大数据 “迷雾” 背后的用户洞察:从用户画像到用户画像建模
分享 | 周涛(有米科技数据工程师)
整理 | 半夏
即刻 扫码 ,畅享又拍云年终 充值大优惠 !

12月17日,又拍云Open Talk再次入驻广州。此次活动Open Talk邀请了有米科技(834156.SZ)技术团队的4位大咖探讨技术领导力、大数据和用户画像、在线业务扩容的技术选型等话题。
今天小拍主要给大家整理了有米科技数据工程师周涛分享的《大数据“迷雾”后的用户洞察》,干货扎堆,赶快抓紧时间学习,让知识充实自己吧!
学习之前,先来了解一下有米科技呗~
有米科技
有米科技成立于2010年4月,是全球卓越的综合性移动互联网企业。经过6年的发展,有米科技已完成“一横多纵”的业务布局。
目前,有米科技广告板块业务包括国内广告平台“有米广告”、海外广告平台“Adxmi”以及社会化媒体营销平台“米汇”。通过海量的媒体数据积累和创新的广告投放技术,有米科技致力于为广告主提供精准的产品推广和品牌营销服务,为合作伙伴创造收益。
下面就是周涛的分享啦~
大家下午好!接下来我将和大家探讨一下大数据后面的用户画像,这次分享的内容主要分为三个部分:
-
什么是用户画像
-
为什么能对用户画像建模
-
如何对用户画像建模
什么是用户画像
什么是用户画像呢?其实它是建立在一系列真实数据之上,抽象出来的一个标签化的用户模型,构建用户画像的核心工作就是给用户打上一系列标签,标签则是通过对用户信息进行分析挖掘出来的高度精炼的特征表示。就好像如果你经常购买一些玩具玩偶,电商可能就会给你打上一个“有小孩”的标签,甚至更精准的分析出你家里的小孩是男孩还是女孩,年龄是1到3岁,还是5到10岁,这一系列的标签便构成了你的用户画像。
为什么能对用户画像建模
那我们为什么能对用户画像做一个建模呢?可以想象一个场景:周末的早上醒来后很无聊,A便拿起手机玩NBA的游戏,玩了10多分钟之后,又看了LOL的视频直播,接着A想起来今天有事要出去一趟,就起床去洗漱,然后A化妆,穿上高跟鞋……
到现在为止大家心里可能会有一个疑惑,就是A的性别到底是什么?我们想的根源可能就在于描述了上面四个动作,第一个是NBA游戏,第二个是LOL视频,接着是化妆以及穿上高跟鞋。一开始我们并没有提到A的性别,而我们在潜意识里已经开始对这个用户进行了建模。尽管我们不知道A确切是谁,叫什么名字。
同样,在计算机科学领域也可以对这种行为做一次建模,我们看一下数据流:
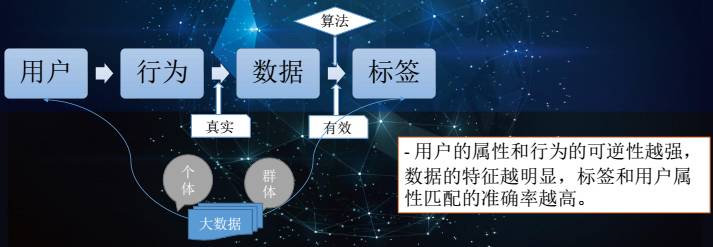 △ 用户画像的数据流
△ 用户画像的数据流
一个用户在网络媒介上做了一系列的行为,比如浏览了一些网站,下载App……这些行为都会形成数据,需要一系列的算法为它打上一个标签,我们要做的就是先给它打上一个标签,也就是对它的某一些属性做一些判断。这里就会有一个疑问,这个标签和用户真实的属性是不是一个匹配的程度呢?这是一个很重要的问题,我们来简单分析一下,一开始就拿最简单的行为来分析,一开始A玩了一个NBA的游戏,他产生了一个行为,根据这个行为,我们可能给他性别的标签打上男性,因为他潜在的模式说明用户某一方面的属性与他的行为是有很强的关联性的,也就是玩NBA的游戏和性别是男性的关联是非常强的(但是也有一些情况,比如喜欢攀岩这个标签的属性和性别的关连性就很差),所以有一些用户的一些行为和他的某一些属性的关联性非常强,就有可能产生一定的可逆,而这个可逆是我们给他打标签的基础所在。
但是有些时候,我们获得的数据特征不像刚刚说得那么明显,比如想要判断一个刚打开微信的人是男是女、多少岁显然不可能,因为他的行为只是一个中性的标签。如果很多中性的标签放在一起,有可能就是某种特别的组合。比如打开QQ,又打开微信,偏低龄化的可能性就多一些。这都是我们潜在的经验。我们通过个体的一系列数据就可以给这个个体打上比较贴切的标签,但是很多时候用一个人的数据,匹配度会比较低,这时候可以通过一个群体的整体数据来给这个个体打上标签。
我们在群体数据里面,主要是要挖掘群体后面的知识,加上我们已经有的知识来对个体进行标签的匹配,之前所说的同时打开QQ、微信可能是一个很简单、线性的潜在模式,但是很多时候我们的数据有很多很频繁的特征,很频繁的行为里就为后面隐藏了一个非线性的潜在模式数据关系。我们可以通过数据挖掘找出这种潜在模式,从而挖掘出这种个体行为与他某一种属性的关联度,这就是我们要通过大数据来挖掘出它背后非常重要、不易寻找的规律,这也是为什么用户画像和大数据关联度比较高。
回到上面的数据链,从行为到数据进行建模,首先要保证真实,因为有一些数据并不是真实的,这些行为并不是用户主动触发的,比如某些行为是通过投广告的行为来促使用户完成的,那在建模中就要剔除出去的。第二就是数据到标签这一步,要保证有效性,保证根据数据生成的标签是有用的,也就是说有一些记录,比如你只是打开一条微信消息的记录,可能这个是非常没用的,根本判断不出任何的标签,这部分记录就要把它剔除掉,这样我们就可以通过比较完美的数据进行建模。整个过程,用户的属性和行为的可逆性越强,数据的特征越明显,通过标签的算法,我们就可以找出标签和用户的属性相匹配,就可以得到标签和用户匹配度非常高的准确率。
如何对用户画像建模
数据分析
接下来以一个例子来解释刚才的整个流程,首先是数据分析。
我们有一个性别模型来预测,这个性别模型是基于App行为预测用户性别的。比如用户下载安装了一个App,我们就有可能会知道他有这个App,然后我们可以根据这个App来给他打一个标签,整个流程很简单。
这里,我们要保证这个行为的真实性。如果我们能发现这些数据,要把它用作我们的一些判断剔除掉;另外就是App到标签也要验证它的有效性,我们要从数据里挖掘后面的数据来保证数据的有效性。如果数据是无效的,模型再好,算法再精准也没有什么用,也就是说行为决定了整个预测的上限,而算法是让预测打乱这个上限,所以构建这个行为的特征是至关重要的。
特征选取
数据分析后就是特征选取,特征至关重要,它决定了整个预测和学习的上限。
我们在测试的时候,第一个选用了 one-hot特征 。
假设总共有5个App
假设用户A安装了0、1、2
用户B是0、4、5
其one-hot特征就是[1,0,0,1,1]
优点: 编码简单;基准特征
缺点:维度过高
第二个我们用了一个 类别特征 ,类别特征的初衷就是为了降低我们的维度,如果你要把一个App映射成预先分好的几十个分类,几百个分类,比如你可以把这些App预设为社交类、娱乐类等类型,那类别特征的优点就显而易见,也就是说如果你觉得哪些类别跟你的性别相关度比较高,你就完全可以设置这些类别,把它映射到这些类别里。
优点:加入先验知识,高度归纳pachage属性;降低维度
缺点:严重依赖先验知识,类别选取较依赖标签
第三个就是利用数据有一个 几率特征。
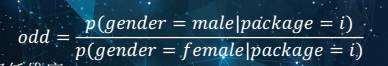
△ 几率特征
假如用户的App已经固定下来了,要计算这个App微信的几率,就可以在这批用户里统计一下男性的概率分子,再统计女性的数量作为概率,在这个App里,男女的分布就能做一个比例,就能知道这个App属于男性的几率,很明显,大于1的时候,它是偏向男性的,如果是0-1之间,则是偏向女性的。而如果你要预测其他的,比如现在要预测用户的文化程度,分了几个类,也可以用同样的方法,来知道他的分类。如果用户对标签的敏感度很低,有足够的标签就能统计出他的后验知识。
优点:后验;降低维度
缺点:support低的package的计算较为敏感
模型构建
特征选好了就确定了整个的上限在哪里,就可以用我们的模型来构建。
一个基本的构建就是 逻辑回归 ,它是一个广义的线性模型。
 △ 逻辑回归模型
△ 逻辑回归模型
我们可以看到这是它的参数,x是它的特征,我们把它的取值归到0-1,用来证明一个区间。
优点:模型简单,计算量小,可解释性强;可作为基准模型
缺点:容易欠拟合,准确率低
第二个要介绍的模型是 随机森林。
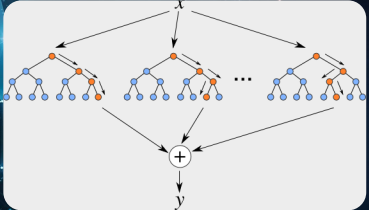 △ 随机森林模型
△ 随机森林模型
随机森林是基于决策树之上的,决策数就是根据一些属性来定的,比如头发是黑色、白色,可以分成两支。有很多的决策树,每个决策树之间存在差异,划分的属性也会有一个随机的选取。我们选取了多棵树一起来决策,举个例子,有人预测某个人是男的,有人则预测他是女的,其他预测他是男的,那其他就按照“男”这种形式,因为每一棵树之间没有关联,所以可以用并行来训练。
优点:训练速度较快;准确率高;特征排序
缺点:在噪声较大的数据中过拟合
最后采用的是 GBDT。
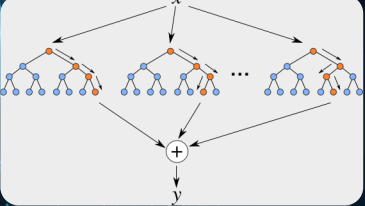 △ GBDT
△ GBDT
GBDT也是一个树的模型,但是它和随机森林模型不一样,它需要基于前一棵树,如果说随机森林模型是并行的方式,那GBDT则是串行的方式,前一棵树可能有误差,它是在这个残差的基础上再进行学习,然后一直学习下去。
优点:准确率高,适合低维稠密数据
缺点:训练速度慢
模型评估
训练好了模型,那怎么对这个模型进行评估,也就是说模型的准确率是不是就是它真实的属性呢?我们是用没有拿去训练的一部分测试来做它的准确率预估,它的准确率的最佳实验可以达到80%,也就是说10个人里8、9个基本上是正确的,然后我们拿去DSP用户定向,来提高我们的用户定向的能力,比如一部分用户是随机给它推广告,另外一部分广告就可能偏向男性,我们只给男性推广告,来提高点击率和转化率,是有一个明显的提升。
有米科技广告平台数据
最后介绍一下Youmi DMP:
-
DMP数据覆盖约20亿终端设备
-
标签覆盖5大维度、34个类目、215个细分
-
高准确率的标签算法
DMP拥有:
-
数据基础能力:ID mapping,设备信息查询
-
数据标签能力:标签查询、标签计算
-
数据营销能力:种子用户放大、垂直领域分析
关于Open Talk
又拍云Open Talk是又拍云在2014年启动的开放式主题分享沙龙,每月一期。
Open Talk秉承了又拍云帮助企业提升发展速度的初衷,组织资深、一线的工程师,用全干货分享的形态,为互联网从业人员呈现先进的IT技术、理念、解决方案,帮助与会者不断提升自身的专业技能,推动企业更快发展。
嗯哼,恭喜你看到了文末,小拍有福利要送上!
又拍云联合付钱拉、个推、兑吧、Worktile等在企业服务厂商,推出“申猴酉机大礼包”!
其中 又拍云 送出价值3000元的代金券(仅限新用户) 哦~
赶紧扫码申请 “申猴酉机大礼包” !


正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

