Strom nimbus HA summary
Strom nimbus HA summary
解决问题:
nimbus 单点故障问题
nimbus HA部署方式:
- 假设原有nimbus为A,相关配置为(storm.yaml):nimbus.seeds:[“A”],现在增加B机器作为nimbus HA
- 将所有机器的配置改为:nimbus.seeds: [ “A”,”B”]
-
重启节点,重启顺序如下:
- 重启nimbus A
- 重启ui
- 启动nimbus B
- 重启所有supervisor
-
观察ui上,是否有两个nimbus节点,如图所示,则成功:

storm命令访问nimbus过程
- storm命令可以在任何一台集群节点上执行
- 在linux上,storm命令调用storm.py,拼接Java命令启动Java执行(windows上调用storm.bat拼接命令)。
- Java命令调用nimbusClient。
- nimbusClient读取本地配置文件(storm.yaml),读取其中的nimbus.seeds配置
- nimbusClient依次访问nimbus.seeds中的节点,如果超时则重试连接下一个。
for (String host : seeds) {
int port = Integer.parseInt(conf.get(Config.NIMBUS_THRIFT_PORT).toString());
ClusterSummary clusterInfo;
try {
NimbusClient client = new NimbusClient(conf, host, port, null, asUser);
clusterInfo = client.getClient().getClusterInfo();
} catch (Exception e) {
LOG.warn("Ignoring exception while trying to get leader nimbus info from " + host
+ ". will retry with a different seed host.", e);
continue;
}
...
}
- 获取到所有存活的nimbus节点,依次检测它们是否为leader,如果是,则连接。
List<NimbusSummary> nimbuses = clusterInfo.get_nimbuses();
if (nimbuses != null) {
for (NimbusSummary nimbusSummary : nimbuses) {
if (nimbusSummary.is_isLeader()) {
try {
return new NimbusClient(conf, nimbusSummary.get_host(), nimbusSummary.get_port(), null, asUser);
} catch (TTransportException e) {
String leaderNimbus = nimbusSummary.get_host() + ":" + nimbusSummary.get_port();
throw new RuntimeException("Failed to create a nimbus client for the leader " + leaderNimbus, e);
}
}
}
throw new NimbusLeaderNotFoundException(
"Found nimbuses " + nimbuses + " none of which is elected as leader, please try " +
"again after some time.");
}
- 如果找不到leader,则抛出异常:
NimbusLeaderNotFoundException
nimbus HA文档过期
nimbus HA文档地址
文档中主要部分基本符合目前的代码实现,但 Nimbus state store 一节基本与目前实现不一致。文档中写道,Nimbus之间的状态同步主要靠实现 ICodeDistributor 接口实现,并且有 LocalFileSystemCodeDistributor 和 HDFSCodeDistributor 两个实现,默认是 LocalFileSystemCodeDistributor 。但目前代码(1.0.1)中,全面使用了 BlobStore 来实现nimbus以及supervisor之间的jar包同步,默认为 LocalFsBlobStore ,也有 HdfsBlobStore 。 Configuration 一节中的相关配置项也要做相应更改,原有配置并没有删除,但是已经没有使用,除此之外nimbus.min.replication.count这个配置项也没有使用。
nimbus HA任务提交过程
- 前文提到,nimbusClient会检测哪个nimbus是leader,会自动连接Leader Nimbus。Nimbus的各个操作之前会调用 is-leader 检查自身是否是Leader,如果不是则抛出异常。
- nimbus接受到submit请求后,会检查各个nimbus之间的jar包的同步情况,调用函数: wait-for-desired-code-replication ,等待代码在各个nimbus之间同步。topology.min.replication.count默认值为1,表示要等待多少个nimbus获取到副本之后才能开始调度任务。
- nimbus有后台进程同步代码,nimbus.code.sync.freq.secs表示同步频率,默认为60s。 代码会最终同步到各个nimbus上。
-
任务发布的可能时长:
- 如果 topology.min.replication.count =1 则立刻发布
- 如果 topology.max.replication.wait.time.sec >=0 则等待最长topology.max.replication.wait.time.sec时间。
- 如果 topology.max.replication.wait.time.sec <0,且topology.min.replication.count>1则最长等待 2*nimbus.code.sync.freq.secs
(存疑)。
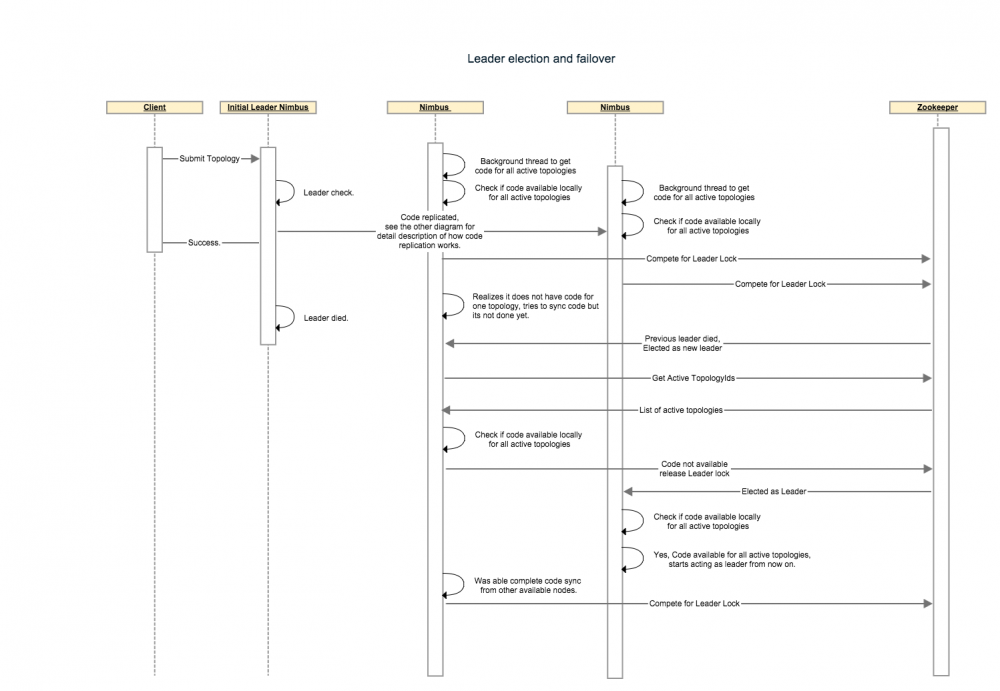
nimbus选举及容错机制
- 启动时检查本地是否都有全部的jar信息,如果有,则调用addToLeaderLockQueue将nimbus加入到可以加入作为leader的列表中。
- 当nimbus 退出时,其他nimbus节点使用curator的LeaderLatch机制获取到leadeShip。
- nimbus进行每一步必要的操作时,都会检查是否有leadership。
- 图中和文档中提到,Leader只会分配给有所有代码的nimbus,但是在1.0.1的代码中,不会执行这一检查。没有所有代码的Nimbus也会获取到Leadership,同时 removeFromLeaderLockQueue 方法没有得到任何的调用。 STORM-1977
none_leader节点启动后杀死topology问题
-
Nimbus启动时,会调用 cleanup-corrupt-topologies! 函数,该函数会:
- 读取本地存在的jar包
- 读取zk上active的topology
- 对比两者,zk上存在但本地不存在的认为是corrupt-topology
- 杀死corrupt-topology
- 由于nimbusHA机制,新启动的nimbus肯定没有在leader节点上发布的topology,所有topology都会被杀死。
- 这是早期的遗留代码,1.0.2中已经完全移除这个函数。 STORM-1976
其他
- 集群在进行nimbus选举期间(主要是故障nimbus重新上线过程中),会出现短时间不稳定现象,可能有发布或杀死任务失败的情况,过一会儿重试即可。
- 由于nimbusClient访问nimbus时,是从nimbus.seeds配置中,依次读取,当列表中前面有nimbus无法访问时,从VRC上操作会返回如下warning:
 该warning是正常现象,是访问不存在的nimbus时出现的超时现象,会自动选取下一个nimbus访问。但由于存在超时等待的问题,速度较慢,时间较长,为减少任务操作时间, 建议保证nimbus.seeds中第一个节点可用。如nimbus.seeds:[“A”,”B”]中A节点长时间不可用,请调整配置为nimbus.seeds:[”B”, “A”]
该warning是正常现象,是访问不存在的nimbus时出现的超时现象,会自动选取下一个nimbus访问。但由于存在超时等待的问题,速度较慢,时间较长,为减少任务操作时间, 建议保证nimbus.seeds中第一个节点可用。如nimbus.seeds:[“A”,”B”]中A节点长时间不可用,请调整配置为nimbus.seeds:[”B”, “A”]
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

