广发银行运维实践分享:Docker适配传统运维那些事
数人云 上海&深圳两地“容器之 Mesos/K8S/Swarm 三国演义”的嘉宾精彩实录第一弹来啦。今天是广发银行数据中心的运维老兵沈伟康关于传统运维与容器适配的全方位分享,万字长文倾情奉上~
沈伟康,广发银行数据中心
运维中年人,经历传统运维,建设自动化运维,尝试云计算运维
大家好!我是广发银行的沈伟康,从传统行业出身,现在还在传统行业的坑里,今天分享的内容是在传统运维会遇到的各种想做但是不一定能做,又不得不去做的事情。
CMDB :标准化,差异化与自定义

无论是传统运维还是自动化运维, CMDB 是一个很重要的核心。如果 Docker 没有自己的 CMDB ,也会有很多用起来不自在的地方。
从环境这方面来谈一下 CMDB 对 Docker 的作用。如果所有事物都能标准化,那事情都会很简单、很便利,这是一个很好的理想,但在现实里尤其传统行业想把标准化进行推广,实现起来有一定的难度。
它会面临一个问题:差异化。差异化多了以后, Docker 就会有各种各样的镜像,不同应用之间会有不同的镜像。即便是同一个应用,不同的月度版本下都有不同的镜像,比如升级了某一个库,镜像也是不一样的,这时候应该怎么做呢?这时按正常逻辑,会给它做自定义。如果要自定义 Docker 的一个镜像,可以通过 DockerFile 来做。
现在各大厂商的产品里面几乎都有一个 WebUI 的界面让用户去选择一些内容,可以自主编程一个 DockerFile 。如果只是单纯地把里面一些 FROM 、 ADD 参数直接加到页面上去选的话,至少要有一定的适配过程。
所以借鉴大家惯用的传统运维思路,并配有一个与以前传统 CMDB 对接的点,广发银行有如下几个做法:
第一,操作系统。对着 DockerFile 的 FROM ,让它在列表里选择这个应用要跑在什么样的 OS 里面,包括它的版本等。
第二,常用软件。在下拉框选完之后是一个 ADD ,例如选了 JAVA ,要在 Docker 运行环境里面给它环境变量,容器里要找到 JAVA 相关的命令。 Tomcat 或者其它软件,都会有一些环境变量。所以在常用软件这块,现在打包的大部分是 Tomcat 或者 JAVA 类软件,把一些特定要使用的环境变量,根据这个页面选完之后,用 ADD 添加软件包的同时,用 ENV 把它设到环境变量中。
第三,需求包上传,对于差异化来说很重要。例如这个项目组的应用依赖某个 Python 版本,另一个项目组又依赖另一个版本的 Python ,又如 OS 自带的一些 so 库,它到下个月度版本的时候又要依赖不同的版本,但是不想把这么多版本都做成不同的镜像提供不同的服务市场,就会有一个需求包上传,这个包里把项目组应用需求的除了常用软件跟 OS 基本的套件之外的其他库或者软件打包,比如 Python 的安装包, RPM 包,还有一些应用自身的东西,如启动的时候需要加载的证书之类都打包在这个包里。
第四,执行安装。这个包打完之后,为它定义一个执行安装过程的入口,即一个安装脚本,约定的时候让它将安装脚本放在压缩包的第一个目录下。这个包就相当于有了 setup.sh 的一个入口,这个入口让应用去定义安装什么、如何安装以及安装顺序。
第五,映射端口。对应 DockerFile 的 EXPOSE ,应用、服务或者容器启动完之后,会对外暴露哪一些端口。
第六,存储使用。存储路径选择对应 VOLUMN ,如果 IO 要求比较高就不用容器内部的 AUFS ,如果要求持久化就用外挂路径,如果宿主机之间共享就需要放到一些分布式存储或者 NAS 这种共享存储里面。
第七,启动运行。等价于 CMD ,让项目组在一个页面设置完之后,把它放到与传统 CMDB 对接的一个 Docker 专属的 CMDB 里。

这个 CMDB 主要的内容总结有三部分:环境需求配置,配置文件管理,应用运行配置。应用运行配置是项目组在一个页面做完配置后,运行和编译的时候就不用再填参数了,所有不同的项目都在这里一次性设置好。
管理的纬度,配置是一个应用加一个项目标识。这个项目标识可以理解成是按月度或者是按照自己喜欢的命名的规则,如海外版本和国内版本。但对于广发来说,用得比较多的是月度的标识,例如一个应用有 ABC 环境,分别对应几月份版本。
持续集成
镜像分类
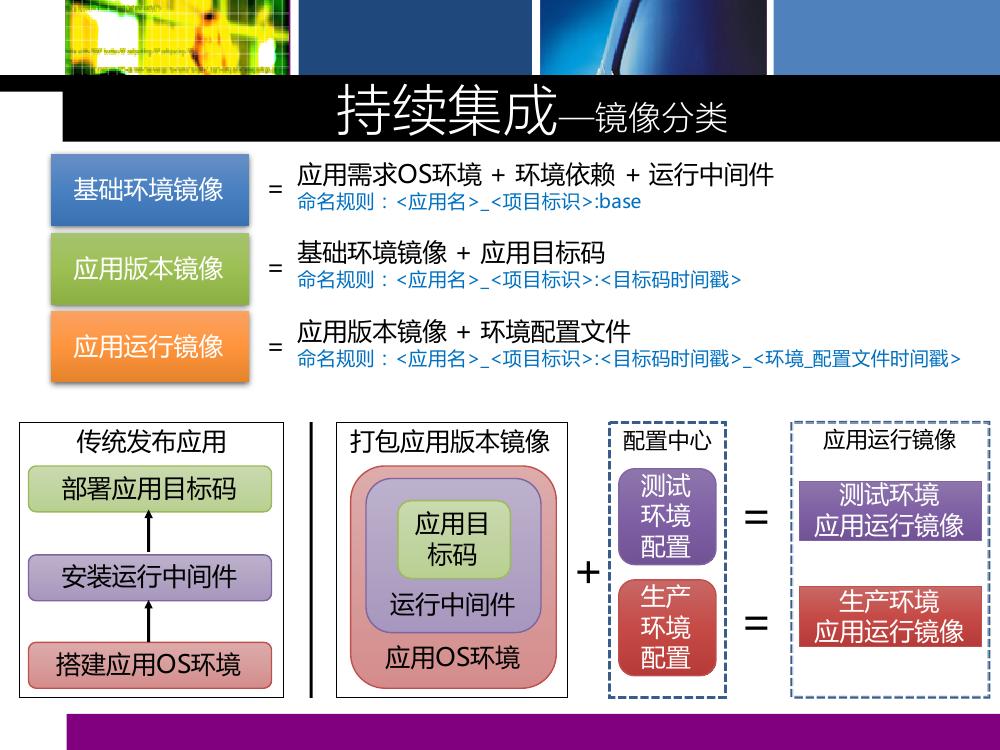
这里把镜像分成三类:第一类,基础环境镜像,上面只有 OS 还有一些依赖库的安装,一个运行的中间件。它会有一个命名规则, “应用名+项目标识”,比如“ ABC_”,然后“ 201701 ”,就是 2017 年 1 月份版本,“ base ”表示镜像的 tag 是 base ,表示这是它的一个基础环境镜像。
第二类是应用版本镜像,在第一个基础环境镜像上加了编译后的目标码,不带环境差异的配置文件。这时命名规则是“应用名+项目标识”, tag 变成了目标码的时间戳,在持续集成整条线下有一个唯一的标识,就是时间戳。当然,大家也会有其它各种各样的唯一标识选择。
第三种叫应用运行镜像,它是上面应用版本镜像再加上环境配置文件。开发环境有它自己的数据库,各种不同的环境都会有自己的数据库配置,这个配置是不一样的。如果说抽象成配置中心的话,它可以管理,但还是用配置文件。命名规则是“应用名+项目标识”,再加“目标码时间戳”和“环境”。环境包括 DEV 开发环境、 TEST 测试环境以及 PROD 生产环境。最后是“配置文件时间戳”,一个项目组在项目初始的时候定义的配置文件内容有四个配置项,过了一段时间可能变成五个配置项,所以还是一个时间戳,即配置文件的时间戳,以此去标识一个完整的运行镜像。
与传统的过程项目相比,广发的过程主要是搭建一个应用的 OS 环境,安装相应的中间件,然后部署相关的应用目标码。用 Jenkins 去持续集成出它整个应用版本镜像。整个过程就是应用版本镜像,加上测试的环境配置,它就变成测试环境的应用运行镜像,加上生产的配置就变成生产环境的应用运行镜像。
配置管理

为什么做配置文件而不做配置中心?推广配置中心的话,应用要改很多内容。传统应用里面很多配置都是写在配置文件里面的。如果要把配置文件改成从一个库里面读出来,举例开发环境,它的 IP 要有一个配套的插件从数据库里面把配置抽取出来,取代它原本的配置文件,才能在环境里面做它的开发;或者也可以做一个类似 Eclipse 插件去做这个事情,但配套的东西还是要很多。如果为了上 Docker 要去推动这个事,它会变得很现实:第一,时间长;第二,阻力大。
另外一个方法就是环境变量。相对数据库形式的配置中心来说,环境变量稍微简单了一点,但是它要求项目组有一个人去抽离出配置文件里面各项的配置,然后转变成环境变量,再告诉项目组 “原本的 DBURL 配置”,代码里面需要变成 System.getEnv()来获取 DBURL ,而不再用 getProperty 读出来。
所以广发使用了一个配置文件包。这个配置文件包是一个 tar ,不会限制它有一个很严肃的名字,但是它的目录格式规则有一个限制的规则,它的第一个目录是最终访问的子 URL ,也就是 TOMCAT 的 webapps 下看到的目录。然后将所有的配置,假设最下面示例,应用有三个配置文件,要求它严格按照相对路径,把最终的相对路径打包好,打包成一个 tar 。
它按照 war 包的相对路径将配置文件打包成一个 tar 。然后把这个 tar 上传到不同的环境目录,例如它有三个阶段,一个是开发,一个是测试,一个是生产,那它就会有三个目录,这三个目录由不同的运维人员编辑,开发环境的原则上不用改,因为本来就是从开发来的;测试环境要由测试环境的运维同学,把那些 DBURL 、数据库用户等配置按实际情况修改,生产环境也类似。
之后用一个最简单的 DockerFile ,即 FROM 应用版本镜像,再 ADD ,将配置文件到指定路径,假设是 Tomcat 就是 webapps 目录下,因为 ADD 会自动解压,自动地把它覆盖成一个真正的相应测试环境的运行镜像、测试环境的运行镜像、生产环境的运行镜像。项目组只要找一个人把这些配置文件抽出来就可以了。很久以前我们已经谢绝所有把配置硬解到代码里面去,所以这种场景不适合。在 JAVA 里面直接写一个环境的数据库链接上面,但是它应该适用于把配置所有都抽离出一个文件里面或者说某个文件里面。
版本流程
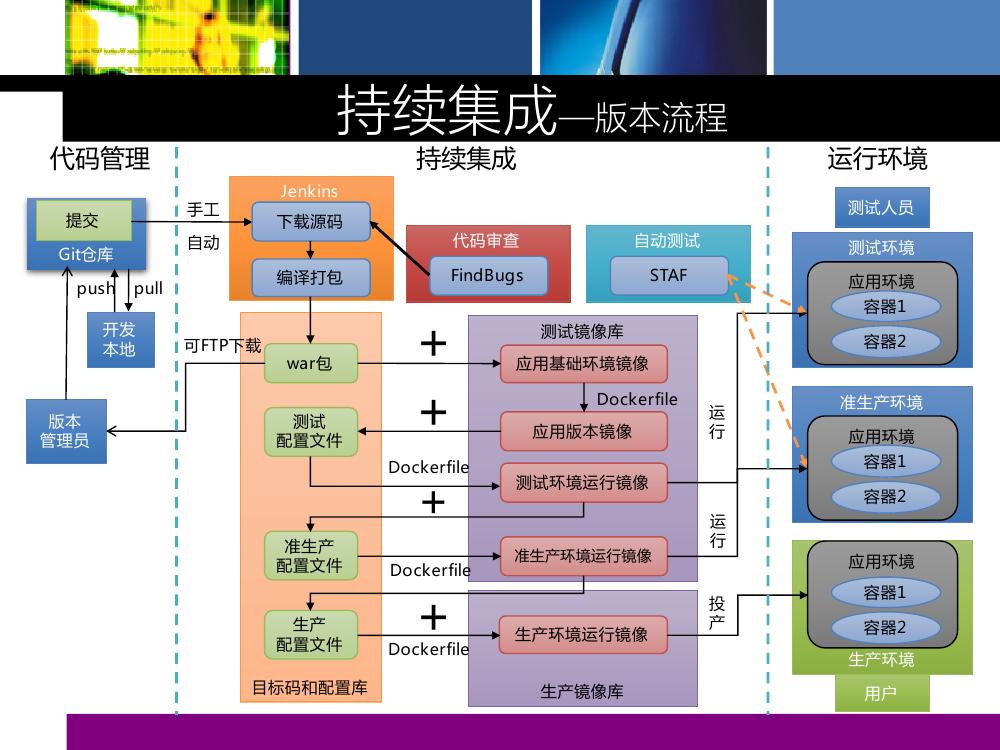
这是广发银行持续集总的框架。代码用 Git ,有一个目标码库,以及配置库。虽然上了 Docker ,但是没有舍去传统的环境。 WAR 包是持续集成编译一次后的 war 包,存起来并开放给传统部署的同事下载使用。配置库是刚才提到的存配置文件的地方。测试镜像库是独立的,它们之间的同步是通过脚本去自动同步的,即 export 出来的镜像,一个 pull ,一个 push 。
开发人员写代码,写完代码之后提交,提交完会由 Jenkins 自动下载回来编译。在这个过程中有一个 FindBugs 来做的代码审查。然后编译生成一个 war 包,这个 war 包到这一阶段理论上与正常持续集成过程或者是人工编译后的 war 包一样。这时如果需要传统部署,可以通过 FTP 把 war 包下载回来,投产直接使用。
如果要用 Docker ,这个 war 包会加上它的第一个镜像:应用基础环境镜像,生成它的一个应用版本镜像;应用版本镜像生成完之后,加上测试环境的配置文件,它就会变成测试环境的运行镜像;这个测试环境的镜像只要运行起来,就会变成一个测试环境;测试环境是由测试员测试的,或者由一个自动化的工具做自动化测试。
测试环境的运行到生产上来说也是同样一个过程,广发还有一个准生产环境,整个过程也都是类似的,准生产环境是与测试环境共用的。生产环境也是由版本镜像加上配置文件。所有从应用版本镜像生成运行镜像的过程都是可以不断迭代自动化的,运行的时候就会在环境里面跑起来。
运维那些事儿
交互

在传统运维里如果拿到一个虚拟机,它有固定的 IP 或者 DNS 域名,想对它做什么就可以进去做,可以查看数据或者性能,尤其是在查性能问题的时候要看 OS 里面的资源使用情况,还有一些应用的状态,包括 OS 的状态。而这些东西到了 Docker 里面,就会变得有很多的阻力。
如果 Docker 容器里出了性能问题的话,要如何查?如果按照传统的观念,要 SSH 到容器里面去做,例如说有一个应用, Tomcat 到了 90%,那是否一定要在生产环境要保留这个环境,让应用开发的人去查?还是直接毁掉它,重新起一个或者两个,业务量就不受任何影响,这种事情因人而异。
另一个方法,可以把这些简单的交互分成两类,一是查看类型的需求,尝试通过外挂目录,因为假设要查看生成的 javacore 、 heapdump 文件等,以前做法是在 OS 里面使用 kill-3 生成 heapdump 文件,但如果把这些生成 heapdump 的动作归结为第三点操作类的话,是不是可以直接在宿主机上放一个 agent ,要对哪个容器做 heapdump 相当于让用户在页面上直接选一个生成 heapdump 或者一个动作,然后由 agent 通过 EXEC 命令跑到容器里面去做,尽量禁止用户直接跟容器进行交互。当然也有比较粗暴的,比如 WebSSH 。
应用更新与灰度发布

应用更新的概念是服务没有中断。人们常说的滚动升级,在很多产品里面都实现了。但是实现的层面或许是这样的:假设有五个容器,滚动升级是按批的,第一批升级两个,升级完之后毁掉旧容器,用新的两个容器去换掉旧的两个容器,隔一段时间再升级后面的三个。这种按批升级会有一个需要关注的地方——容器销毁的时机。
常见的云平台调度算法里,容器状态 OK 的时候,调度平台会把原本的容器替换掉,但这个时候容器状态 OK 并不等于服务可用,因为容器里的 Tomcat 端口起来之后,它就会说这个容器是已经 OK 了,但是 Tomcat 起来之后的服务加载这个过程,快的话可以几秒,慢的话例如一个很庞大没有做任何微服务化改造的应用,就会是一分钟。但这一分钟之间,新的容器已经替换掉旧容器,那么这一分钟就悲剧了。所以服务加载的时间不能够忽略。容器销毁的时机是要大于容器状态 OK 的时间加上应用自启动的时间,在容器的调度上至少要用户每个项目组加上服务要起的时间,要十秒就填十秒,十秒钟之后再按照按批滚动升级的过程去做。
现在传统运维里面一个应用可不可用,尤其是在银行里可不可用影响是很大的,所以广发银行在运维体系里有很多应用对外暴露的一些服务接口,然后通过自动化的监控工具去监控它的可用性。从这个角度来说,调度器可以与传统监控对接,通过调用传统运维的内容获取到一个服务状态可用的时候才去执行五个升级两个,再升级三个这个动作。
第二要关注流量转移,在服务启动完之后,通过负载均衡自动去设置权重把新的流量转移到新的容器里面。因为有一个容器销毁的时机,所以这个容器也不会销毁,但是不要把新请求转给它。在传统行业,如果新容器或者服务好了、旧容器就马上关掉的话,应用的架构不一定能够支持。在生产上尤其是在银行,例如在转账的时候有一个交易流程,在一个容器里面规定要 1 、 2 、 3 、 4 、 5 步发生,并不是第一步做完放到一个地方,然后由其他任何一个人去调第二步都可以。如果把 1 、 2 、 3 、 4 、 5 都串到一个容器里面,做到第三步的时候旧容器服务被停了,又没有对外的转账接口去把钱转到别人那里去,后果就很严重,所以流量转移工作包括销毁的时间是要慎重的。
在很多厂商那里都会听到灰度发布,但是大部分都只是说没有中断。这个中断是不是真的没有中断,有待考究。广发会强调另外一个 A/B TEST 。如果通过负载均衡去设置,举一个简单的例子,通过 F5 或者其它 LVS 负载均衡去设置来源 IP 来选择新版本还是旧版本是没问题的。但是来源 IP 是可以欺骗的,像以前 Pokemon go 出来的时候,人不在国外,但是搞一个国外的 IP 也可以上。所以在应用可以接受的情况下,灰度发布应该由应用的人去做,例如每一个账号生成了唯一的 ID ,由 ID 决定他们是用新版本还是用旧版本。尽量不要用负载均衡来做灰度发布。
弹性扩缩与可用性

现在弹性扩容至少会讲到两点:一个是业务时间点,比如九点到十点这个业务时间点,可以把容器从十个变成二十个;另一个是通过监控策略来自动化弹性扩容。扩其实很简单,从十个变成二十个没什么问题。但是扩完之后要缩回来,比如要应对某一个节日“双 11 ”,找一个特定的时间点给它加 OS ,但是加完 OS 之后缩回来需要一个停机时间窗口,或者先从 F5 上 Disable 然后回收。
但是到了容器,如果放任调度器自动回收、自动缩容,是否真的可取?和刚才提到的销毁时间一样,是否要与传统的监控、服务可用的平台做一个对接后再缩?如果可以做到才是真正能够缩的,而不是现在页面上选择五个缩成三个,它就真的缩了两个,至少我们在生产当中是不敢这样做的。
均衡资源。假设传统运维里,把 Docker 的宿主机交给传统运维的监控平台去监控,但这时监控平台判断这台宿主机已经 CPU 使用率 90%了, Docker 调度器与传统运维的监控平台做对接的时候,为了不影响应用服务是否需要把容器给迁走,是全部迁走还是把 CPU 消耗高的迁走,或者把启动时间最长的迁走?作为一个程序员永远都不敢说自己写的程序跑了一段时间之后会不会比刚刚跑起来的时候更稳定。这种策略在生产实践是很关键的,需要一个博弈的过程。现在很多厂商自身支持各种各样的弹性,但是弹性缩是否真的能够支持而不会有业务影响,是有待考究的。
目前来说,没有任何一个厂商说“只要用我的平台,包括把我的平台堆积到传统运维之后,可以做到想缩就缩,不会让用户账户丢了钱”,不用让业务员去做一个回滚的操作。在传统运维里面,如果应用开发的项目组可以按照各种各样优雅关闭的特性去写应用,没问题。但毕竟业务程序是由人写的,人是不可控的。
日志

在传统的应用容器化运行后,会有一个归档和查看日志的问题。目前项目组把它改成标准输出,再由自动的一个收集平台,例如广发银行现在是用数人云的一个 logagent 去自动收 logstash 的,然后存储到 ES 里面,由 Kibana 去展示。如果要对接传统运维,也可以让项目组把应用的目录放到一个外挂的文件。传统的监控里面有一个外挂支持在某一个路径下监测所有的配置文件,所以只要把它放到一个外挂的共享存储或者分布式存储,然后再把这个外挂路径作为一个对接的入口到传统的日志管理平台里面就可以了。
另一种是以前做 CloudFoundry 时,他们会强调应用要把所有的日志作为流写入到这个平台里面,例如 FLUME 。如果只是简单粗暴地把应用的日志写进去,会有时间乱序的问题,当然这个问题是可以解决的,但如果 A 容器实例跟 B 容器实例都是属于同一个应用,就会有这里来了一句之后,那里下一句话又来了的情况。要截取某一个加密的日志,需要开发人员配合在日志里面加各种各样的标识,例如现在要查询某一个业务量的日志,要根据业务量的代码去查,查完之后它能够抽取出来在同一个容器里面的那一段日志,那如何做到在同一个容器?无疑在写日志的时候,也需要把容器的标识放在日志里面。
如果做实时,用 syslog 就可以。如果只是日志收集, ELK 也是可以满足的。为了减少应用改造,单应用日志时就重定向到标准输出。如果是多个日志,现在考虑的方案是把它放到一个外挂目录,再由专门的容器去收上送,而不会通过其它的 agent 。外挂目录也是可以对接传统的应用日志监控平台,传统运维里面可以有一个监控平台去监控这个日志的增量更新里面有没有应用关注的关键字,如果有这个关键字的话,就会发短信提醒说应用出现了什么异常。
监控

在传统行业里面要对接传统监控一定是必然的。对接的过程可以分成几个纬度,一是 Docker 与平台自身的监控,可以通过接口去对接、上送数据。另一个是宿主机的监控,宿主机是一个物理 OS ,传统监控里面如何折腾这个 OS 已经是很标准或者很自然的动作。
容器监控,可以尝试 cadvisor 或者其它在业界应用比较多的东西。应用监控比较难,传统运维会关注应用 CPU 和内存使用率,以及数据源的连接词,或者一些线程数,当达到某一个值后,就进行告警。而到了容器里面,要把它抽离出来。举一个例子,它可以把 Tomcat 里面的 Apache 公布的那一堆指标通过 Tomcat 的接口给暴露出来。暴露到哪里,是需要额外去定制化、去收集容器里面的 Tomcat ,所以对不同的工具要做一个对接的过程。
在容器化的网络里,除了一些对外暴露的端口, Docker DB 就不用说了。但是在应用的端口里面,假设是 HaProxy , HAProxy 的端口可用不表示相应容器的服务是可用的,可以尝试直接在监控 HaProxy 这些端口服务的同时直接让应用暴露服务可用性的一个接口,直接监个应用接口的返回码究竟是 200 或是非 200 就可以了。
应用改造

应用改造只列了四点,并不表示应用改造只有四点,而是努力让应用只做这四点,只关注这四点就可以了。
第一是节点差异化,在环境里假设有三台应用服务器,其中一台应用服务器做了一些其它两台应用服务器没有的事情。这种情况在广发或者金融行业里都是比较多的。到了 Docker 之后,就尽量不要做这种事情。
第二是持久化,在广发的环境里面,举一个数据, OS 里面的外挂存储很少少于 500G 的。一个 OS 如果要做动态扩缩,里面的存储越少越好,因为不需要让它做其它事情。如果要把一个文件持久化,是因为 IO 的性能问题需要把它外挂,还是日志不属于容器销毁而持久化?或是这个容器在 A 宿主机跑起来,下一次在 B 宿主机跑起来,都要读写同样一份东西,那么就搬到 NFSDATA 的一个文件里面,选 NAS data 作为一个 volume ,配置文件配上那个路径。
在内存数据里面,建议做一个剥离,比如剥离到 REDIS ,但是如果在有统一的应用开发框架情况下要把一些东西剥离出来,只要有框架内的应用去改造就可以。如果不是的话,可以采用一些天然比较支持这种转换的,例如把数据放到 Redis ,有一些框架直接支持改一下配置就可以,另一些框架则是不行的。
第三是可变性。以前传统运维会把上游 IP 抓下来,下发到下游。但容器的 OS 环境变量是可变的, IP 地址获取方式,变成从环境变量获取。 Hostname 是不建议使用的,以前看到把 Hostname 作为一个标准传到日志里面或者直接用来起日志共享目录的一个名字,到云里面跑得久越读不懂,至少 IP 的名字都读不懂,因为没有一个人去干预它的 Hostname 。
第四是易处理,快速启动,优雅关闭。以微服务化改造来说,能够做到易处理,即随时启动的时间不会超过几秒,随时都可以关闭,如果应用上 Docker 并且要跑得很好的话,那一定要去考虑这方面的事情。
分享就到这里,谢谢大家。
正文到此结束
- 本文标签: jenkins tar apr 代码 插件 同步 http 监控平台 编译 自动化 cat 管理 Docker 性能问题 主机 id 服务器 负载均衡 产品 redis 实例 总结 推广 Haproxy web db DNS 线程 数据 程序员 开发 core IO apache 端口 git 数据库 UI App 操作系统 src Property ssh cmd ip 银行 金融 域名 参数 ftp 调度器 java rpm tomcat find 配置 时间 快的 线下 下载 目录 测试 eclipse nfs 安装 需求 软件 Webapps python 分布式 云 定制
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

