技术揭秘大众点评大规模并行AB测试框架Gemini
【编者按】众所周知,互联网行业朝夕万变,产品和决策都需要快速得到用户反馈的数据去迭代更新,所以AB测试在互联网公司中就显得非常重要,是data-driven product的基础,微软、Google、Amazon都在这方面做了大量研究和工作,有兴趣的可以参考 EXP 这个网站,上面有大量各个公司如何做AB实验的文章和资料。日前,大众点评数据中心研发经理樊聪(@卡斯fan)给分享了点评的AB测试框架(codename Gemini)和平台搭建的实战经验。
以下为正文:
我加入点评的负责的第一个项目就是点评的AB测试框架(codename Gemini)和平台的搭建,目前这个系统已经在搜索、PC主站、广告等业务广泛使用,给业务部门更好的做算法优化和产品设计提供了数据支持的决策方法。下面给大家介绍一下这个系统的原理、架构和设计思路。
总体架构
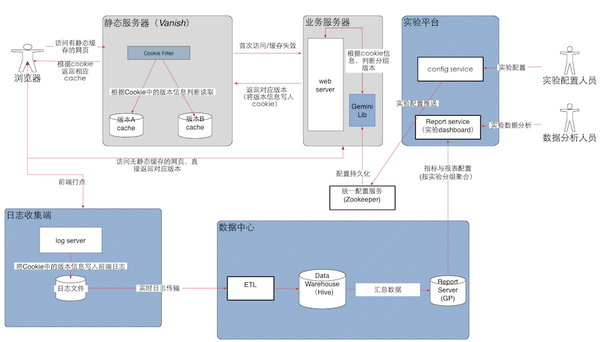
Gemini 架构图(点击图片查看大图)
如上图所示,Gemini主要由4个部分组成:
- 静态缓存服务器(Vanish)里面的cookie filer
- 业务web server里面的ClientLib
- 实验配置平台
- 数据中心的计算处理链路
这种架构的选择也是由点评本身的基础架构相关,我们知道业界AB测试框架的方案大致有两种:
1. 两套代码:顾名思义,是把control(基准代码)和treatment(实验代码)分别部署在不同的机器,通过统一的router分发流量。百度和google使用的是这套架构的好处是对业务侵入性小,灰度发布和正式上线都非常方便。但要求就是开发流程是分支开发模式且代码部署需要和分流路由可用统一配置和联动。
2. 一套代码:业务逻辑中把control和treatment的分支都写好,通过在业务服务器里面嵌入AB测试框架的client,判断流量是该走control还是treatment。这种思路的好处是对外部系统依赖小,全部逻辑都在业务服务器完成,适合主干开发的模式,但是对业务侵入大,灰度发布不方便,代码维护还有整洁度下降。微软和amazon是使用这套架构。
我们当时根据点评的自身开发流程和运维基础设施,最终选择了一套代码的方案。
分层的实验模型
在详细介绍Gemini几个模块的设计之前,先需要介绍框架的分层模型的概念。我们当时的需求一个是业务和功能会包含多个实验并向的进行,比如商户搜索页:可能有主站的在进行页面改版,搜索的在优化搜索排序,推荐的在优化个性化推荐。第二个是流量能够按照一些属性切割,业务组可以独占100%的流量。基于这两个需求,我们参考了google在2010年KDD上公布的自己的 分层实验框架 。Google提出将实验空间横向和纵向进行划分,纵向上流量可以进入独占实验区域或者是并行实验区域。在独占实验区域,只有一层,实验可以独享流量且不受其他实验的干扰。在分层区域,不同的应用属于不同layer,每个应用内部,又可以划分为多层,层与层之间相互不影响。流量可以横向经过多层,每一层可有多个实验。流量在每一层都会被重新打散。
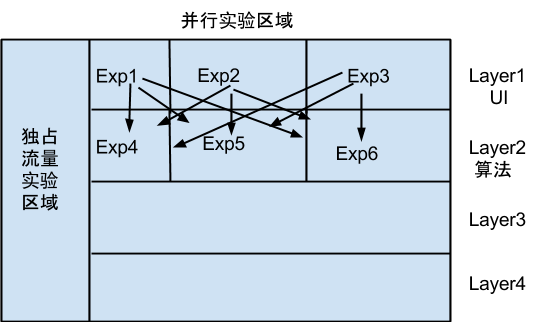
分层实验模型示意图
我们将Google的思想进行了一定程度的简化:
- 横向上分为多层,每一层含一个bucket集合(默认为100),流量按照其cookie中的guid和layerid被哈希到某一个bucket中,并绑定该实验的参数取值。这个策略的本质所在就是在hash的时候考虑了两个变量:guid和layerid,从而在不同层之间实现了流量的重新打散,保证层与层之间实验的正交性。
- 纵向上,按照流量的属性:如地域,用户特征等把空间划分为segment,这些segment被某个实验独占,从而可以实现多个实验在不同流量域进行且占有该域下面的所有流量。变形可以用来进行灰度发布:比如我们团购优化就是现在某些城市进行实验,再扩展到全国。
有了上面的概念,其他模块就容易理解了:
1. 实验平台:
实验平台的主要是提供了一个web portal,供开发人员进行流量划分和实验参数的配置,支持按照多个维度配置流量划分:如城市,cookie值,供service使用的自定义值。同时对于上面提到的guid,我们默认是点评的userid,同时也提供deviceid和自定义的id供流量进行hash。参数的配置统一保存在点评的configuration服务(Lion)里面,实验参数命名需要在应用域唯一,命名规范为:应用名+模块名+参数名,从而实现了参数的动态修改和绑定。
同时,实验平台还管理实验的启停,修改和报表dashoboard展现等功能。
2. 实验客户端:
这一部分主要是一个RPC的API client,业务方在web服务器的filter里面和逻辑service中,用于从lion中读取配置信息和参数信息,并根据流量的hash值判断范围怎样的参数取值。如下面的示例代码:
UseCase 代码
public class UsageTest { @Test //正常场景:在web容器内 public void test_normal_usage(){ ABTestFactor factor = ABTestManager.getFactor(); int factor1 = factor.getInt("factor1", 1); //use factor1 } @Test //特殊场景:1. 在RPC的服务端,2. 在线程池内的线程中 //需要用户传给框架上下文context public void test_rpc_or_threadPool_usage(){ HttpServletRequest request = null; HttpServletResponse response = null; // 传入一个request 对象 DefaultABTestContext context = new DefaultABTestContext(request, response); // 直接传入 context.addKey(“deviceId”, “adf2345sdf”); ABTestFactor factor = ABTestManager.getFactor(context); int factor1 = factor.getInt("factor1", 1); //use factor1 } } 这部分模块的另外一个功能是把实验的一些标识信息打到日志中,针对不同的场景,我们提供后端日志打印和cookie回传到前端,然后前端打印的两种方式。
3. 数据中心的数据处理:
实验启动后,效果如何跟踪就是数据中心的内容了。这里主要包含几个阶段:日志的传输,解析,报表和dashboard的展现。Gemini结合数据模型内置了几个常用的指标:PV,UV,CTR等,用户可以直接看到相应的AB两组的效果,对于其他指标,目前还是需要用户自行配制报表,或者通过hive写脚本统计。另外现在点评已经实现了日志的实时传输,但对流量数据的计算和ETL还是T+1的,如果用户要实时的效果跟踪,需要自己编写基于storm的统计应用进行分析。另外提一点,我们还内设了计算置信区间(pvalue)的功能,帮助实验的同学更好的根据实验的流量大小和实验时间长短,判断当前实验效果的可信程度。
4. 静态缓存服务器的问题:
另外一个比较有意思的一点是我们在静态缓存服务器上的处理,因为点评在一些业务场景中大量使用了vanish静态缓存服务器,会使得一些流量无法透传到后端,用户得不到正确的AB版本,我们的解决方案是植入一个vanish的脚本,通过URL+cookie判断和存储control和treatment的不同版本,简单来说:当用户第一次请求,如果判断是要做实验的,那么在header中设置cache-control=no-cache,并回写cookie;如果不是要做实验的,不做任何事情,当用户第二次请求,如果没有含有cookie,那么直接命中vanish。如果有cookie,再穿一次后端,后端不设cache-control=no-cache,这个页面被缓存。下次再来请求就可以命中了。
除了上述主要模块外,Gemini上线后,我们也根据反馈在易用性和功能性上进行了优化和升级,包括:
- 克隆实验和在线修改实验配置:在实验正式上线前,开发同学往往是先在测试和ppe环境中配置好实验,并进行正确性验证,在确认没有问题后再发布到线上,如果每次测试到发布都要重新配置实验,会显得比较繁琐,特别是对于一些参数特别多的实验。针对这个问题,我们开发了实验克隆的功能,实现了在不同环境中实验的同步,提高了系统的易用性。同样的,实验上线后,经常需要对实验进行一些微调(某些情况下,可以视为一个新实验),我们配置管理是基于zookeeper的推送,在客户端内存中保留一份配置的cache。这样我们就可以方便的在客户端设置一个回调函数,当zk中配置修改后,更新内存中的配置即可实现实验的在线修改,避免了每次都重新上线一个实验的过程。
- 自定义实验条件:在某些业务中,实验框架是位于service层,流量进入后,已经被包装了其他的属性,而这些属性往往还需要作为实验分流的条件。为了支持这个需求,Gemini加入了一个自定义实验条件的功能,可以通过key/value 对的形式在实验平台上添加定制的实验条件,分流时会统一考虑进分流策略。
以上就是点评AB测试框架Gemini的简单介绍,后续系统的改进点其实还有很多:
- 根据条件启停实验
- 灰度发布的集成(考虑把整个框架放到底层基础组件中)
- 效果数据的实时化和更完善的评价体系等
大家有什么问题和建议也欢迎和我们联系,一同探讨。
参考资料
exp-platform: http://www.exp-platform.com/Pages/default.aspx
Overlapping Experiment Infrastructure: More, Better, Faster Experimentation : http://research.google.com/pubs/pub36500.html
Online Conrolled Experiments at Large Scale: http://www.exp-platform.com/Documents/2013%20controlledExperimentsAtScale.pdf
(责编/钱曙光,qianshg@csdn.net)
作者简介: 樊聪(微博),目前在大众点评数据中心担任研发经理,负责数据应用和用户画像,曾在百度和微软从事海量分布式数据仓库项目和并行开发工具的研发与测试工作,主要关注领域:分布式实时处理系统、并行计算和海量用户数据仓库、数据挖掘和建模。
由“2015 OpenStack技术大会”、“2015 Spark技术峰会”、“2015 Container技术峰会” 所组成的 OpenCloud 2015大会于 4月17-18日在北京召开。日程已经全部公开! 懂行的人都在这里! (优惠票价期,速来)正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

