Java 可重入锁内存可见性分析
不可错过的 Java 技术公众号
送架构书活动正在进行中
架构书籍推荐:Java中高级、架构师值得一读!
周童
来自酒店搜索报价中心,主要负责酒店报价缓存,计算相关系统的开发以及性能优化等工作,热爱摩旅。
一个习以为常的细节
之前在做 ReentrantLock 相关的试验,试验本身很简单,和本文相关的简化版如下: (提示:以下代码均可左右滑动)
就是通过可重入锁的保护并行对共享变量进行自增。
突然想到一个问题: 共享变量 count 没有加 volatile 修饰,那么在并发自增的过程当中是如何保持内存立即可见的呢? 上面的代码做自增肯定是没问题的,可见 LOCK 不仅仅保证了独占性,必定还有一种机制保证了内存可见性。
可能很多人和我一样,对 LOCK 的认知是如此 “理所应当”,以至于从没有去思考为什么。就好像每天太阳都会从东方升起而不觉得这有什么好质疑的。现在既然问到这儿了,那就准备一探究竟。
几个概念
Java Memory Model (JMM)
即 Java 内存模型,直接引用 wiki 定义:
"The Java memory model describes how threads in the Java programming language interact through memory. Together with the description of single-threaded execution of code, the memory model provides the semantics of the Java programming language."
JMM 定义了线程和内存之间底层交互的语义和规范,比如多线程对共享变量的写 / 读操作是如何互相影响。
Memory ordering
Memory ordering 跟处理器通过总线向内存发起读 (load)写 (store)的操作顺序有关。对于早期的 Intel386 处理器,保证了内存底层读写顺序和代码保持一致,我们称之为 program ordering,即代码中的内存读写顺序就限定了处理器和内存交互的顺序,所见即所得。而现代的处理器为了提升指令执行速度, 在保证程序语义正确的前提 下,允许编译器对指令进行重排序。也就是说这种指令重排序对于上层代码是感知不到的,我们称之为 processor ordering.
JMM 允许编译器在指令重排上自由发挥,除非程序员通过 synchronized/volatile/CAS 显式干预这种重排机制,建立起同步机制,保证多线程代码正确运行。
Happens-before
对于 volatile 关键字大家都比较熟悉,该关键字确保了被修饰变量的内存可见性。也就是线程 A 修改了 volatile 变量,那么线程 B 随后的读取一定是最新的值。然而对于如下代码有个很容易被忽视的点:
当线程 A 执行完 line 2 之后, 变量 a 的更新值也一同被更新到内存当中 ,JMM 能保证随后线程 B 读取到 b 后,一定能够看到 a = 1。之所以有这种机制是因为 JMM 定义了 happens-before 原则,直接贴资料:
-
Each action in a thread happens-before every action in that thread that comes later in the program order
-
An unlock on a monitor happens-before every subsequent lock on that same monitor
-
A write to a volatile field happens-before every subsequent read of that same volatile
-
A call to Thread.start() on a thread happens-before any actions in the started thread
-
All actions in a thread happen-before any other thread successfully returns from a Thread.join()on that thread
其中第 3 条就定义了 volatile 相关的 happens-before 原则,类比下面的同步机制,一图胜千言:
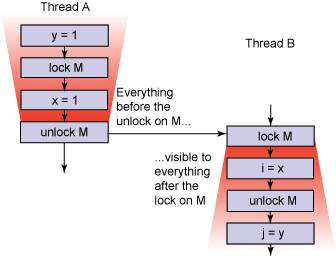
也就是说 volatile 写操作会把之前的共享变量更新一并发布出去,而不只是 volatile 变量本身。Happens-before 原则会保证 volatile 写之后,针对同一个 volatile 变量读,后面的所有共享变量都是可见的。
初步释疑
Happens-before 正是解释文章开头问题的关键,以公平锁为例,我们看看 ReentrantLock 获取锁 & 释放锁的关键代码:
简单来说就是对于每一个进入到锁的临界区域的线程,都会做三件事情:
-
获取锁,读取 volatile 变量;
-
执行临界区代码,针对本文是对 count 做自增;
-
写 volatile 变量 (即发布所有写操作),释放锁。
结合上面 happens-before 概念,那么 count 变量自然就对其它线程做到可见了。
事情还没有结束
我们只是利用 volatile 的 happens-before 原则对问题进行了初步的解释,happens-before 本身只是一个 JMM 的约束,然而在底层又是怎么实现的呢?这里又有一个重要的概念:内存屏障(Memory barriers)。
我们可以把内存屏障理解为 JMM 赖以建立的底层机制,wiki 定义:
"A memory barrier , also known as a membar, memory fence or fence instruction , is a type of barrier instruction that causes a central processing unit (CPU) or compiler to enforce an ordering constraint on memory operations issued before and after the barrier instruction. This typically means that operations issued prior to the barrier are guaranteed to be performed before operations issued after the barrier."
简而言之就是内存屏障限制死了屏障前后的内存操作顺序,抽象出来有四种内存屏障(因为内存 load/store 最多也就四种组合嘛),具体实现视不同的处理器而不同,我们这里看最常见的 x86 架构的处理器: 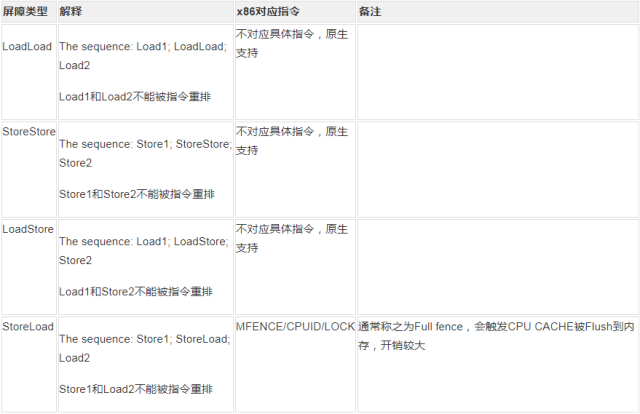 volatile 的 happens-before 原则其实就是依赖的 StoreLoad 内存屏障,重点关注 LOCK 指令实现,这和 volatile 的底层实现息息相关,查看下面代码片段对应的汇编代码:
volatile 的 happens-before 原则其实就是依赖的 StoreLoad 内存屏障,重点关注 LOCK 指令实现,这和 volatile 的底层实现息息相关,查看下面代码片段对应的汇编代码:
利用 hsdis 查看对应汇编片段(只包含关键部分):  可以看到在 set() 方法对 a,b,c 赋值后,多出了一行 "lock addl $0x0,(%rsp)",这行代码只是对 stack pointer 加 0,无含义。但通过上文我们得知,x86 架构处理器的 LOCK prefix 指令相当于 StoreLoad 内存屏障。LOCK prefix 的指令会触发处理器做特殊的操作,查看 Intel 64 and IA-32 开发手册的相关资料:
可以看到在 set() 方法对 a,b,c 赋值后,多出了一行 "lock addl $0x0,(%rsp)",这行代码只是对 stack pointer 加 0,无含义。但通过上文我们得知,x86 架构处理器的 LOCK prefix 指令相当于 StoreLoad 内存屏障。LOCK prefix 的指令会触发处理器做特殊的操作,查看 Intel 64 and IA-32 开发手册的相关资料:
"Synchronization mechanisms in multiple-processor systems may depend upon a strong memory-ordering model. Here, a program can use a locking instruction such as the XCHG instruction or the LOCK prefix to ensure that a read-modify-write operation on memory is carried out atomically. Locking operations typically operate like I/O operations in that they wait for all previous instructions to complete and for all buffered writes to drain to memory."
LOCK prefix 会触发 CPU 缓存回写到内存,而后通过 CPU 缓存一致性机制(这又是个很大的话题),使得其它处理器核心能够看到最新的共享变量,实现了共享变量对于所有 CPU 的可见性。
总结
针对本文开头提出的内存可见性问题,有着一系列的技术依赖关系才得以实现:count++ 可见性 → volatile 的 happens-before 原则 → volatile 底层 LOCK prefix 实现 → CPU 缓存一致性机制。
补充一下,针对 ReentrantLock 非公平锁的实现,相比公平锁只是在争夺锁的开始多了一步 CAS 操作,而 CAS 在 x86 多处理器架构中同样对应着 LOCK prefix 指令,因此在内存屏障上有着和 volatile 一样的效果。
参考资料
http://gee.cs.oswego.edu/dl/jmm/cookbook.html
https://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.html 第 8 章
https://www.ibm.com/developerworks/library/j-jtp03304/index.html
https://stackoverflow.com/questions/2972389/why-is-compareandswap-instruction-considered-expensive
http://ifeve.com/java-memory-model-5/
https://en.wikipedia.org/wiki/Memory_barrier
https://en.wikipedia.org/wiki/Java memory model
觉得有用就 转发分享 一下吧
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

