Scrapy学习(四) 爬取微博数据
Scrapy学习(三) 爬取豆瓣图书信息
接上篇之后。这次来爬取需要登录才能访问的微博。
爬虫目标是获取用户的微博数、关注数、粉丝数。为建立用户关系图(尚未实现)做数据储备
准备
- 安装第三方库
requests和pymongo - 安装MongoDB
- 创建一个weibo爬虫项目
如何创建Scrapy项目之前文章都已经提到了,直接进入主题。
创建Items
Item数据这部分我只需要个人信息,微博数,关注数、分数数这些基本信息就行。
class ProfileItem(Item):
"""
账号的微博数、关注数、粉丝数及详情
"""
_id = Field()
nick_name = Field()
profile_pic = Field()
tweet_stats = Field()
following_stats = Field()
follower_stats = Field()
sex = Field()
location = Field()
birthday = Field()
bio = Field()
class FollowingItem(Item):
"""
关注的微博账号
"""
_id = Field()
relationship = Field()
class FollowedItem(Item):
"""
粉丝的微博账号
"""
_id = Field()
relationship = Field()
编写Spider
为了方便爬虫,我们选择登陆的入口是手机版的微博 http://weibo.cn/ 。
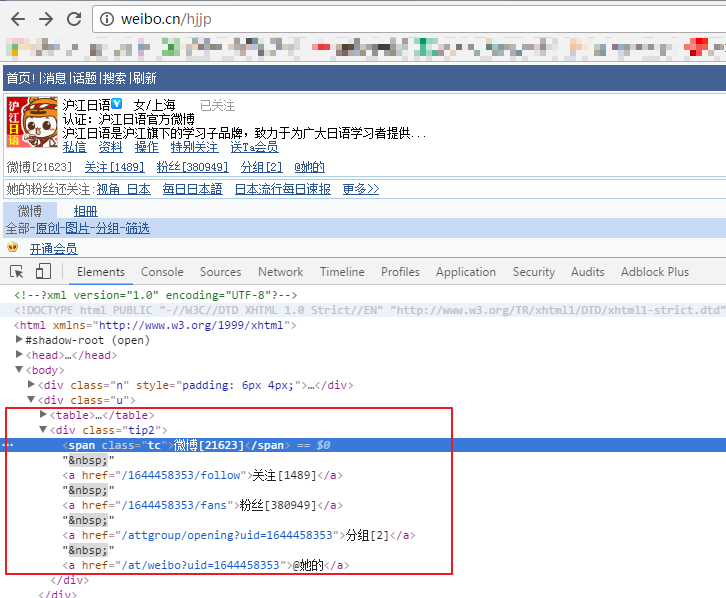
其中微博的uid可以通过访问用户资料页或者从关注的 href 属性中获取
class WeiboSpiderSpider(scrapy.Spider):
name = "weibo_spider"
allowed_domains = ["weibo.cn"]
url = "http://weibo.cn/"
start_urls = ['2634877355',...] # 爬取入口微博ID
task_set = set(start_urls) # 待爬取集合
tasked_set = set() # 已爬取集合
...
def start_requests(self):
while len(self.task_set) > 0 :
_id = self.task_set.pop()
if _id in self.tasked_set:
raise CloseSpider(reason="已存在该数据 %s "% (_id) )
self.tasked_set.add(_id)
info_url = self.url + _id
info_item = ProfileItem()
following_url = info_url + "/follow"
following_item = FollowingItem()
following_item["_id"] = _id
following_item["relationship"] = []
follower_url = info_url + "/fans"
follower_item = FollowedItem()
follower_item["_id"] = _id
follower_item["relationship"] = []
yield scrapy.Request(info_url, meta={"item":info_item}, callback=self.account_parse)
yield scrapy.Request(following_url, meta={"item":following_item}, callback=self.relationship_parse)
yield scrapy.Request(follower_url, meta={"item":follower_item}, callback=self.relationship_parse)
def account_parse(self, response):
item = response.meta["item"]
sel = scrapy.Selector(response)
profile_url = sel.xpath("//div[@class='ut']/a/@href").extract()[1]
counts = sel.xpath("//div[@class='u']/div[@class='tip2']").extract_first()
item['_id'] = re.findall(u'^/(/d+)/info',profile_url)[0]
item['tweet_stats'] = re.findall(u'微博/[(/d+)/]', counts)[0]
item['following_stats'] = re.findall(u'关注/[(/d+)/]', counts)[0]
item['follower_stats'] = re.findall(u'粉丝/[(/d+)/]', counts)[0]
if int(item['tweet_stats']) < 4500 and int(item['following_stats']) > 1000 and int(item['follower_stats']) < 500:
raise CloseSpider("僵尸粉")
yield scrapy.Request("http://weibo.cn"+profile_url, meta={"item": item},callback=self.profile_parse)
def profile_parse(self,response):
item = response.meta['item']
sel = scrapy.Selector(response)
info = sel.xpath("//div[@class='tip']/following-sibling::div[@class='c']").extract_first()
item["profile_pic"] = sel.xpath("//div[@class='c']/img/@src").extract_first()
item["nick_name"] = re.findall(u'昵称:(.*?)<br>',info)[0]
item["sex"] = re.findall(u'性别:(.*?)<br>',info) and re.findall(u'性别:(.*?)<br>',info)[0] or ''
item["location"] = re.findall(u'地区:(.*?)<br>',info) and re.findall(u'地区:(.*?)<br>',info)[0] or ''
item["birthday"] = re.findall(u'生日:(.*?)<br>',info) and re.findall(u'生日:(.*?)<br>',info)[0] or ''
item["bio"] = re.findall(u'简介:(.*?)<br>',info) and re.findall(u'简介:(.*?)<br>',info)[0] or ''
yield item
def relationship_parse(self, response):
item = response.meta["item"]
sel = scrapy.Selector(response)
uids = sel.xpath("//table/tr/td[last()]/a[last()]/@href").extract()
new_uids = []
for uid in uids:
if "uid" in uid:
new_uids.append(re.findall('uid=(/d+)&',uid)[0])
else:
try:
new_uids.append(re.findall('/(/d+)', uid)[0])
except:
print('--------',uid)
pass
item["relationship"].extend(new_uids)
for i in new_uids:
if i not in self.tasked_set:
self.task_set.add(i)
next_page = sel.xpath("//*[@id='pagelist']/form/div/a[text()='下页']/@href").extract_first()
if next_page:
yield scrapy.Request("http://weibo.cn"+next_page, meta={"item": item},callback=self.relationship_parse)
else:
yield item
代码中值得注意的地方有几个。
start_url
这里我们填写的是微博的uid,有的用户有自定义域名(如上图),要访问后才能得到真正的uid
start_url 填写的初始种子数要在10个以上。这是为了确保后面我们爬取到的新的种子能够加入到待爬取的队列中。10个以上的规定是从 Scrapy文档 中查得的
####REACTOR_THREADPOOL_MAXSIZE###
Default:10
线程数是 Twisted 线程池的默认大小(The maximum limit for Twisted Reactor thread pool size.)
CloseSpider
当遇到不需要的继续爬取的连接时(如已经爬取过的链接,定义的僵尸粉链接等等),就可以用 CloseSpider 关闭当前爬虫线程
编写middlewares
class CookiesMiddleware(object):
""" 换Cookie """
def process_request(self, request, spider):
cookie = random.choice(cookies)
request.cookies = cookie
编写cookie的获取方法
这里我原本是想用手机版的微博去模拟登陆的,奈何验证码是在是太难搞了。所以我直接用网上有人编写好的登陆网页版微博的代码 SinaSpider 这位写的很好,有兴趣的可以去看看。其中还有另一位写了模拟登陆(带验证码) 经测试可用。只不过我还没想好怎么嵌入到我的项目中。
# encoding=utf-8
import json
import base64
import requests
myWeiBo = [
{'no': 'xx@sina.com', 'psw': 'xx'},
{'no': 'xx@qq.com', 'psw': 'xx'},
]
def getCookies(weibo):
""" 获取Cookies """
cookies = []
loginURL = r'https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.15)'
for elem in weibo:
account = elem['no']
password = elem['psw']
username = base64.b64encode(account.encode('utf-8')).decode('utf-8')
postData = {
"entry": "sso",
"gateway": "1",
"from": "null",
"savestate": "30",
"useticket": "0",
"pagerefer": "",
"vsnf": "1",
"su": username,
"service": "sso",
"sp": password,
"sr": "1440*900",
"encoding": "UTF-8",
"cdult": "3",
"domain": "sina.com.cn",
"prelt": "0",
"returntype": "TEXT",
}
session = requests.Session()
r = session.post(loginURL, data=postData)
jsonStr = r.content.decode('gbk')
info = json.loads(jsonStr)
if info["retcode"] == "0":
print("Get Cookie Success!( Account:%s )" % account)
cookie = session.cookies.get_dict()
cookies.append(cookie)
else:
print("Failed!( Reason:%s )" % info["reason"].encode("utf-8"))
return cookies
cookies = getCookies(myWeiBo)
登陆-反爬虫的这部分应该是整个项目中最难的地方了。
编写pipelines
这边只需要主要什么类型的Item存到那张表里就行了
class MongoDBPipeline(object):
def __init__(self):
connection = MongoClient(
host=settings['MONGODB_SERVER'],
port=settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.info = db[settings['INFO']]
self.following = db[settings['FOLLOWING']]
self.followed = db[settings['FOLLOWED']]
def process_item(self, item, spider):
if isinstance(item, ProfileItem):
self.info.insert(dict(item))
elif isinstance(item, FollowingItem):
self.following.insert(dict(item))
elif isinstance(item, FollowedItem):
self.followed.insert(dict(item))
log.msg("Weibo added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
运行一下程序,就能看到MongoDB中有了我们要的数据了

正文到此结束
热门推荐









相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

