ACMUG特约撰稿人有奖回报计划(修订版)
作者简介: 赵晨
新浪微博高级数据库管理员,曾经在EA工作,目前在新浪微博主要负责性能优化和架构设计,目前正痴迷于MySQL,InnoDB及Kernel源代码的研究中,欢迎大家交流。

背景
微博某业务有若干机器在有突增访问的时候,两个从库的连接数不均匀。实例数少的从库与另一台,连接数比例从日常的1:1变成2:1。并且反而连接数较少的从库被OOM了。
环境
-
出现问题:
时常有抓站等原因造成瞬间大量访问,
-
OS 版本:
Centos 6.5
-
kernel版本:
2.6.32-431
-
服务器:
CPU : Intel(R) Xeon(R) CPU E5-2407 v2 @ 2.40GHz
2 * 4 core = 8 core
物理内存 64GB
-
MySQL版本:
5.5.12
-
MySQL部署情况:
-
每个端口有两个从库
-
每机器上1-2个MySQL实例,单实例buffer_pool_size设置为20G
-
分析前掌握的信息:
-
该业务有两个从库,简称A和B
-
两个从库分别在两台不同的物理机上,A从库所在机器部署了两个实例,而B所在机器上部署该业务的一个实例。
-
B从库所在机器的free内存要比A所在机器要富裕的多。
-
平常A与B的连接数均为4K多,比例1:1左右
第一次OOM,内核compact
【分析过程】
先是收到B从库的连接数报警,B从库的连接数从日常的4K涨到10K+,而A从库最低仅2K
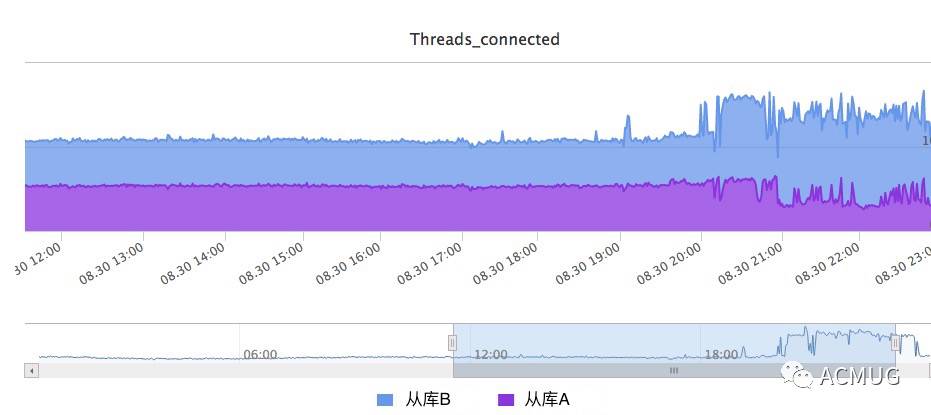
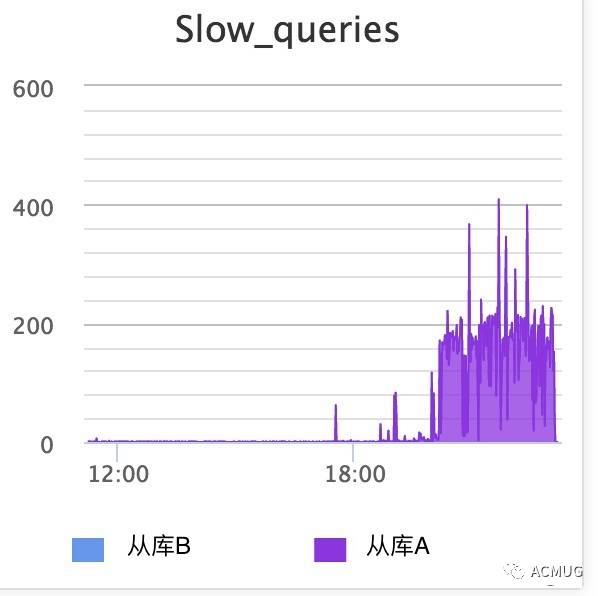
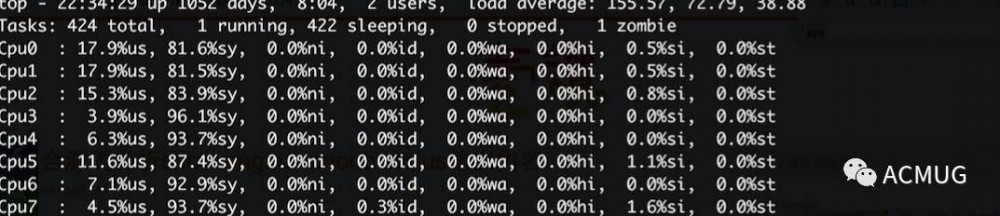
登录A从库机器,top看cpu消耗,发现sys比usr要高不少,这非常不正常
再A从库机器上利用perf看sys cpu消耗,也就是内核态cpu在做什么
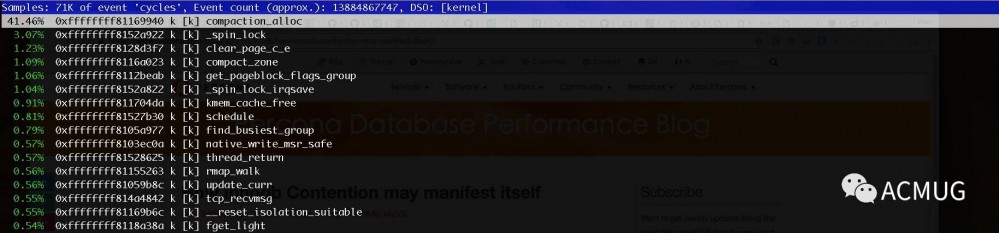
发现 compaction_alloc 这个内核函数竟然占据cpu周期近乎一半,我们看下源码这个函数的定义:
/*
* This is a migrate-callback that "allocates" freepages by taking pages
* from the isolated freelists in the block we are migrating to.
*/
static struct page *compaction_alloc(struct page *migratepage,
unsigned long data,int **result)
{ struct compact_control *cc = (struct compact_control *)data; struct page *freepage;
/* Isolate free pages if necessary */
if (list_empty(&cc->freepages)) {
isolate_freepages(cc->zone, cc);
if (list_empty(&cc->freepages))
return NULL;
}
freepage = list_entry(cc->freepages.next, struct page, lru);
list_del(&freepage->lru);
cc->nr_freepages--;
return freepage;
}
这个函数尝试在整合内存碎片,将隔离出来的空闲页从本zone内低地址移动到zone内末端。
那究竟是什么原因触发内核进行这个操作的呢?
我们需要进一步研究内核 算法。简单来说,可以理解为做的事情是重组内存中碎片,目的是整理出更大的物理上连续的区域。触发的原因会有以下原因:
-
/proc/sys/vm/compact_node 写入一个node number,会导致在指定的numa node上发生compaction
-
内核尝试分配
high-order page高阶物理内存失败,然后重组内存,将可移动的内存碎片整合在一起来获取连续的内存
(可移动的内存为用户程序访问的物理内存,对应不可移动的为内核在使用的物理内存.)
原理如图:
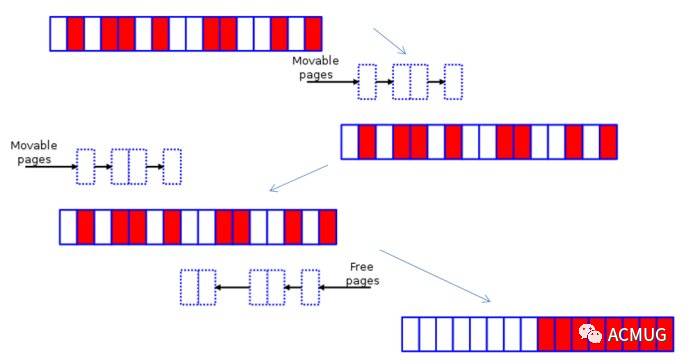
了解了原理,我们再通过perf看下 compaction_alloc 函数的调用栈:
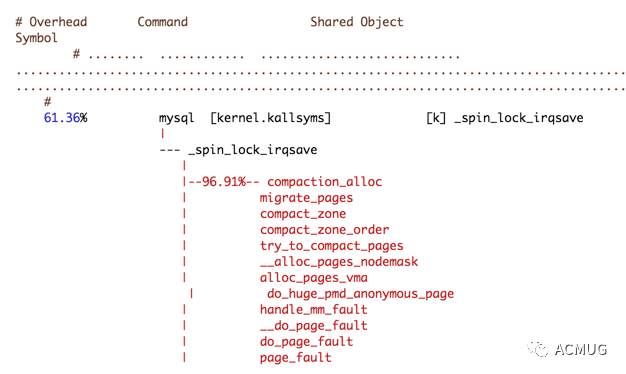
此时A从库的机器free看显示为0,MySQL尝试申请申请高阶物理内存失败,于是触发内核通过移动 可移动内存 这种方式来整理碎片,以满足MySQL内存需求,在之后的内存分配的分析中,我们也会看到这一步实际上已经进入了 内存慢速分配流程 。sys cpu花费大量的时间来进行碎片整理,MySQL被"拖"住了,threads running(不是thread connected)堆积的越来越多,qps也降低的很快,MySQL变得越来越无法响应请求。最后A从库上的MySQL实例被OOM了。至于B的连接数比A要高很多,是因为正常的时候两个从库通过域名做的负载均衡。但是出现问题的时候,请求转发到响应更快,free更充足的B上了。
调整策略:
-
禁用透明大页
echo "never" > /sys/kernel/mm/transparent_hugepage/enabled
第二次OOM,内核reclaim
【分析过程】
上次关闭透明大页之后,情况缓解了不少。有一段时间没发生过oom的问题了。直到有一次业务被抓站,接口调用增加几倍,并发连接数飙升,之上的问题再次发生,B比A连接数高了四倍,A从库的响应时间间歇性的拉长。同时A从库发现大量慢查。A从库所在的机器的sys cpu同样又飙高了。显然A从库所在服务器又“困”在了某个地方
仍然先看sys cpu高的原因,内核在做什么:
50.73% [kernel] [k] _spin_lock 2.98% libpthread-2.12.so [.] pthread_mutex_lock 2.90% libpthread-2.12.so [.] pthread_mutex_unlock 1.94% libpthread-2.12.so [.] __lll_lock_wait 1.59% [kernel] [k] futex_wake 1.43% [kernel] [k] __audit_syscall_exit 1.38% [kernel] [k] copy_user_generic_string 1.35% [kernel] [k] system_call 1.07% [kernel] [k] schedule 0.99% [kernel] [k] hash_futex
sys cpu看来大部分都消耗在 _spin_lock 上。但是内核在很多对资源的申请和释放的时候都会通过spin lock对临界资源进行保护。需要进一步分析 __spin_lock 的来源。
继续看pstack看 MySQL所有线程的调用栈:
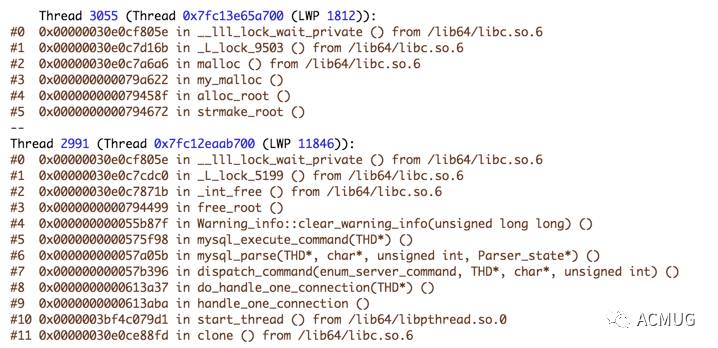
很多线程hang在了malloc()调用上,继续看
show engine innodb status 观察MySQL线程争用热点
localhost.(none)>show engine innodb status/G --Thread 140673550292736 has waited at buf0buf.c line 2766 for 0.00 seconds the semaphore: waiters flag 1--Thread 140674568324864 has waited at trx0trx.c line 1622 for 0.00 seconds the semaphore: waiters flag 1--Thread 140679185143552 has waited at buf0buf.c line 2766 for 0.00 seconds the semaphore: waiters flag 1--Thread 140672371988224 has waited at buf0buf.c line 2766 for 0.00 seconds the semaphore: waiters flag 1--Thread 140672599955200 has waited at buf0buf.c line 2766 for 0.00 seconds the semaphore: waiters flag 1--Thread 140673035118336 has waited at trx0trx.c line 1622 for 0.00 seconds the semaphore: waiters flag 1--Thread 140672392488704 has waited at trx0trx.c line 207 for 0.00 seconds the semaphore: waiters flag 1--Thread 140674877961984 has waited at trx0trx.c line 1622 for 0.00 seconds the semaphore: waiters flag 1略
找到对应的源码,上面这些线程是在竞争 kernel_mutex ,并且 waiters flag 为1,说明这些线程都在等待持有 kernel_mutex 的线程释放mutex,那MySQL的这个 kernel_mutex 跟我们perf看到os kernel的 __spin_lock 调用有什么关系呢?
InnoDB线程同步机制
我们知道linux线程同步有Mutex,spin lock,条件变量,rw lock等多种同步机制,InnoDB并没有直接使用系统的同步机制,而是自己定义了互斥结构数据结构 kernel_mutex ,将系统的spin lock,mutex,和条件变量融合一起
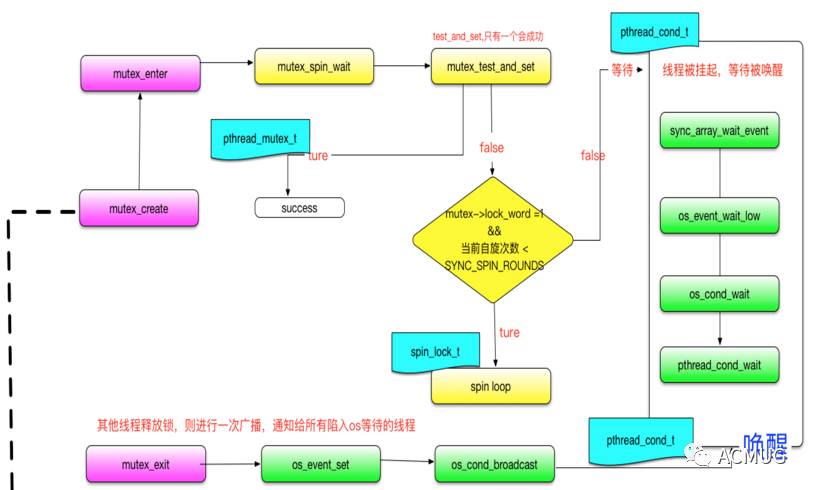

如图, kernel_mutex mutex对象的中重要的结构成员为os_event和lock_word。
-
kernel_mutex主要涉及mutex_create,mutex_enter,mutex_exit函数,会分别使用glibc的malloc()和free()调用动态分配和释放内存 -
封装mutex和条件变量,图中绿色框区域
MySQL线程之间发送异步信号来进行同步主要通过
os_event_struct结构体中的os_mutex(封装os的pthread_mutex_t)和cond_var(封装os的pthread_cond_t)成员对象实现。当InnoDB在获取锁的时候,首先先努力自旋一段时间,如果超过innodb_sync_spin_loops的阈值,就会通过函数os_event_wait_low()在os_event_struct->cond_var上等待。如图,当某个线程释放了锁的时候,通过os_cond_broadcast尝试发送广播唤醒所有等待os_event_struct->cond_var条件变量的线程.这些线程被唤醒后又继续竞争争抢os_event_struct->os_mutex -
spin lock,图中黄色框区域
通过lock_word做spin wait。线程想要争抢锁的时候先判断这个值,如果
lock_word为1就继续自旋等待。如果发现其他线程释放了锁该值变为0的时候,就通过test_and_set改为1,"告诉"其他线程这把锁被持有了
InnoDB这样设计的目的都是延缓线程被挂起并进入os wait的速度,因为每一次进入os wait等待被唤醒或者唤醒都会进行一次上下文切换.但是也只能是延缓,并不能阻止,如果持续恶化得不到环境,最后仍然会进入os的等待队列,将会产生大量的上下文切换。但是有两个问题:
-
kernel_mutex是个全局锁,保护事务,buffer pool,锁,等InnoDB存储引擎实现的大部分对象.当MySQL突然有大量访问,并发一旦非常高的时候,mutex冲突非常剧烈,此时临界区变得非常大,同时也会浪费cpu很多时间空转。所以这也解释了sys cpu大量消耗在自选空转中 -
并且并发高的时候会频繁调用
malloc()申请内存,而glibc本身的malloc()本书频繁调用系统mutex_lock()和unlock(),在多线程高并发场景下并且资源不足的场景下,也会造成系统各种mutex竞争严重。大量线程被挂起等待ospthread_cond_broadcast广播被唤醒,随之而来的是大量的上下文切换
通过dstat看到此时cpu每秒有近20W次的上下文切换,综上所述,sys cpu负载高主要以下:
-
(1)cpu内核态spin,大量线程cpu在内核态自旋等待
-
(2)系统上下文切换,又分为:
-
spin仍然失败的,最终进入os wait,调用
pthread_cond_wait等待条件满足时被唤醒 -
malloc()频繁加减os mutex,且系统内存紧张
numa机制内存分配策略对竞争的影响
我们继续观察内存分配使用的情况.
sar -B 看内存页回收,其中 pgscank/s ,对应kswapd回收, pgscand/s 对应的MySQL线程直接回收
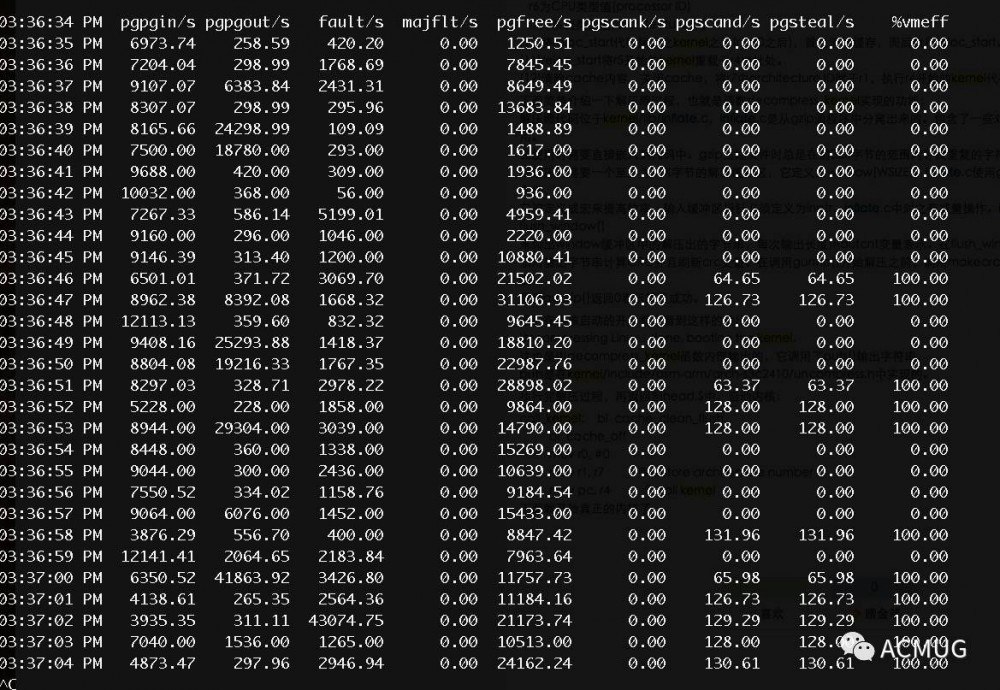
pgscand/s 不为0,说明内存资源紧张,MySQL直接回收内存。
可是free命令看内存free并没有用光。经过一番调查发现是numa搞的鬼
用 numactl --hardware 命令看:
available: 2 nodes (0-1) node 0 cpus: 0 1 2 3node 0 size: 32733 MB node 0 free: 1900 MB node 1 cpus: 4 5 6 7node 1 size: 32768 MB node 1 free: 20 MB node distances: node 0 1 0: 10 20 1: 20 10
虽然内存整体free没有用光,但是在numa默认的内存分配机制下,内存使用严重不均,node0还十分充足,但是node1几乎用光
如果node1可用内存已经用光,之下来会发生什么?
资源严重不足下内存的慢速回收流程
先简单说下内存的回收机制分为:
-
内核态进程回收 (kswapd)
-
用户态的进程直接回收 (__alloc_pages_direct_reclaim)
perf top 看此时cpu cycles:
Samples: 657K of event 'cycles', Event count (approx.): 112241881, DSO: [kernel] 63.70% [k] alloc_pages_current 36.01% [k] __alloc_pages_nodemask 0.25% [k] alloc_pages_vma 0.04% [k] __alloc_pages_direct_reclaim
调用栈路径如下:
| |--52.11%-- get_page_from_freelist
| | __alloc_pages_direct_reclaim
| | __alloc_pages_slowpath
| | __alloc_pages_nodemask
| | alloc_pages_current
| | pte_alloc_one
| | __pte_alloc
.........略.....
我们看下慢速分配直接回收内存路径:
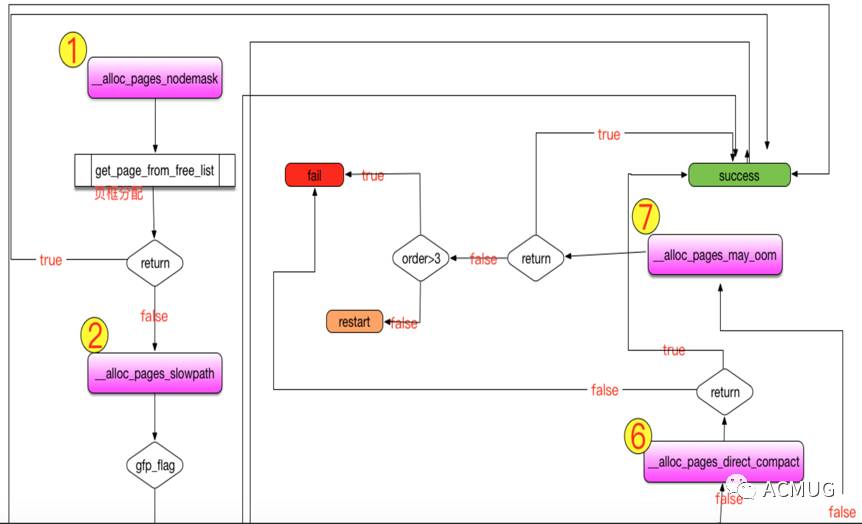
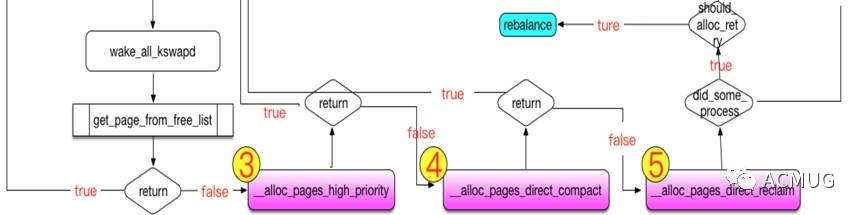
我们看到大量的用户态进程直接回收,已经到了图中5的位置,此时分配内存已经相当困难,
__alloc_pages_direct_reclaim
函数主要调用try_to_free_pages回收一些最近很少用的page cache中的页面。另外try_to_free_pages函数也会唤醒内核pdflush线程回写磁盘,增加sys cpu load。
之后还是再次努力的调用get_page_from_freelist尝试分配,如果还是失败,就到了最艰难的时刻:检查
oom_killer_disabled
参数设置,如果oom_killer并没有禁用则进入
__alloc_pages_may_oom
流程.
最终,A从库上的实例挂掉了,我们在看message日志看到了OOM的信息
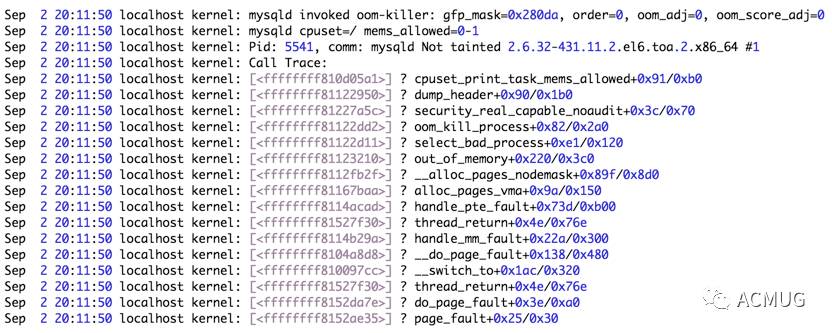
至于kernel关于oom的流程及选择策略之后也会写一篇专门介绍,这里不再展开
另外通过研究慢速流程发现:除了直接回收内存,也会通过 __alloc_pages_direct_compact 整合碎片以获得更大的连续内存,也就是第一次OOM发生的直接原因。
至此整个过程,我们总结sys高不是单一因素造成,是一系列因素相互作用导致。
总体路径如下:
numa机制->部分node free不足-> 并发导致资源竞争—> 内存回收进入慢速回收->compact or reclaim ->oom 流程
调整策略
-
关于numa机制
-
关闭numa特性 (BIOS中关闭或者os关闭)
-
mysqld_safe文件中调整启动参数,numa内存分配策略调整为interleave
-
保证充足的free内存
增大这以上内核参数的值,测试加起来2G够用
-
vm.min_free_bytes系统留给kernel的内存,小于这个值发生直接回收 -
vm.extra_free_bytes系统留给应用的free内存,避免突发访问kswapd回收不及时
-
内存管理上
-
glibc库的malloc()在高并发多线程场景下频繁分配和释放内存,会造成频繁加解锁。是性能上的杀器。建议换成jemalloc()或者google的tcmalloc()
-
MySQL 参数调整
-
innodb_thread_concurrency = 32
5.5默认值为0,不限制。但是目前上述DB并发较高,进入innodb层的事务线程过多,并发过大会恶化资源竞争,同时增加CPU SYS的消耗
-
innodb_sync_spin_loops 微调
默认值30,自旋锁和上下文切换的平衡,也就是spin wait和os wait的平衡,增大此值会延缓进入os wait的时间,如果系统上下文切换已经 非常大了,可适当增大此值,让线程在进入os wait之前再多spin一段时间
-
innodb_spin_wait_delay = 12 微调
默认值6,如果context switch非常高,可以增加此值,但不需要加的太多,因为我们的cpu比较挫(2个物理cpu,每个4核)
-
降低MySQL被OOM_killer干掉的可能
-
echo -15 > /proc/{pidof mysqld}/oom_adj
-
升级MySQL版本
-
kernel_mutex是个全局mutex,5.5版本中,kernel_mutex保护的资源过多,包括事务,锁,日志,buffer pool等等都通过这个mutex保护,一旦并发访问上来,性能会下降的非常厉害。在5.6中已对该mutex进行了拆分,提高了并发的性能
注:ACMUG收录技术文章版权属于原作者本人所有。如有疑问,请联系作者。
看完转发,手留余香。关注我们,一起进步。
关注ACMUG公众号,参与社区活动,交流开源技术,分享学习心得,一起共同进步。

正文到此结束
- 本文标签: cache 端口 swap UI 域名 开源 ask Action 源码 map 时间 总结 core message 测试 负载均衡 sql 需求 锁 src 微信公众号 服务器 struct centos 代码 参数 lib mysql ip cat Google 二维码 dist IOS id linux cpu负载 进程 多线程 list 回报 文章 物理内存 db 线程 管理 实例 同步 Word IO node 数据库 数据 App 微博 http
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

