专访微软亚洲研究院郑宇:用人工智能进行城市人流预测
在贵阳「块数据」实验室的一块大屏幕上,每一分每一秒都在进入新的数据,不停地预测每个区域有多少辆出租车进和出,这是微软亚洲研究院一个基于云计算和大数据的系统正实时运转,贵阳出租车的数据实时上传作为测试样本,验证模型的准确性和有效性。每点一个格子会跳出一个图表,都能清楚知道整个城市某区域人群流动接下来十几个小时会呈现什么状态,黑色的是已经发生过的出租车进出情况,绿色预测未来部分,蓝色是昨天同一时间的情况。而同样,任何人流预测数据来源,比如手机信号、地铁刷卡记录等,都可以通过该系统模型进行运算得到某地将有多少人进和出的结果,并预测到未来十几个小时的城市人流情况。
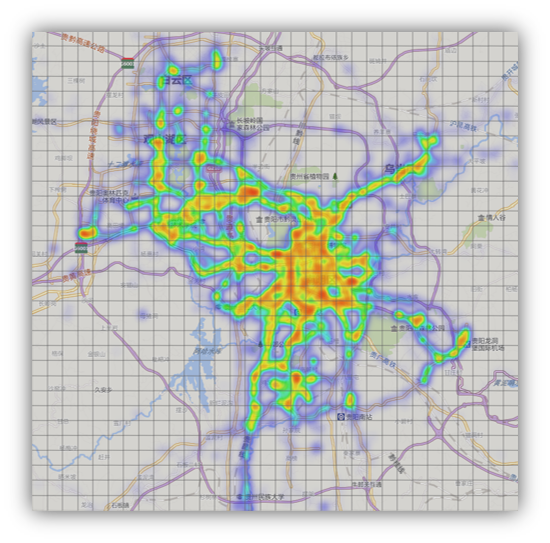
「这个系统背后的模型研究,其目标是预测整个城市里每个区域在未来时刻有多少人进、有多少人出,从而使得管理者能迅速了解每个区域的公共安全状况,及时采取预警措施。」微软亚洲研究院主管研究员郑宇说,直接促使他下决心开展研究的是,2014 年新年夜那场发生在上海的踩踏事件,当时,郑宇曾在微博上呼吁通过基于手机数据的城市异常检测来避免踩踏悲剧。「如果在上海市踩踏事件之前,我们应用了这样的系统,就可以提前给民众发信息,告知他们这里会有多少人进来,提醒注意是否需要提前离开。」郑宇说。
目前,该研究论文《Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction》已经发表在 AAAI 2017,在郑宇看来,除了具有推广应用的社会价值,从技术层面讲,「此前还没有真正意义上为时空数据设计的深度学习算法,这是第一篇论述文章,而未来这个方向的研究还会有更深远的发展。这个发展不是简单的拿来 CNN、RNN 就用,一定是基于对时空数据深刻的理解,充分利用时空数据本身的特性。」在北京,郑宇向《机器之心》解读了这篇论文的研究方法、过程以及正在积极推进的应用方向。
「传统的深度学习方法不能直接拿来用」
以往提及人流预测,通常会采取预测个人行为的方法,理想状态下,只要统计某个区域每个人去哪里就能测算出该区域有多少人进、多少人出。但这样的统计本身有很大的障碍,准确性很难保证,并且涉及隐私。除此之外,传统方法还有一些基于物理学模型、动力学模型或是土木工程的经典模型等,但这些始终难以应对大规模的人流预测。
我们这套方法首先不涉及隐私,只要进和出的数据并不需要知道哪个人进和出,然后把整个城市,比如北京划分成两千个格子同时预测,并不是一个个进行,它是一种整体性的预测。整体性预测的必要性在于,区域和区域之间具有相关性,不能单独预测,在预测 A 的时候,其实预测 B 和 C 区域同样可能产生影响,反之亦然。因此,把深度学习引入进来进行整体预测,与使用传统方法有很大区别。
但同样,我们在研究过程中面临很多困难。首先,会影响人流的因素非常多,与区域里前一个小时有多少人进和出,周边区域甚至是很远的地方有多少人进和出都有关系,比如上海的踩踏事件里,不少人是从外地搭乘高铁、地铁或通过高速公路前往,并不通过周围区域就直接到达了外滩。还有很多外部因素,包括天气、事件都会导致区域人流发生变化。更重要的是,在做预测时,人流具有时空属性,即时间属性和空间属性,这种属性很特别,它会导致其他传统的深度学习方法不能直接拿来用到预测上。
人流作为一种时空属性数据有特定的属性。一个城市有很多区组成,一个区有很多街道和社区,天然有层次感,这是空间的差别,在时间维度上,相邻两个时间点之间,交通量和人流量是一个平滑变化的趋势,但周期性有明显的差别,车流量、人流量是有一个往复的周期性,今天早晨 8 点和昨天早晨 8 点的车流量和人流量趋势看起来很类似,但今天早晨 8 点和今天中午 12 点的流量差别就会很大,虽然它们之间只隔了 4 个小时,而两天早晨之间相隔了 24 小时,时间差更大却更相似。这都是传统视频、图像中不存在的特性,一般情况下,人不会看了五分钟视频又回去看第二分钟的视频,这种周期性是在时空数据也就是人流数据中特有的属性,周期性也不是固定化的而是随着时间的变化呈现趋势性上扬或下降,比如,天越来越冷,天亮的时间越来越晚,人出门的时间也越来越晚,因此早高峰也会越来越晚,所以周期和趋势加在一起,使得时空数据和以前的图像、视频等数据完全不同,以往使用的方法就会失效。
如果我们直接使用传统 RNN,要考虑周期性和趋势性,输入的数据必须很长,如果只使用最近两三个小时的数据,就无法体现周期性,也不可能体现趋势性。要体现周期性至少需要 24 小时以上,而趋势性甚至需要几个月的数据,如果把 RNN 作为模型,这么长的数据作为输入,那么 RNN 模型会变的非常大、非常复杂,最后很难训练,效果也不会好。我们也和 LSTM 做了比较发现,我们数据用的帧数更少,结果反而更好。
「我们设计出一个特殊的网络模型」
我们在北京市的出租车 GPS 轨迹上面做了验证,大概用了约 3 万多辆出租车长达 5 年的数据,同时我们也利用纽约公开的自行车租赁数据做了验证。一方面,我们通过政府合作项目来获取开放给我们的数据,另一方面,我们也要好好利用公开数据。再将这些琐碎的数据转变成有规律的、能够对深度学习作为输入的格式,通过空间的划分和折射,变成一个二维矩阵,使它能够作为深度学习模型的输入。这个转换过程很重要,涉及到不同数据之间的多元化融合,这里需要一些时空数据经验。
基于对时空数据深刻的理解,我们设计出一个特殊的网络模型。在这个结构里,我们只需要抽取一些关键帧,比如说昨天同一时刻,前天同一时刻,其他时间我们可以不做输入,大概只要用几十帧的关键帧作为输入,就可以体现出我们几个月里所包含的周期性和趋势性,使得我们的网络结构大大简化,但训练的质量和效果却大大提高,这是很关键的一点。
具体而言,我们把城市划分成均匀且不相交的网格,比如划分成一个个一平方公里的网格,然后输入人流数据(包括手机、出租车轨迹等)投射在网格里面,计算出每个格子里有多少人进和出。红色越亮的地方就表示人越多,一帧的图像比如说是二维图像,如果有很多时间点就可以持续生成图片,同时我们有对应的事件和天气信息,这就构成了数据的输入,把时空数据转换成这样一个模式。

有了这样的数据之后,再对时间特性进行模拟。我们把最近几个小时、几帧的数据,输入到时空残差网络里面,模拟相邻时刻变化的平滑过程,然后把对应时间点昨天、前天的数据输入来模拟周期性,再把更远的时间点对应的读数拿进来,模拟一个趋势性,分别模拟了三个时间属性。这三个残差网络结构都是深度残差网络,然后做第一次融合,再把外部事件、天气等因素拿进来进行二次融合,得到一个结果。
接着,再进行空间属性模拟。深度卷积神经网络的过程就是把区域划成格子之后,对相关区域进行卷积运算得到一个值,你可以认为,通过一次卷积之后把周围区域人流的相关性抓住了,卷积多次后把更远地方的区域属性都卷积到一起,如果你想捕捉很远的地方,意味着你的卷积网络层次必须要比较深,只有一层抓不到很远地方的相关性。之所以要这样做,是因为之前有提到,很多人可能从外地很远的地方通过高铁或高速公路直接抵达,不会经过你所覆盖到的周边区域。
一旦网络层次比较深,训练会变得非常复杂,基于卷积神经网络,我们引入了深度残差网络结构来做人流预测,用来帮助深度卷积网络提高训练精度,使用这种方法的灵感也来源于我们的前同事孙剑此前的研究。从目前的验证结果来看,这项研究效果最好的是 24 层,但这与不同应用和数据规模都有关系。

此外,在融合相似性、周期性和趋势性这三个模块时,相比于直接的融合,我们提出的基于参数矩阵的融合方法考虑到了每个区域的时间特性的强度不同,因此取得了更好的结果。在最近的研究中,我们已经考虑了门限机制去调控,而非简单的相加,很期待会有更好的实验结果。而 XExt 这部分的输入,已经做过归一化或 one-hot coding,之后经过 FC(或加 embedding)后可以缓解「numerical scales」的问题。事实上,融合依然是一个富有挑战性的难题,异构时空数据的融合仍值得深入研究。
接下来,对于这个模型本身,我们会继续提升,现在只是做到了预测每个区域有多少人进和出,体现出不同区域之间的关系,下个阶段,我们需要同时把每个区域的进和出以及区域和区域之间的进出转移数量都算出来。
而深度学习在时空数据方面的应用,已经是我们组的重点研究方向。人工智能也有它的局限性,并不是像大家想象的那样无所不能,目前看来,我认为利用深度学习来解决大规模物流调度问题的时机已经比较成熟,同时它也会对一系列调度问题产生影响,比如共享单车、外卖、快递等等。
原文 http://www.jiqizhixin.com/article/2261正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

