一张价值百万美元的PPT——人工智能领域的创投机会

在旧金山湾区的星巴克里,我见到了 人工智能初创公司 cNeuron创始人胡遇杰 ,本来一开始是聊他的公司,后来却聊起了人工智能在芯片领域的创业机会。
胡遇杰 给我展示了一张PPT,并跟我说, 这是一张价值百万美元的PPT ,投资人和创业者们照着这方向投/做就可以。 (我们把PPT的缩略版放在了文末) 。
胡遇杰在半导体行业有13年经验,专注于High speed/high throught/low latency/dsp/deep learning Infrastructure,曾就职于爱立信、Brocade、Broadcom、Cadence,如今是人工智能初创公司cNeuron的创始人。
“现在这个世界啊,变化很快!计算机的诞生是为了数值计算诞生的,但现在更多的是用于处理信息。”
“ 计算机都应该被改造 !冯诺依曼体系结构这都是个上个世纪的体系系统了。数据和计算分开,是那个时代的产物,因为当时的计算单元非常宝贵。”
“而如今计算资源不是问题了,而现在的做深度学习的瓶颈是带宽。现在大部分人工智能计算的资源都花在存储和传输(I/O)上,反而只有少部分时间用在了计算上。”
我们在上面三点上都达成了共识,能侧面证明这一点的是,很多芯片现在大部分面积都是存储单元而不是计算单元。芯片上面积非常珍贵,寸土寸金,而以Myriad 2 Die芯片为例,已经是大量面积用在了存储和相关逻辑上,存储家族已经占了很大的面积。
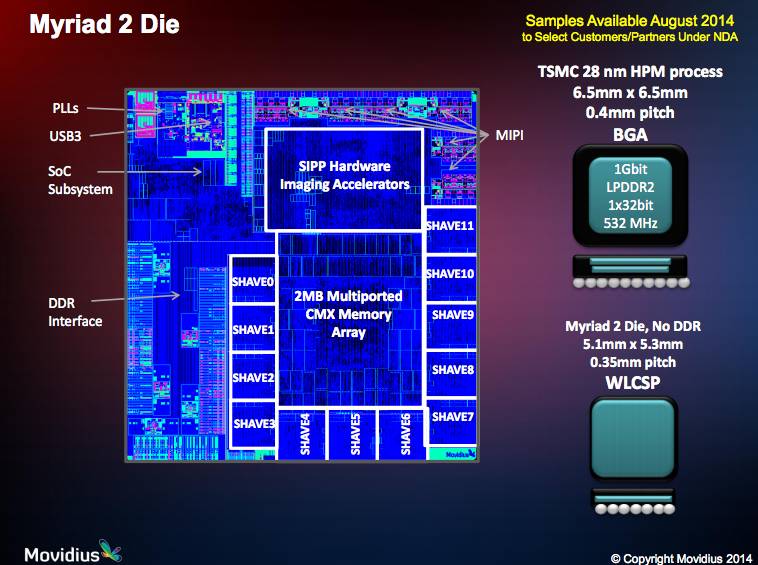
其实存储不是根本的问题,人工智能计算最大的瓶颈其实是存储读写带宽。
为了解决带宽问题,GPU 的 Memory 从 DDR3 ,DDR4,一直升级到了 HBM。
但 这就好像是编无数个谎言来圆一个谎言 ,无论是CPU还是GPU,他们最早都是为了数值计算而设计,而在人工智能时代,老革命遇到新问题,大家都是在各种修修补补。
冯诺依曼体系结构的问题其实早就被人提出来,也早就有人提出了新的架构,只是没有达到可以商业化的目的,做出来也没有人用,因为以前的应用场景并没有那么多。
而如今的人工智能计算已经和数值计算的差异越来越大,如果人工智能在未来会成为一项基础能力,那么是时候思考一个全新的体系结构。
讲到这里,既然现在计算的瓶颈在带宽和I/O,那么一个可能的答案就是:
“让数据待在那里不动,能不动,就不动。”
这个在软件层面上其实已经已经有不少尝试了,而围绕这个,半导体就有很多技术出来了,主要可以分为三大方向。
第一、增加带宽
比如被英特尔收购人工智能创业公司Nervana Systems,Nervana的芯片在设计上把存储和计算单装在一起(HBM),物理上离得很近,时钟频率就可以跑得很高。
Nervana Systems里面用到了HBM技术,通过提升存储的速度和带宽的增加来提升计算效率。英伟达最新的Pascal也用了这个技术。
第二、充分利用带宽
在内存成为瓶颈的时候,现在大量带宽没有充分利用,比如通常现在的DDR(内存)存储接口,一次读的是一块数据,而有很多数据读取是浪费的,里面被充分利用的数据可能只是一小部分。
所以思考如何充分利用带宽是一个优化的方向。
第三、提高单个字节的计算量(computation per byte)
计算数据来自于外部存储,如果把一个字节读完,一次计算就送回来,一读一写总I/O就是2倍的数据量也就是2字节。
如果把一个字节读完,然后把所有相关的计算尽量多做,比如八次计算全部完成只需要一次读写操作,那么单个字节的计算量就翻了八倍。
当然计算有优先序,如何通过优化把计算合并到一起,这里面有很多细节的问题,比如一个矩阵如何存储,里面很多优化空间。
胡遇杰终于给我们讲到了那张价值百万美元的PPT,他自信地跟我重申, 这是一个价值百万美元的PPT,投资人们照着这个投就可以。
我们把精简版放在文章里。
第一块是人工智能在数据中心内的行业机会。
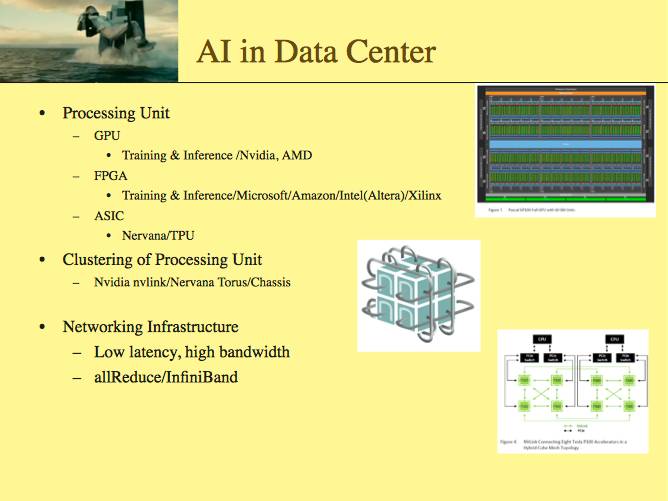
从底层往上讲,包括从计算单元到网路基础设施。
从计算单元来看,训练的市场没有推理的市场大。半导体投资很大,GPU肯定不适合创业公司做,除非有大资金支持。
FPGA既可以做训练(Training),也可以做推理(Inference),而FPGA做推理比GPU高很多,这一块FPGA是有价值的,成本低,也适合创业团队来做
做ASIC也是有价值的。Google的TPU也不太可能对外卖,Nervana在没有流片成功的情况下,依然卖了一个好价钱。
Nervana在芯片设计上做了很多优化,比如加了计算单元的互联,但是Nervana还没有做到极致,还有提升的空间,
然后在计算单元的集合上,也有各种各样的技术,比如Nvidia用的nvlink比较基础,到节点多了就较难拓展。Nervana Torus看起效能不错,但没有验证。 可以用Chassis做到点对点的网络。还有其他好几种技术都能有用于提升效率。
而在网络基础设施上,allReduce是在超级计算里用过的很老的的技术,而InfinitiBand效率都比以太网有所提高,但较贵。
胡遇杰表示总体而言Data center里面的机会大部分会被大佬通吃,而机会更多的是会是在终端上。

在我们的邀请下, 胡遇杰将登陆硅谷Live,为我们详解人工智能芯片领域的创业机会, 对于创业和投资人士这可能是价值百万美元的分享。
关于cNeuron Technology:
cNeuron是一家人工智能领域的创业公司,专注于提供深度学习处理器在FPGA,ASIC中的架构与实现方案(CNN,RNN,DNN),具有深度学习加速器的下一代视觉处理器单元(VPU),可用于无人机,监控摄像机,自动驾驶车。另外还提供芯片SoC网络和高吞吐量,低功耗,高效率的处理器阵列。

正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

