英语流利说后端基础组件演进

英语流利说的用户数一直保持着高速的增长,这个过程中如何保证给用户提供稳定可靠的服务一直都是一个不小的挑战,在这里用简短篇幅简单介绍一下在这过程中我们经历的一些事情以及解决方案,希望能给感兴趣的同学一些参考。
互联互通
我们内部的工程师分为算法,数据和后端等几个不同的团队,每个团队擅长使用不同的语言来开发,所以当提供服务给其他团队使用时,如何方便其他人使用就变得很重要,从当时的情况来看,Thrift 比较成熟了,然后 gRPC 代码刚开放出来,不过因为希望在进行方法调用的时候可以很方便的传递一些额外的 meta 信息(比如 trace)等原因,我们选择了后者。然后先在一些流量比较小的服务上进行试用,后面逐渐过渡到流量比较大的服务上。整个过程还是比较顺利的,除了出现过 Python 和 Java 语言上的内存泄漏,以及 Ruby Unicorn fork 时候导致不兼容不能发送消息的问题,不过也都很快解决了。
服务发现
随着流量更大服务的加入,一个服务要部署在很多台机器上,那么调用方如何知道服务的这些地址就变成了一个问题,当时有两种方案,一种是采用服务注册,然后调用方通过名字去获取这些地址,这样做的好处是可以动态灵活的控制后端节点的数据流量分发,难点是我们用了很多不同语言,那么每种语言都要实现一遍成本比较大,当然也可以在 C 库实现来共享,但是想被 upstream 接受还是有挑战的,因为 gRPC 开发者有他们自己的计划了,我们自己一直维护也会有额外成本。另一种方案是通过 HAProxy 进行流量转发,从当时的情况来看,这种改个配置就可以生效被我们采纳了。后来我们发现服务变多时,机器 IP 经常动态变化时这种方案也变成一个挑战,后面会讲我们怎么应对这问题。
标准化
在不同团队提供服务的过程中,我们发现大家依赖的环境是非常不一样的,这样我们部署上线的时候脚本写起来就比较麻烦,然后升级依赖环境也容易出现问题,不能很好的隔离,我们自然而然的想到通过 Docker 来部署服务,然后也从简单服务上线,到绝大多数服务都最终 Docker 部署,整个过程还是比较顺利的,现在我们每天在开发环境各个分支(包括 Release 版本)跑 CI, 通过了 CI, Release 版本 image 会自动从开发环境的 Registry 同步到生产环境的 Registry, 其他分支的 Image 因为生产环境不需要,并且数量巨大,所以没有同步。
健康检查
解决了部署问题,我们发现随着服务变多有的时候由于某些服务的接口的响应时间不稳定,比如说突然变很长,这样会把调用方的线程池资源都耗光,然后引起连锁反应,导致 API 服务最终受到影响,为了解决这个问题,除了设置更小的服务调用超时时间,我们引入了断路器功能,这样不仅可以进行不同服务的隔离,还可以给超负载的服务以恢复机会,毕竟一直调用一直超时并不是很好的办法,然后适当的降级。另外,我们发现 HAProxy 后面的服务有时虽然可以通过 TCP 层面的健康检查,但是服务线程已经僵死了,这种情况 HAProxy 是不能检测到的,也就不能自动的把相应节点摘掉。为了解决这个问题,我们的每个 gRPC 服务都提供一个 health check 接口, 然后会有监控服务定时检查这个接口,如果不正常,相应服务就会重启. 当然这个被我们放在了公共库里面,接入不需要额外成本。这样我们就知道如果这个通过检查,那么服务是有业务处理能力的,更加放心些。
监控报警与日志收集
虽然服务出了问题可以自动重启来恢复工作,但是哪些接口是慢的,响应时间分布,调用频率, 错误率等问题对我们依然是一个黑盒子,不便于定位和解决问题,所以我们像上面的 health check 接口一样,同时提供了 metrics 接口用于输出相应的统计信息,并且这些信息是可以自动被 Prometheus 收集,然后通过 Grafana 展示出来的,超过指标发送报警给相关同学。另外还有就是我们的服务会产生很多日志,其中包括一些报警,异常信息,还有系统日志,我们都通过 Fluentd 收集然后同步到我们的 ElasticSearch 集群,这样我们就可以通过一些条件过滤出相关信息了。
弹性伸缩
似乎到这一步,我们可以休息一下了,可是又发现了新的问题,我们的服务也面临着某些时段用户访问量比较大,但有的时间段访问量相对小一些,如果每个服务都按照最大的访问量申请机器的话,会造成很大的浪费,所以自然的我们想到如果机器可以根据请求量自动伸缩就比较好了,正好 AWS 提供了 autoscale group, 简单来说就是可以根据 CPU, Memory 等设置的阈值自动启动新的机器或者销毁机器,然后执行我们指定的脚本,于是我们逐渐把服务向这个方向迁移,还好我们之前都已经 Docker 化了,启动脚本就相对容易些了。
集群调度与部署
在上面迁移 autoscale group 的过程中我们又发现两个问题,一个是每组(autoscale group)机器只能运行同一个服务造成资源浪费,大家都不确定别人的服务需要多少资源,如果共用机器不确定是否会互相抢占资源,导致服务不稳定,如果通过 cgroup 控制资源的话,部署就变得很麻烦。另外一个问题是我们内部很喜欢 code as infrastructure 这种理念,所有硬件资源变更都通过 Terraform & Git 来进行管理的,方便追踪相关的变化,那么问题来了,我们有很多服务,每次新服务申请机器都要指定 CPU, Memory,disk, instance type等资源,一次两次还好,次数多了就变得很枯燥。所以我们想如果可以所有资源统一管理起来,上线新服务的时候只要通过 Web 界面简单配置一下就可以上线会让大家更开心些。这个过程我们调查了几个常见的服务编排工具,最终选择了 Kubernetes,一个比较重要的原因就是他提供的一些机制和理念跟我们之前遇到的问题可以很好的结合。然后通过 Spinnaker 进行服务的发布。
单元化
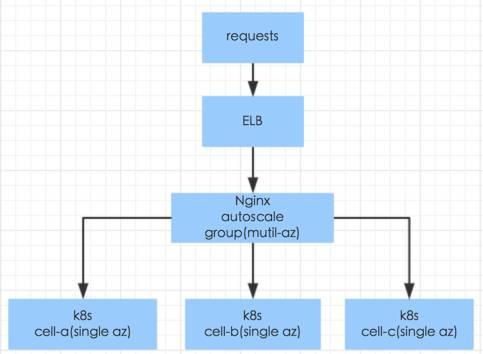
在线上我们部署多个 cell, 每个 cell 是一个完整服务的 Kubernetes 集群,部署在独立的VPC(virtual private cloud), 不同 cell 之间是完全隔离的,保持架构的干净与纯粹性。然后每个 cell 里面包含若干我们上面说的 autoscale group,每个 group 里面的机器配置是不一样的,有 CPU 比较好的,也有 CPU 一般,但是 Memory 比较大的,同时每个 group 可以非常容易的扩容到很多机器。部署时你的服务需要什么类型的资源,通过选择器就可以部署在相应的机器上,为不同类型的服务部署提供便利。

可用性
不同的 cell 会部署在不同的可用区(同城不同机房),这样可以保证更高的可用性,然后通过内部负载均衡器切分流量到不同的 cell, 同时也可以为升级基础软件(比如 Kubernetes, OS 版本)等提供保证。如果后面有多个地区(不同城市) 的话也可以考虑异地部署 cell, 然后通过智能 DNS 切分流量到不同的集群,这样用户可以就近访问我们的服务。当然这里面会有一个有状态服务(比如 DB)数据同步延迟的问题,初步想法是对于修改者的请求重定向到主集群来解决。
健壮性
从某个角度来看,如果服务进程出了问题会自动重启来恢复,如果机器出了问题会自动下线然后上线新的机器,如果某个集群出现问题,可以切换流量到其他集群。不过目前这里还不包括有状态的服务。
小结
上面说的这些是我们过去一段时间以来遇到的一些问题以及改变,后面肯定还有很多需要改进的地方,希望我们不断的努力可以给用户提供更好更愉悦的体验。如果你对我们做的事情感兴趣,赶快加入我们吧!
小编说:
这是流利说技术团队2016年的最后一篇技术文章,2017年我们会继续带给大家实用有料的内部分享,感谢大家的关注,新年快乐!

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

