关于KMP算法的本质之思考
以前看KMP算法的时候,总是无法理解next函数以及next函数的求法以及匹配时j=next[j]的做法的直观意义。这次看《暗时间》这本书的时候谈到一个知识的本质问题,有提到KMP,于是就想着能不能够从本质的角度出发去重新理解下KMP呢?
KMP的本质是什么?或者说,这个算法做了什么?以前的确从来没有问过自己这个问题。或许是习惯于在书上扫一眼KMP是干嘛的,具体怎么操作,怎么用,下次做字符串匹配时套一下模板就好了。但是现在,我要试着探寻一下KMP的内在本质。
上面的问题不难回答,KMP是用来做字符串匹配的,但是,这个答案还不够完善,应该说KMP是能够在O(n+m)时间内完成字符串匹配的一个算法。后者强调了KMP的高效性,相比于朴素的字符串匹配中O(nm)的复杂度,这是一个巨大的提升。
这里我不打算详述KMP算法过程, 字符串匹配的KMP算法. 阮一峰 这篇文章讲解得非常清楚,其实这篇文章是我认为所有的网上博文中解释最通俗易懂的。当然,我在这次的理解中配合了 文章1 和 文章2 来完成理解。
假设原串为S,长度为n,我们需要看字符串f(长度为m)是否在S中。
总的来说,当我们朴素地去进行字符串匹配时,首先将S和f对齐,从头开始匹配过去,我们是发现到哪里不匹配了,就把f右移一位再从头开始一个一个匹配,这样每次移动一位是完全正确的但是不够快,事实上,如果匹配了一些,假如f的前m-1位与S中的一段完全匹配(m-1长),这是一个很好的消息!但最后一位不匹配,如果朴素地右移一位再重新匹配的话,前面m-1位完全匹配的喜人消息会被完全抛弃,那么为什么不利用起来呢?所以说,KMP最本质的思想就在于, 利用已有的一些信息,来加快解空间的搜索 。说起来很简单,但是大道至简,简单的道理却蕴含着巨大的能量。
如何利用呢?盗一张图来说,我们希望找到如图所示的结构:
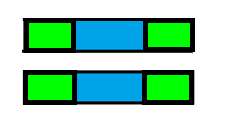
两块绿色的完全相等,这样的话我们移动f时就没必要一步一步移动了,可以直接像下面这样移动,
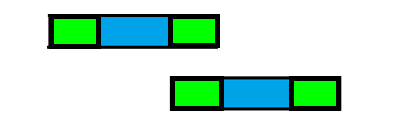
这样大大节省了时间。而next数组就是来找出这样的结构的。
比如f串为 ABCDABD ,它的next数组如下:
f | A B C D A B D next | -1 0 0 0 0 1 2
找出了两个对称的 AB ,即如果匹配到最后的 D 不匹配了,说明需要移动了,又因为 D 之前的串有长度为2的后缀等于前缀,我们可以直接吧f的前缀移到后缀对齐的地方继续走,即
移动长度=已匹配总长度-后缀的长度=已匹配长度-`D`对应的next值=4

j=next[j] 的原因,上面那个例子中j=6,j=next[6]=2,说明下面一步就是,现在的i(i处为 C )和f的下标为j=2处的字符比较,即相当于右移了4位。
一般的KMP核心算法包括以下两个部分:
void getnext()
{
next[0] = -1;
int i = 0,j= -1;
while(i<m-1)
{
if(j== -1 || b[i]== b[j])
next[++i] = ++j;
else
j= next[j];
}
}
int kmp()
{
int i = -1,j= -1;
while(i<n && j<m)
{
if(j== -1 || a[i] == b[j])
i++,j++;
else
j= next[j];
}
if(j== m)
return i-j+1;
return 0;
}
按照上面的思路,就不难理解了。
归根结底一句话,我们要充分利用已经做过的工作中的一些收获和经验,来促进现有问题的解决。抽象到最顶端,KMP就不仅仅是一种算法,更意味着一种解决问题的方式方法了。
正文到此结束
热门推荐









相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

