未来的歌,可能由人工智能包办词曲
前段时间一个热门的研究工作是 University of Toronto 的研究者在 ICLR‘17 投稿的一篇论文《Song from PI: A musically plausible network for pop music generation》( https://arxiv.org/pdf/1611.03477v1.pdf )。该论文提出了一种人工智能(深度学习)的方法,从 100 小时的 midi 音乐格式里面进行学习,然后采样训练好的模型可以生成音乐。在其项目主页上有些合成的 sample songs,大家可以听听: http://www.cs.toronto.edu/songfrompi/ 。
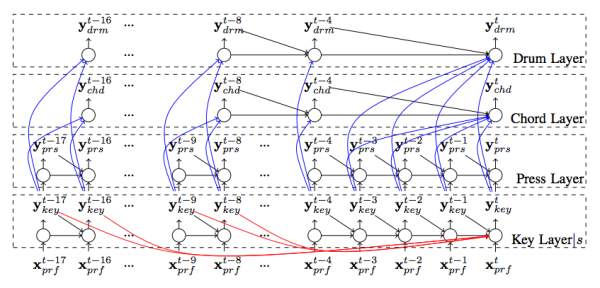
论文的大致想法是利用深度学习的 LSTM 模型(hierarchical recurrent network),利用 100 个小时的流行歌曲的 mini 格式的 tag 进行训练。这里比较有意思的地方是作者在这个模型里面整合了一些音乐相关的 general knowledge,模型结构如下图所示,在 RNN 这个模型中有 key layer, press layer, chord layer, drum layer 等结构,在模型设计和合成的过程中也考虑了 scale 和 chord 等音乐因素。这些 prior 无疑可以更好的帮助人工智能模型学习音乐中的关键元素以及常见套路。
论文里面还展示了一些应用,比如说生成音乐的过程中同时生成跳舞的小人(如下图),以及尝试用 neural image captioning 的办法生成歌词或者朗诵,这些应用都给未来提出了无限可能性。

这个研究工作的一个 media cover 比较客观的评价了这个工作,也提了一些其他 AI 音乐制作的工作,感兴趣的读者可以看看: Top of the bots: This AI isn't a cold, cruel killing machine – it's a pop music hit machine
我自己比较关注 AI 在音乐 / 声音以及多媒体的各种应用(八卦:我业余时间在乐队里弹贝斯=])。目前的 AI 技术产生的音乐还是在照猫画虎,离真正的作词作曲还有很长一段距离。也许更可行的办法是 AI-assisted music generation/composition,利用 AI 的技术来简化音乐制作的过程。比如说作者可以随意哼出一段旋律,然后 AI 自动合成和音进行和可能的曲式以及歌曲结构,然后作者可以继续在这个结构上进行创作。另一方面,歌词的生成也是完全可以通过机器学习的办法进行。另外,再看看最近的 neural style transfer( Style transfer | Gene Kogan )的惊人结果,我相信未来 AI 在绘画音乐等艺术领域有着非凡潜力和可能性。
再说个最近我发现的一个关于声音的有意思的应用:Visualizing Bird Sounds ( https://aiexperiments.withgoogle.com/bird-sounds ). 作者利用机器学习里面一个叫 t-SNE 的数据降维的方法,重新组织几百种鸟的声音,然后在二维空间可视化出来,相近的鸟的声音会聚类在一块。如下图,用户可以自由浏览不同的鸟叫,并且很直观的比较几种鸟叫之间的相似性。

结语:我心底是不太希望 AI 染指人类的各种艺术,因为它们是人类自由灵魂和创造力的结晶,但是历史洪流不可阻挡,我拭目以待:)
原文 http://daily.zhihu.com/story/9111327正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

