谷歌官方解读:如何使用机器学习解决停车难问题
今日,谷歌更新研究博客,介绍了如何用机器学习预测停车难度,从而为司机提供有帮助的停车信息。
大部分驾驶时间要么花费在交通拥堵中,要么是在寻找停车位。因为有 Google Maps 和 Waze 这样的产品,谷歌长期的目标是帮助人们进行轻松、有效的导航。但目前为止,还没有一款解决再常见不过的停车难题的工具。
上周,我们为 Android 上的 Google Maps 添加了一项新功能——在 25 个美国城市中提供停车难度预测,从而能照此进行规划。提供这一功能需要解决一些重大挑战:
-
是否有停车位有极大的变化,涉及到时间、周几、天气、特殊事件、假期等因素。混合这些因素,几乎没有实时的停车位信息。
-
即使有的地区有联网的停车计时器,能够提供可用的信息。但这些数据不包含非法停车、许可停车、提前离开等信息。
-
道路是二维的图像,但停车场结构更复杂,有着不同层的车流。可能也会有不同的布局。
-
停车位的供应与需求都是即时变动的,所以即使是最好的系统都可能更新不及时。
为了解决这些挑战,我们结合了众包与机器学习来建立能够为你提供停车难度信息的系统,而且甚至能帮助你决策采用什么出行方式。在预发布的实验中,我们发现出行模式按钮的点击量有极大的增加,这表明用户获得了停车难度信息之后,更倾向于考虑公共出行方式,而非开车。
建立预测停车难度算法需要 3 项技术:来自众包的好的真值数据(ground-truth data)、合适的机器学习模型、训练模型的一个稳健的特征集。
真值数据
在任何机器学习解决方案中,收集高质量的真值数据一直是个关键挑战。刚开始,我们在不同时间、地点询问个人停车的难度。但我们发现这样一个主观问题会产生不一致的答案,对同一时间段的同一地点,有的人回答「容易」找到停车位,有的人的回答却是「难」。换成「多久能找到停车位?」这样的客观问题,答案的可信度就有了很大的提高,从而能让我们众包高质量的、超过 100k 个回答的真值数据集。
模型特征
有了可用数据,我们开始决定训练模型的特征。幸运的是,我们能够求助于大众的智慧,利用喜欢分享定位的用户提供的匿名聚合信息,这些信息是评估实时交通状况、高流通时间段、访问时长的关键信息源。
我们很快发现即使有了这些数据,仍存在一些独特的挑战。例如,如果一些人停在了门限或者私人的地方,系统不应该认为停车位还很丰富。用户座出租车到达可能是有丰富停车位的一个信号。类似的,公共交通用户可能停在了汽车站。存在的这些假正例都可能会误导机器学习系统。
所以,我们需要更稳健的聚合特征。坦白而言,其中一个特征受到了谷歌所在的山景城的启发。如果谷歌导航在午餐时间观察到许多用户按照以下轨迹在山景城绕圈,那就表明停车位很难找:

我们团队在想如何识别这一停车难度「印迹(fingerprint)」作为训练的特征呢?在这种情况下,我们把用户直接到达目的地时间与绕圈、停车、步行这样实际到达目的地的时间进行了对比,聚合了二者之间的不同。如果许多用户在两种方式之间的时间差距都很大,我们预期这是停车难的有助信号。
之后,我们继续开发更多的特征:特定的目的地、散步的停车地点、停车的时间点与日期(例如,用户在早晨会停的离目的地很近,在高峰时间会很远,这怎么办?)、历史停车数据等等。最后,我们决定了大约 20 个不同的特征。之后,就是调整模型的表现了。
模型的选择和训练
我们决定使用一个标准的 logistic 回归机器学习模型来实现这个功能。原因有几个:
首先,logistic 回归的行为已经得到了很好的理解,而且其往往对训练数据中的噪声有很好的弹性;当数据来自众包或有一个复杂的响应变量时(比如停车难度),这是一个有用的性质。
其次,将这些模型的输出解读为停车困难的概率(probability)是很自然的,然后我们可以将这个概率映射成如「车位有限」或「停车容易」等描述性词汇。
第三,我们可以很容易理解每个特定特征的影响,这让我们可以更轻松地验证该模型的行为是否合理。比如,当我们开始训练过程时,我们中许多人都认为前面所描述的「印迹」特征将会是我们解决问题的「万能药」。我们惊讶地注意到完全不是这么回事——事实证明实际上是基于车位位置分散的特征才是停车难度最强大的预测因素之一。
结果
使用我们的模型,我们能够为任何位置和时间的停车难度生成一个估计。下图给出了我们的系统的输出的几个例子,然后其被用于为指定的目的地提供停车难度估计。比如,星期一早上对整个城市来说都停车困难,尤其是最繁忙的金融和零售区。在星期六晚上,又会再次变得繁忙,但现在却主要集中在餐厅和景点等区域。
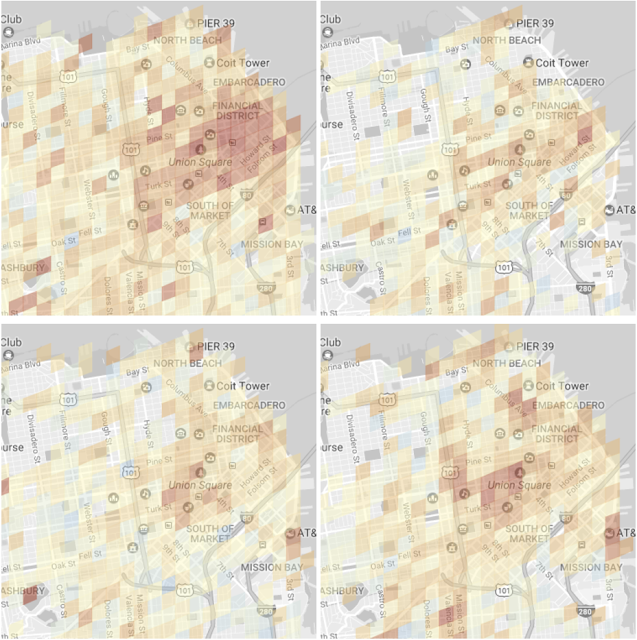
我们的停车难度模型在旧金山 Financial District 和 Union Square 地区上的输出。红色表示有更高置信度的停车困难。上排:一个典型周一的上午 8 点(左)和 9 点(右)。下排:一个典型周六的相同时间。
我们很高兴能有机会基于用户的反馈来继续改进这个模型的质量。如果我们能更好地理解停车困难,我们将能开发出新的更智能的停车助理——我们很高兴未来的机器学习应用能够帮助实现更让人愉快的交通!
正文到此结束
热门推荐










相关文章

近期评论
-
I found this post very interesting and informative. Thank you for sharing your special thoughts with us. My site:
horse racing betting -
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

