Code Review也有潜规则
导读
在Google,任何产品、任何项目的代码,在没有经过有效的代码审查(Code Review)前是不能提交到代码库里的,这也是Google程序如此优秀的最重要原因之一。恩,这就是所谓别人家的公司,不过,Code Review的重要性,可见一斑。说起Code Review,通常会被认为是开发GG的事情,其实不然,作为测试人员,尤其是“测试左移”越来越成为趋势的情况下,势必要提高代码能力,而Code Review就是一个很好的切入点。不仅可以学习开发GG的技术,还可以完善测分、提前发现bug、降低质量风险和测试成本,好处不言而喻。笔者作为Code Review的新手,经过一番学习和实践,总结了一点点“潜规则”,希望可以抛砖引玉。
资源泄漏篇
试想,如果申请的资源未进行释放,那势必会资源泄漏,尤其是对于长时间运行的程序来说,会导致系统中可用的资源越来越少,严重的,系统会因为资源耗尽而崩溃。因此,资源泄漏的问题需要得到重视,除了提测后的资源挂机测试之外,在前期Code review阶段更加需要注意,以便尽快尽早发现问题,降低成本和风险。
对于这类问题,笔者总结了如下需要注意的地方:
慧眼识珠:资源获取和资源释放函数需要成对使用
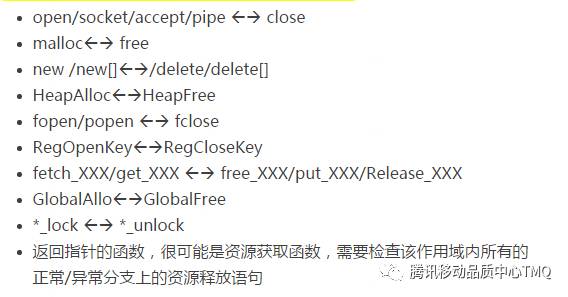
成对使用的资源获取和释放函数太多,这里就不一一列举啦,总之, 看到资源获取语句,必查资源释放语句,反之,亦然。
异常处理篇
优雅编程需要在一开始就考虑异常事件的处理,不仅需要保证在正常情况下程序可以稳定运行,而且在发生错误和出现“意外事件”时仍然能继续可靠运行。因此,需要尽可能多的预见所有这些异常事件。异常处理代码也是bug的高发区域,不仅在设计用例阶段需要考虑全面,Code Review的时候也需要特别关注。

慧眼识珠:异常处理 1) 任何可能出错的函数调用(语句),必须加异常处理,这些函数调用,包括但不限于
- 网络交互:是否有超时、是否考虑负载均衡、重试机制等
- 数据库交互:是否连接成功、超时、重试、判断返回值等
- 读取请求数据包:是否判断返回值,防止读到脏数据等
- 文件系统操作: read,start, write,open,等,判断各种正常/异常情况
- 边界值考虑是否周全
2) 对于异常处理,务必注意如下:
- 异常判断一定要有
- 异常判断的时机、条件一定要正确
- 异常判断的分支一定要完整
- 异常处理一定要充分
- 边界考虑周全
数组越界篇
访问数组时,如果访问了数组定义之外的范围,即下标落在区间[0, size-1]之外,会导致程序运行错误,而C++中数组下标越界,编译器是不会检查出这种错误的,但后果可能会比想象中严重,甚至程序崩溃。因此,这类看似不起眼的小问题,也需要得到重视。下图就是一个缺少下标判断的例子。

慧眼识珠:对于用到数组的地方,一定注意如下几点:
1) 记住数组循环操作的代码模板for (i = 0; i < size; i++)
2) 记住数组下标判断的代码模板if (i < 0 || i >= size)
// 错误区间
或者
if (i >= 0 && i < size)
// 正确区间
3) 看到下标操作,必查下标判断
- 下标判断一定要有,且出现在正确的地方即判断要及时,并注意判断条件要正确

多线程问题篇
多线程编程很容易遇上诸如丢失更新、脏读、死锁等线程冲突问题。多线程的问题一旦发生便很难定位和解决,所以要在编程的初始阶段就要注意避免多线程程序常见的错误。多线程同时读写同一资源,例如变量,文件,同一缓冲区等,一旦出现竞争条件,很容易导致程序运行结果出错。这类的用户反馈问题也有很多,首先列举下导致多线程问题的原因:
1) 资源的读写和更新没有加锁(此处经常会有用户反馈)
2) 资源的获取和访问之间有时间间隔
3) 加锁范围太小
4) 使用了线程不安全函数
慧眼识珠:多线程问题
1) 识别全局资源
- g开头的变量,g_data.*,g_var.*
- 利用IDE,如source insight,将鼠标移到变量上面,会显示变量类型
2) 看到资源的读写和更新,必查加锁
若该资源会被同时读写,则检查此变量的所有读写操作,确保正确加锁。
3) 看到加锁操作,必查加锁范围
加锁太小,程序出错;加锁太大,降低性能;需要根据具体情况权衡。
4) 看到资源的获取和访问之间有时间间隔,必查资源是否会被更新
5) 识别线程不安全函数:
- 返回缓冲区的函数,例如inet_ntoa,localtime,建议分别使用inet_ntoa_r,localtime_s代替
- 会记录函数状态的函数,例如strtok
- 基础库的初始化函数,例如mysql_init, curl_easy_init
除零错误篇
虽然 C++ 加入了异常机制来处理很多运行时错误, 但是异常机制的功效非常受限, 很多错误还没办法用原生异常手段捕捉,例如这里所说的除零错误,而这个错误也经常导致程序崩溃,因此Code Review时需特别注意。
慧眼识珠:除零错误
1) 除法或者取模操作,必加除数为零的判断
2) 浮点转整型会丢失小数部分,特别需要关注0.*变成0的情况
3) 对于影响程序稳定性和健壮性的输入,必做检查
缓冲区溢出篇
通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,造成程序崩溃或使程序转而执行其它指令。造成缓冲区溢出的原因是程序中没有仔细检查用户输入的参数。
慧眼识珠:缓冲区溢出问题
1) 识别缓冲区溢出高风险函数,慎用或者干脆不使用缓冲区溢出高风险函数
- 不保证补/0的函数,例如strncpy
- pathXXX系列函数有可能buffer溢出,需要排查一遍是否存在这些api的使用
- 参数中不带目标缓冲区长度的字符串处理函数,例如strcpy,strcat,strncat,sprintf,等等
- memcpy最好使用安全版本
2) 看到缓冲区溢出高风险函数,必查溢出
3) 看到可写缓冲区当参数,必查缓冲区长度
业务逻辑篇
除了上述和业务无关的较为通用的具体代码问题外,业务逻辑错误,也需要关注,当然这就需要在深入理解业务需求的基础上了。
慧眼识珠:业务逻辑错误
1) 前提:深入了解被测业务、需求,即深入需求分析、采用测试建模
2) 找开发了解架构设计、代码结构,事半功倍
3) CR可以分阶段进行:
阶段一总览:看到一块代码,不急于研究细节,而是首先根据上下文,函数原型,以及对代码结构的快速扫描,简单得出代码与业务需求的映射;
阶段二深入:根据代码结构深入,可以从核心功能或者感兴趣的部分入手,深入浅出
阶段三回顾:再回头总结思考一下:这个代码块的作用是什么?有何影响?是否正确按照预期实现了业务需求?
4) 识别逻辑错误,需要测试人员在做CR时候,能够经常地从代码中“跳”出来,使用测试思维而不是开发思维,来思考上面的问题、或者跟开发人员沟通。一些逻辑错误,确实可以在思考、沟通的时候自然而然暴露出来。
Code Review规则提取篇
以上介绍了一些常用的CR技巧,那么CR在一定程度上是否也可实现自动化呢,答案是:yes。由于业界的静态代码扫描工具(如klocwork ,cppcheck等),只专注于不存在误报的、能够普遍使用的规则,规则有限且是基础校验,于是管家测试组的 振宇大牛 开发了一套灵活自定义规则的缺陷规则代码扫描工具,规则来源于CodeReview、crash分析、用户反馈分析等。缺陷规则代码扫描专注于静态扫描存在误报的规则以及只有在特定运行时态会Crash的代码规则,可以说补齐了静态代码扫描的短板并实现了一定程度的CR自动化。
应用管理测试组的测试童鞋,从11月至今贡献了 13 条扫描规则(8条已实现自动化,5条作为CR经验),这些规则每天都在跑,并且会随业务增量添加哦。据不完全统计,发现有效bug 60+ ,有效bug解决率 100% 。该自动化扫描目前还会存在一些误报的情况,so,还需要人工过滤。下图显示的是某次的扫描结果,还需要人工check。待将来优化到零误报,则可以节省掉这一部分工作。
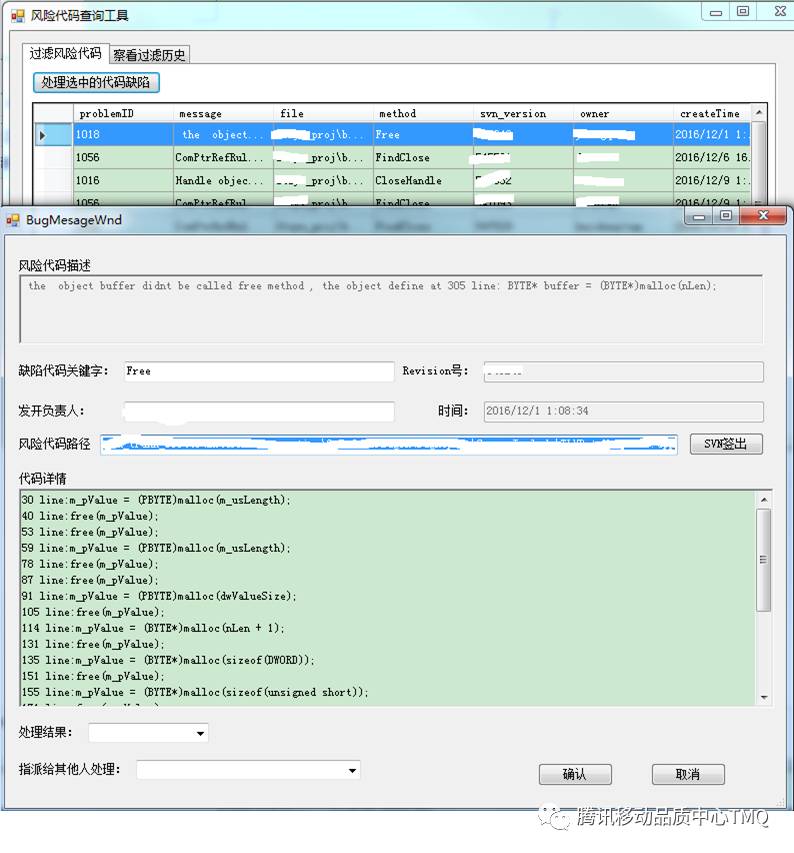
综上所述,作为CR新手的测试人员,笔者只是罗列了一些简单的CR技巧,当然,主要是抛砖引玉,期待大家更多的分享交流,相信1+1>2哦。 最后,希望大家都能慧眼识珠(⊙o⊙),一秒发现bug噢。

版权所属,禁止转载
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

