使用sysbench压力测试MySQL(二)
昨天有了第一篇的测试之后,仅仅是一个开始。
我接下来做sysbench压测的主要思路是根据现有的配置作出调整,能够持续性的优化和压力测试达到目的,而不是简单的去对比连接数在不同数量级会有多大的差别,所以你会在里面看到一些问题的排查,一些问题的解决,可能有些又不是压测相关的。
压测连接数300跑不上去
我设置了max_connections为3000,但是压测的时候到了300个线程就跑不上去了。这个问题很有典型性。
sysbench抛出的错误如下:
FATAL: mysql_stmt_prepare() failed
FATAL: MySQL error: 1461 "Can't create more than max_prepared_stmt_count statements (current value: 16382)"
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:282: SQL API error
MySQL的错误日志信息如下:
2017-03-14T15:01:57.839154Z
348 [Note] Aborted connection 348 to db: 'sysbenchtest' user: 'root'
host: 'localhost' (Got an error reading communication packets)
2017-03-14T15:01:57.839185Z
346 [Note] Aborted connection 346 to db: 'sysbenchtest' user: 'root'
host: 'localhost' (Got an error reading communication packets)
看起来两者关联不大,所以有些信息就会有一些误导了。
根据错误的信息,当前的参数max_prepared_stmt_count设置值为16382,是安装后的默认值。
mysql> show variables like 'max_prepared_stmt_count';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| max_prepared_stmt_count | 16382 |
+-------------------------+-------+
而packet的参数设置为4M的样子,也是默认值
mysql> show variables like '%pack%';
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| max_allowed_packet | 4194304 |
| slave_max_allowed_packet | 1073741824 |
+--------------------------+------------+
到底是不是参数max_allowed_packet引起的呢,我们可以简单模拟一下。
set global max_allowed_packet=33554432;
然后继续运行sysbench脚本:
sysbench /home/sysbench/sysbench-1.0.3/src/lua/oltp_read_write.lua --mysql-user=root --mysql-port=3306 --mysql-socket=/home/mysql/s1/s1.sock --mysql-host=localhost --mysql-db=sysbenchtest --tables=10 --table-size=5000000 --threads=200 --report-interval=5 --time=10 run
结果还是抛出了同样的错误,这也就间接证明了这个问题和这个参数无关,所以我恢复了原来的设置。
然后我们继续调整这个参数max_prepared_stmt_count,把值从16382调整到30000
set global max_prepared_stmt_count=30000;
然后再次运行200个线程,就可以看到没问题了,运行过程中我们可以使用show
global status的方式来查看这个值的变化,这个参数的主要含义是应对瞬间新建的大量prepared
statements,通过max_prepared_stmt_count 变量来控制,这个值是怎么算出来的,还需要细细挖挖。
mysql> show global status like 'Prepared_stmt_count';
+----------------------------+----------+
| Variable_name | Value |
+----------------------------+----------+
| Prepared_stmt_count | 18200 |
+----------------------------+----------+
执行完200个线程后,继续300个,打算以此类推,一直到1000个线程。
执行300个线程的时候,抓取了一下这个参数值,发现已经快溢出了。
mysql> show global status like '%stmt%';
+----------------------------+----------+
| Variable_name | Value |
+----------------------------+----------+
| Prepared_stmt_count | 27300 |
+----------------------------+----------+
10 rows in set (0.00 sec)
所以自己简单做了个计算,
200个线程参数值为 18200
300个线程参数值为 27300
通过简单的计算可以看出100个线程对应参数值9100,按照这个参数设置,我要运行500个线程,30000这个参数值是肯定不够的。很快就验证了我的这个想法,抛出错误了。所以我调整了参数值为100000,在900个线程都没有任何问题。
这是分别对应50个,300个,500个线程时候的TPS测试结果,QPS基本是TPS的20倍。
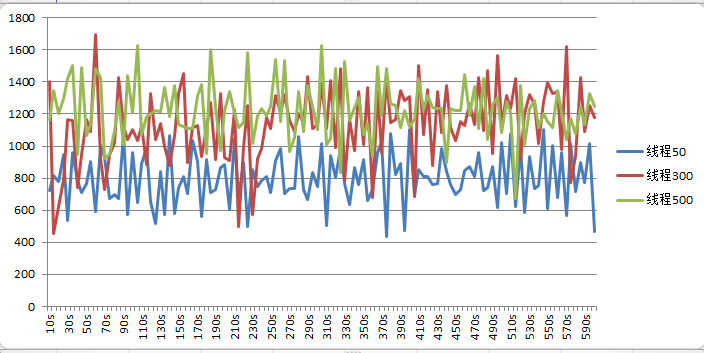
然后我继续测试1000个线程的时候,发现跑不上去了。
压到1000的时候,抛出了下面的错误。
FATAL: unable to connect to MySQL server on socket '/home/mysql/s1/s1.sock', aborting...
FATAL:
error 1135: Can't create a new thread (errno 11); if you are not out of
available memory, you can consult the manual for a possible
OS-dependent bug
这个时候查看资源的使用情况如下:
# ulimit -a
。。。
open files (-n) 1024
pipe size (512 bytes, -p) 8
max user processes (-u) 1024
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
值得一提的是在RedHat 6中,在/etc/security/limits.conf设置用户为*的时候,完全不会生效,需要制定具体的用户,
比如下面的配置就不会生效,需要指定为root
* soft nproc 65535
* hard nproc 65535
再次可以引申出两点,一个是修改了资源设置之后,已有的MySQL服务就需要重启,因为资源设置还是旧的值,如何查看呢。可以使用pidof来查看/proc下的设置。
# cat /proc/`pidof mysqld`/limits | egrep "(processes|files)"
Max processes 1024 256589 processes
Max open files 15000 15000 files
第二点就是在RedHat 6中,我们其实需要设置另外一个参数文件,/etc/security/limits.d/90-nproc.conf
在这个文件中做如下的配置,对所有用户生效。
* soft nproc 65535
修改后重启MySQL服务即可生效,再次开启测试就没有问题了,说明这个地方的错误和参数nproc还是有密切的关系,但是open files目前还是1024暂时还没有问题。
这是当时测试的一个初步结果。可以看到线程50,500,1000的时候的TPS情况,线程1000的指标似乎没有什么提升。
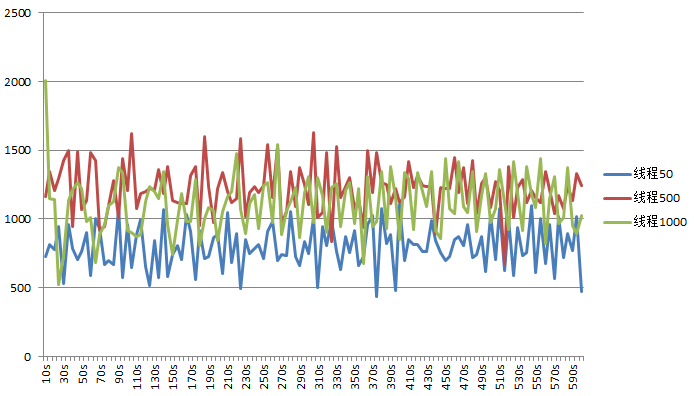
线程达到了1000,我们的基准测试也有了一个阶段性的成果,那就是最起码支持1000的连接是没有问题了,但是测试结果还是让人不大满意,至少从数字上来看还是有很大的瓶颈。
问题出在哪里了呢,首先机器的配置较差,这是个不争的事实,所以你看到的结果和很多网上高大上的结果有较大的出入。
另外一点是默认参数层面的优化,我们使用的是Lua模板读写兼有。压力测试的过程中生成了大量的binlog,而对于InnoDB而言,我们需要明确在IO上的几点可能,一个是刷数据的效率,一个是redo的大小,还有一些已有的优化方式改进。我们来简单说一下。
MySQL里有类似Oracle中LGWR的一个线程,在5.7中默认是16M,早先版本是8M.因为刷新频率很高,所以这个参数一般不需要调整。
mysql> show variables like 'innodb_log_buffer_size';
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| innodb_log_buffer_size | 16777216 |
对于redo的大小,目前是50M,还有个group的参数innodb_log_files_in_group,默认是2,即两组,可以理解为Oracle中的两组redo日志。
mysql> show variables like 'innodb_log%';
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| innodb_log_buffer_size | 16777216 |
| innodb_log_checksums | ON |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_log_write_ahead_size | 8192 |
+-----------------------------+----------+
在这个压力测试中,频繁的写入binlog,势必会对redo的刷新频率极高。
我们抓取一个测试中的InnoDB的状态:
mysql -e "show engine innodb status/G"|grep -A12 "Log sequence"
Log sequence number 39640783274
Log flushed up to 39640782426
Pages flushed up to 39564300915
Last checkpoint at 39562272220
0 pending log flushes, 0 pending chkp writes
93807 log i/o's done, 198.50 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 26386366464
Dictionary memory allocated 555380
Buffer pool size 1572768
Free buffers 1048599
简单来做个计算,可以看到Log sequence number的值减去Last checkpoint at的值,大概是70M左右
mysql> select 39640783274-39562272220;
+-------------------------+
| 39640783274-39562272220 |
+-------------------------+
| 78511054 |
+-------------------------+
redo文件设置为多大,其实没有一个绝对的概念,在Percona的建议中,在压力测试中可以设置为1G或者2G,最大设置为4G,因为本身会直接影响到恢复的效率。
调整redo的大小还是尤其需要注意,在这一点上MySQL没准以后会有所改进,Oracle中的redo修改还是值得借鉴的。像5.7中的undo已经可以截断,逐步的剥离出来,都是一点点的改进。
怎么修改redo的大小呢,要正常停库,然后删除默认的两个redo文件,保险起见,你可以先备份出来也行,然后修改参数文件的redo文件参数,启动MySQL,当然开始的时候会识别不到redo文件会自动创建两个新的。
下面的结果很有代表性,是暂时修改redo为100M时的TPS情况。左下角蓝色的部分是原来10分钟内的TPS情况,红色的部分是2个多小时里的TPS情况,可以看到基本是稳定的,而且是原高于原来同样线程数的TPS.
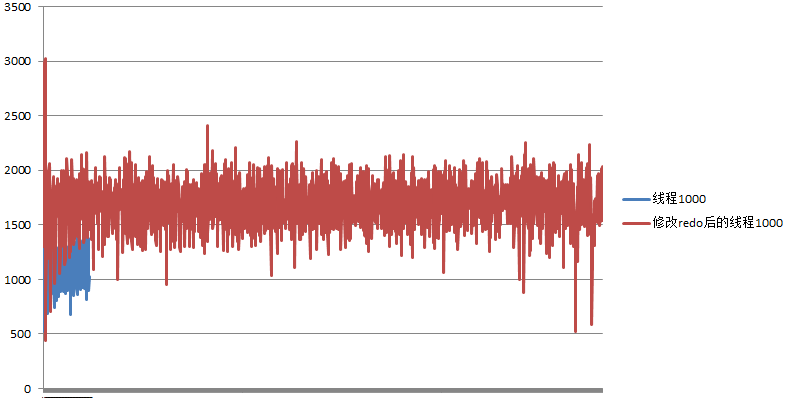
后续改如何优化呢,还有更多内容值得分享出来。
参考资料http://www.ceus-now.com/mysql-innodb-page-cleaner-settings-might-not-be-optimal/
https://www.percona.com/blog/2013/02/04/cant_create_thread_errno_11/
https://www.percona.com/blog/2006/07/03/choosing-proper-innodb_log_file_size/
https://www.percona.com/blog/2011/07/09/how-to-change-innodb_log_file_size-safely/
正文到此结束
热门推荐









相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

