Quartz集群实战及原理解析
选Quartz的团队基本上是冲着Quartz本身实现的集群去的, 不然JDK自带Timer就可以实现相同的功能, 而Timer存在的单点故障是生产环境上所不能容忍的。 在自己造个有负载均衡和支持集群(高可用、伸缩性)的调度框架又影响项目的进度, 所以大多数团队都直接使用了Quartz来作为调度框架。
一、 Quartz集群的架构图:
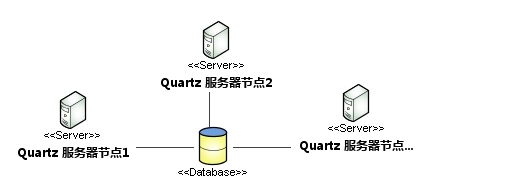
二、 Quartz集群配置:
<!-- 调度任务 -->
<bean id="jobDetail"
class="org.springframework.scheduling.quartz.JobDetailFactoryBean">
<property name="jobClass" value="全类名" />
<property name="durability" value="true"/>
<property name="targetMethod" value="execute" />
<property name="concurrent" value="true" /> -->
<!-- <property name="shouldRecover" value="true" /> -->
</bean>
<!-- 调度工厂 -->
<bean id="scheduler" lazy-init="false" autowire="no"
class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<!-- 注册JobDetails -->
<property name="jobDetails">
<list>
<ref bean="jobDetail"/>
</list>
</property>
<!--可选,QuartzScheduler 启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了 -->
<property name="overwriteExistingJobs" value="true"/>
<!-- 属性 -->
<property name="quartzProperties">
<props>
<!-- 集群要求必须使用持久化存储 -->
<prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreCMT</prop>
<prop key="org.quartz.scheduler.instanceName">EventScheduler</prop>
<!-- 每个集群节点要有独立的instanceId -->
<prop key="org.quartz.scheduler.instanceId">AUTO</prop>
<!-- Configure ThreadPool -->
<prop key="org.quartz.threadPool.class">org.quartz.simpl.SimpleThreadPool</prop>
<prop key="org.quartz.threadPool.threadCount">50</prop>
<prop key="org.quartz.threadPool.threadPriority">5</prop>
<prop key="org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread">true</prop>
<!-- Configure JobStore -->
<prop key="org.quartz.jobStore.misfireThreshold">60000</prop>
<prop key="org.quartz.jobStore.driverDelegateClass">org.quartz.impl.jdbcjobstore.StdJDBCDelegate</prop>
<prop key="org.quartz.jobStore.tablePrefix">SCHEDULER_</prop>
<prop key="org.quartz.jobStore.maxMisfiresToHandleAtATime">10</prop>
<!-- 开启集群 -->
<prop key="org.quartz.jobStore.isClustered">true</prop>
<prop key="org.quartz.jobStore.clusterCheckinInterval">20000</prop>
<prop key="org.quartz.jobStore.dontSetAutoCommitFalse">true</prop>
<prop key="org.quartz.jobStore.txIsolationLevelSerializable">false</prop>
<prop key="org.quartz.jobStore.dataSource">myDS</prop>
<prop key="org.quartz.jobStore.nonManagedTXDataSource">myDS</prop>
<prop key="org.quartz.jobStore.useProperties">false</prop>
<!-- Configure Datasources -->
<prop key="org.quartz.dataSource.myDS.driver">com.mysql.jdbc.Driver</prop>
<prop key="org.quartz.dataSource.myDS.URL">${db.url}</prop>
<prop key="org.quartz.dataSource.myDS.user">${db.username}</prop>
<prop key="org.quartz.dataSource.myDS.password">${db.password}</prop>
<prop key="org.quartz.dataSource.myDS.maxConnections">10</prop>
<prop key="org.quartz.dataSource.myDS.validationQuery">select 0 from dual</prop>
</props>
</property>
<property name="applicationContextSchedulerContextKey" value="applicationContext" />
</bean>
三、 集群源码分析
Quartz如何保证多个节点的应用只进行一次调度(即某一时刻的调度任务只由其中一台服务器执行)?
正如上面架构图所示, Quartz的集群是在同一个数据库下, 由数据库的数据来确定调度任务是否正在执行, 正在执行则其他服务器就不能去执行该行调度数据。 这个跟很多项目是用Zookeeper做集群不一样, 这些项目是靠Zookeeper选举出来的的服务器去执行, 可以理解为Quartz靠数据库选举一个服务器来执行。
如果之前看过这篇 Quartz按时启动原理 就应该了解到Quartz最主要的一个类QuartzSchedulerThread职责是触发任务, 是一个不断运行的Quartz主线程, 还是从这里入手了解集群原理。
集群配置里面有一个配置项:
<prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreCMT</prop>
源码可以看到JobStoreCMT extends JobStoreSupport, 在QuartzSchedulerThread的run方法里面调用的acquireNextTriggers、 triggersFired、 releaseAcquiredTrigger方法都进行了加锁处理。
以acquireNextTriggers为例:

而LOCK_TRIGGER_ACCESS其实就是一个Java常量
protected static final String LOCK_TRIGGER_ACCESS = "TRIGGER_ACCESS";
这个常量传入加锁的核心方法executeInNonManagedTXLock: 处理逻辑前获取锁, 处理完成后在finally里面释放锁(一种典型的同步处理方法)
protected <T> T executeInNonManagedTXLock(
String lockName,
TransactionCallback<T> txCallback, final TransactionValidator<T> txValidator) throws JobPersistenceException {
boolean transOwner = false;
Connection conn = null;
try {
if (lockName != null) {
// If we aren't using db locks, then delay getting DB connection
// until after acquiring the lock since it isn't needed.
if (getLockHandler().requiresConnection()) {
conn = getNonManagedTXConnection();
}
// 获取锁
transOwner = getLockHandler().obtainLock(conn, lockName);
}
if (conn == null) {
conn = getNonManagedTXConnection();
}
final T result = txCallback.execute(conn);
try {
commitConnection(conn);
} catch (JobPersistenceException e) {
rollbackConnection(conn);
if (txValidator == null || !retryExecuteInNonManagedTXLock(lockName, new TransactionCallback<Boolean>() {
@Override
public Boolean execute(Connection conn) throws JobPersistenceException {
return txValidator.validate(conn, result);
}
})) {
throw e;
}
}
Long sigTime = clearAndGetSignalSchedulingChangeOnTxCompletion();
if(sigTime != null && sigTime >= 0) {
signalSchedulingChangeImmediately(sigTime);
}
return result;
} catch (JobPersistenceException e) {
rollbackConnection(conn);
throw e;
} catch (RuntimeException e) {
rollbackConnection(conn);
throw new JobPersistenceException("Unexpected runtime exception: "
+ e.getMessage(), e);
} finally {
try {
// 释放锁
releaseLock(lockName, transOwner);
} finally {
cleanupConnection(conn);
}
}
}
getLockHandler那么可以思考下这个LockHandler怎么来的?
最后发现在JobStoreSupport的initail方法赋值了:
public void initialize(ClassLoadHelper loadHelper,
SchedulerSignaler signaler) throws SchedulerConfigException {
...
// If the user hasn't specified an explicit lock handler, then
// choose one based on CMT/Clustered/UseDBLocks.
if (getLockHandler() == null) {
// If the user hasn't specified an explicit lock handler,
// then we *must* use DB locks with clustering
if (isClustered()) {
setUseDBLocks(true);
}
if (getUseDBLocks()) {
...
// 在初始化方法里面赋值了
setLockHandler(new StdRowLockSemaphore(getTablePrefix(), getInstanceName(), getSelectWithLockSQL()));
} else {
getLog().info(
"Using thread monitor-based data access locking (synchronization).");
setLockHandler(new SimpleSemaphore());
}
}
}
可以在StdRowLockSemaphore里面看到:
public static final String SELECT_FOR_LOCK = "SELECT * FROM "
+ TABLE_PREFIX_SUBST + TABLE_LOCKS + " WHERE " + COL_SCHEDULER_NAME + " = " + SCHED_NAME_SUBST
+ " AND " + COL_LOCK_NAME + " = ? FOR UPDATE";
public static final String INSERT_LOCK = "INSERT INTO "
+ TABLE_PREFIX_SUBST + TABLE_LOCKS + "(" + COL_SCHEDULER_NAME + ", " + COL_LOCK_NAME + ") VALUES ("
+ SCHED_NAME_SUBST + ", ?)";
可以看出采用了悲观锁的方式对triggers表进行行加锁, 以保证任务同步的正确性。
当线程使用上述的SQL对表中的数据执行操作时,数据库对该行进行行加锁; 于此同时, 另一个线程对该行数据执行操作前需要获取锁, 而此时已被占用, 那么这个线程就只能等待, 直到该行锁被释放。
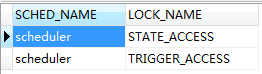
Quartz的锁存放在:
CREATE TABLE `scheduler_locks` ( `SCHED_NAME` varchar(120) NOT NULL COMMENT '调度名', `LOCK_NAME` varchar(40) NOT NULL COMMENT '锁名', PRIMARY KEY (`SCHED_NAME`,`LOCK_NAME`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
锁名和上述常量一一对应:
有可能你的任务不能支持并发执行(因为有可能任务还没执行完, 下一轮就trigger了, 如果没做同步处理可能造成严重的数据问题), 那么在任务类加上注解:
@DisallowConcurrentExecution
设置@DisallowConcurrentExecution以后程序会等任务执行完毕以后再去执行
四、 参考资料
Quartz官网: http://quartz-scheduler.org/documentation/quartz-2.x/tutorials/tutorial-lesson-11
正文到此结束
- 本文标签: final autocommit Jobs id update tar 配置 解析 锁 Word JDBCJobStore IO java map HTML REST 删除 JobStores bean spring 负载均衡 sql App list http JobDetails Action mysql db zookeeper CTO src trigger Property tab 集群 NSA value Connection Job Clustering 源码 cat IDE key dataSource JobDetail Persistence ssl 线程 数据 Select 同步 Quartz message 服务器 数据库 UI Document
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

