mysql hash索引
今天研究下mysql中索引,首先我应该知道的是,mysql中不同存储引擎的索引工作方式不一样,并且不是所有的存储引擎都支持所有类型的索引。即使多个存储引擎支持同一种类型的索引,那么他们的实现原理也是不同的。不同的引擎对于索引有不同的支持:Innodb和MyISAM默认的索引是Btree索引;而Mermory默认的索引是Hash索引。
mysql中主要有哈希索引(hash index)、B-Tree索引,全文索引、以及空间数据索引(R-Tree);
今天主要讲下mysql中的哈希索引(hash index)
它是基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),哈希码是一个较小的值,大部分情况下不同的键值的行计算出来的哈希码是不同的,但是也会有例外,就是说不同列值计算出来的hash值一样的(即所谓的hash冲突),哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每一个数据行的指针,hash很适合做索引,为某一列或几列建立hash索引,就会利用这一列或几列的值通过一定的算法计算出一个hash值,对应一行或几行数据。
hash 索引的实现原理如下图:

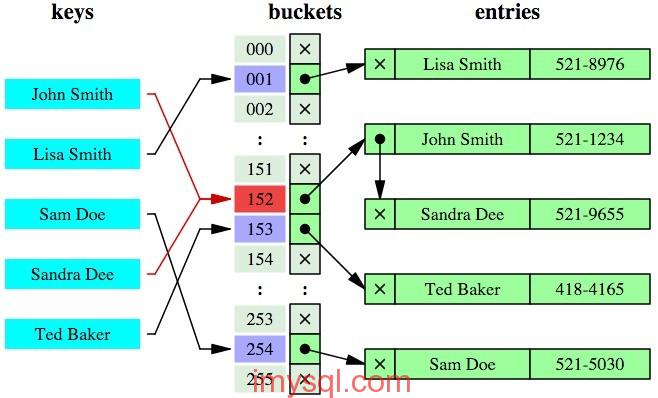
针对上图的理解:
keys:代表创建索引的列值;
buckets: 就是计算出来的hash值和对应的数据的物理位置组成的hash表;
entries:就是代表具体的数据行;
创建hash索引后,会为每个键值通过特定的算法计算出一个哈希码(hash code),需要注意的是不同的键值计算出来的hash值可能是相同的,例上图上的 John Smith 和Sandra Dee算出来的hash值都是152,然后找到hash值为152在hash表中的存储数据的物理位置,这个位置对应着两条数据也(就是John Smith 521-1234 和Sandra Dee 521-9655),然后再次遍历这两条数据,找到需要的数据,这就解释了为啥hash冲突严重了,hash索引效率降低的原因。
hash索引检索数据的过程(摘杂网络)
当我们为某一列或某几列建立hash索引时(目前就只有MEMORY引擎显式地支持这种索引),会在硬盘上生成类似如下的文件:
| hash值 | 存储地址 |
| 1db54bc745a1 | 77#45b5 |
| 4bca452157d4 | 76#4556,77#45cc… |
…
hash值即为通过特定算法由指定列数据计算出来,存储地址即为所在数据行存储在硬盘上的地址(也有可能是其他存储地址,其实MEMORY会将hash表导入内存)。
这样,当我们进行WHERE age = 18 时,会将18通过相同的算法计算出一个hash值==>在hash表中找到对应的储存地址==>根据存储地址取得数据==>最后一步确定这行数据是否是需要查询的数据。
所以,每次查询时都要遍历hash表,直到找到对应的hash值,数据量大了之后,hash表也会变得庞大起来,性能下降,遍历耗时增加;
MySQLhash索引的适用情况:
检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快,但是哈希索引只适合某些特定的场景,而一旦适合哈希索引,则它带来的性能提升非常明显,除了memory引擎外,NDB引擎也支持唯一哈希索引;
innodb引擎有一个特殊的功能叫做自适应哈希索引,当innodb注意到某些索引值被使用的非常频繁时,它会在内存中基于btree索引之上再创建一个哈希索引,这样就让btree索引也具有哈希索引的一些优点,比如:快速的哈希查找,这是一个全自动的,内部的行为,用户无法控制或者配置,不过如果有必要,可以选择关闭这个功能(innodb_adaptive_hash_index=OFF,默认为ON)。
正是因为hash表在处理较小数据量时具有无可比拟的素的优势,所以hash索引很适合做缓存(内存数据库)。如mysql数据库的内存版本Memsql,使用量很广泛的缓存工具Mencached,NoSql数据库redis等,都使用了hash索引这种形式。当然,不想学习这些东西的话Mysql的MEMORY引擎也是可以满足这种需求的。
mysql hash索引的局限性:
(1)Hash 索引仅仅能满足"=","IN"和"<=>"的等值查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)因为哈希索引并不是按照索引值顺序存储的,所以Hash 索引无法被用来避免数据的排序操作。 由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash 索引不能利用部分索引键查询,也就是针对组合索引,不支持最左匹配原则
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用,也就是说,在数据列(A,B)上建立哈希索引,如果查询只有数据列(where A=)是无法使用该索引的。
(4)Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于相同的列值计算出来的 Hash 值可能一样的,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键(存在大量hash冲突,也就是大量重复值,可选择率高代表选出来的值/去重的值 比较大),如果创建 Hash 索引,那么将会存在大量记录指针信息和同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
(6) 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行(即不能使用哈希索引来做覆盖索引扫描),不过,访问内存中的行的速度很快(因为memory引擎的数据都保存在内存里),所以大部分情况下这一点对性能的影响并不明显。
(7)如果哈希冲突很多的话,一些索引维护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应的引用,冲突越多,代价越大。
总结: 如果hash键值没有重复值,并且数据量较小时,通过hash索引检索数据还是比btree索引快的,但是当哈希值大量重复且数据量非常大时,其检索效率并没有Btree索引高的。哈希索引只适合某些特定的场景,而一旦适合哈希索引,则它带来的性能提升非常明显的,因为它不会像btree索引那样一级一级的去遍历检索得到数据。Hash索引结构的特殊性,让他的检索效率非常高,索引的检索可以一次定位,不像BTree索引需要从根节点到枝节点,最后才能访问到叶节点这样多次的I/O访问,所以Hash索引的查询效率要远高于BTree索引。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

