28 天自制你的 AlphaGo(二):训练策略网络,真正与之对弈
雷锋网 (公众号:雷锋网) 注:本文作者彭博,Blink·禀临科技联合创始人。文章由雷锋网整理自作者 知乎专栏 ,获授权发布,未经允许禁止转载。
上次我们介绍了围棋基础和如何搭建深度学习环境,这篇我们安装 TensorFlow,真正训练一下 AlphaGo v13 的 policy network,并且你还可以与它真正对弈,因为前几天已经有网友在做可以运行的 AlphaGo v13 的简化版:brilee/MuGo。所以这个过程真的已经很傻瓜化,毫不夸张地说,人人都可以拥有一只小狗了,只要你把棋谱喂给它,它就能学到棋谱的棋风。(本文是给大家快速找到感觉,后续我们会从头写代码,因为这位网友的代码真的很多 bug)
如果还没有装 CUDA 等等,请看前一篇《 28 天自制你的 AlphaGo(一) 》装好,记得把 cudnn 解压到 CUDA 的目录。TensorFlow 最近开始原生支持 Windows,安装很方便。
一、Windows 的安装
-
1. 在上一篇我们装了 Anaconda Python 2.7,而 TensorFlow 需要 Python 3.5,不过两者在 Windows 下也可以共存,具体见: Windows下Anaconda2(Python2)和Anaconda3(Python3)的共存 。
-
2. 按上文切换到 Python 3,然后一个命令就可以装好: tensorflow.org/versions/ 。例如 GPU 版本目前是:pip install --upgrade storage.googleapis.com 。但是,你很可能会遇到 404 错误,那么可以把这个文件用迅雷下载下来,然后 pip install 文件名 即可。
-
3. 装完后检验一下。首先进 python 然后 import tensorflow 然后 hello = tf.constant('Hello, TensorFlow!') 然后 sess = tf.Session() 然后 print(sess.run(hello))。
-
4. 然后 python -m tensorflow.models.image.mnist.convolutional 测试训练 MNIST 模型(一开始也会下载数据文件,比较慢)。
二、Mac 的安装
再看看 Mac 的安装。我是 OSX 10.11。
-
1.首先 sudo easy_install pip 然后 sudo easy_install --upgrade six 然后 pip install tensorflow-gpu 即可。
-
2. 可能需要再执行 sudo ln -s /usr/local/cuda/lib/libcuda.dylib /usr/local/cuda/lib/libcuda.1.dylib ,否则 import tensorflow 会报错。
-
3. 用一样的办法检验一下安装是否成功。
三、训练策略网络
激动人心的时刻到了,我们开始真正训练 policy network。下面都以 Windows 下面的操作为例。
1. 把网友做好的 AlphaGo v13 简化版下载下来: brilee/MuGo 。然后 pip install 了 argh 和 sgf。注意 gtp 要额外装: jtauber/gtp (下载下来后用 easy_install . 装)。
2. 然后下载一些用于学习的棋谱。围棋棋谱的通用格式是 SGF。比如,就下载 KGS 的对局棋谱吧:u-go.net 。我没有统计过,不过上面大概有十万局吧。从原理上说,棋谱越多,训练的质量就越有保证;但是,棋谱中对弈者的水平参差不齐,如何控制这一变量,做过深度学习的朋友心中会有答案。本篇先不谈技术细节,我们先继续走。
3. 下面提取棋谱的特征,并将其分类为训练集和测试集。先建立 data 子目录,把 SGF 拷贝进去。例如下载 2014 年的 13029 局棋谱,解压到 data 下面是 kgs-19-2014,那么就执行
python main.py preprocess data/kgs-19-2014
截至今天为止,你会发现它写的 chunk 比预想少很多,所以生成的训练数据很少。具体来说,棋谱的让子大于 4 会崩溃,棋谱没有写明贴目会崩溃,有时候棋谱里面的 [tt] 其实也代表 PASS,等等。做为作业,请自己一个个修复吧! SGF 格式的说明在此: SGF file format FF
4. 再建立一个 tmp 目录,然后开始训练 1 个周期:
python main.py train processed_data --save-file=tmp/savedmodel --epochs=1 --logdir=logs/my_training_run
5. 你会发现策略网络的预测准确率开始从 0 慢慢上升了! 然后可以随时继续训练,比如说继续训练 10 个周期就是:
python main.py train processed_data --read-file=tmp/savedmodel --save-file=tmp/savedmodel --epochs=10 --logdir=logs/my_training_run
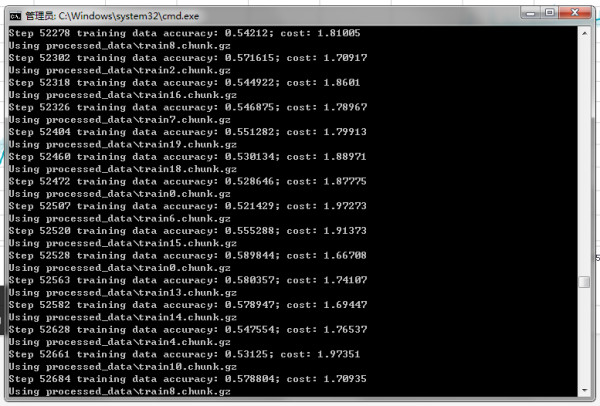
6. 训练的时候,可以再开一个命令行,激活 python3,然后 tensorboard --logdir=logs 然后在浏览器打开 http://127.0.0.1:6006/ 可以看到训练的过程:
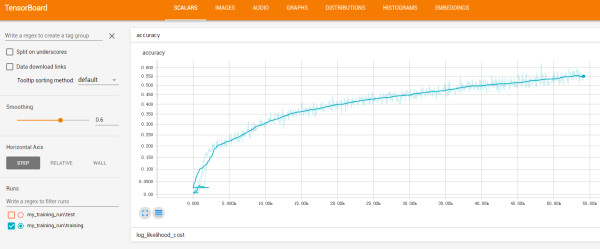
7. 一直训练到准确率增加缓慢为止,应该可以到接近 60%。
8. 测试一下走棋(如果你会 GTP 协议):python main.py gtp policy --read-file=tmp/savedmodel 这是纯网络输出。如果把 policy 改成 mcts 就是加入了蒙特卡洛树搜索的,棋力更高(但是截至今天为止,你执行会发现立刻退出,这位网友的程序 bug 真是太多了,我们以后再重写)。
9. 如果不会 GTP,还是下载 GoGui 围棋图形界面吧: Download GoGui from SourceForge.net 。然后执行:"C:/Program Files (x86)/GoGui/gogui-twogtp.exe" -black "python main.py gtp policy --read-file=tmp/savedmodel" -white "C:/Program Files (x86)/GoGui/gogui-display" -size 19 -komi 7.5 -verbose -auto,但是截至今天为止,你会发现它很快就报错退出......
10. 这是因为截至今天为止,代码有个 bug 是 strategies.py 的第 95 行的函数要改成 is_move_reasonable(position, move) 。然后......你亲手制造的小狗就可以运行了! 黑棋是小狗:
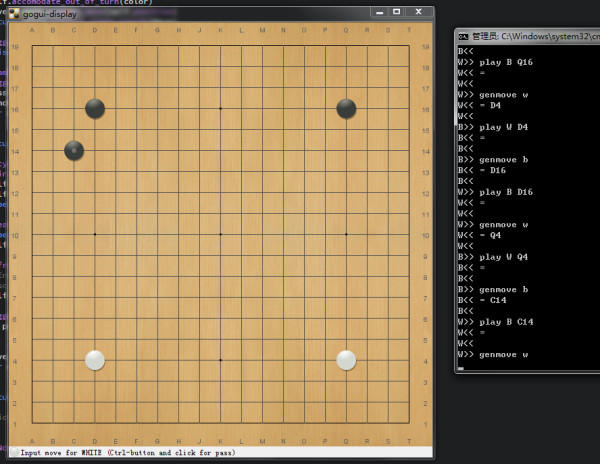
Behold,小狗已经学会了守角! 不过现在他还特别弱,因为没有搜索,容易死活出问题。
11. 如果不会下围棋,让 GnuGo 来玩玩吧,下载链接: gnugo.baduk.org/ ,比如解压到 C:/gnugo/gnugo.exe ,然后执行:"C:/Program Files (x86)/GoGui/gogui.exe" -size 19 -computer-both -auto -program "C:/Program Files (x86)/GoGui/gogui-twogtp.exe -black ""C:/gnugo/gnugo.exe --level 1 --mode gtp"" -white ""python main.py gtp policy --read-file=tmp/savedmodel"" -games 1 -size 19 -alternate -sgffile gnugo -verbose" 即可。你会发现下到后面也会崩溃,如果打开 GTP Shell 看看,是因为小狗还无法理解对方的 PASS,哈哈。
于是,这篇就到此吧,我们下一篇见。
雷锋网特约稿件,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

