MapReduce 设计与实现
我曾经多次提到过,我涉猎广泛,但是没有有个精通的技能,在大数据领域几年,也没什么成果。
我开始尝试改变,未来很长一段时间注重修炼内功,是什么让我有这样的改变? 极客时间 购买《朱赟的技术管理课》, 安姐 聊到很多技术管理经验,介绍算法一节: 招式在花哨,敌不过内功深厚 。 安姐 重写了四遍《算法导论》中的习题,让她算法特别厉害,也介绍算法的实际意义和价值。
我未来计划往分布式数据库相关领域研究,制定一系列计划,当然去年底就开始执行,通过相关项目、论文、书籍,深入理解计算机科学技术。
欢迎star: https://github.com/jikelab/paper
我的开源项目 企业级流分析平台 ,即将上线,辛苦码文档中,已发布预览版,月底和大家见面,稍待。
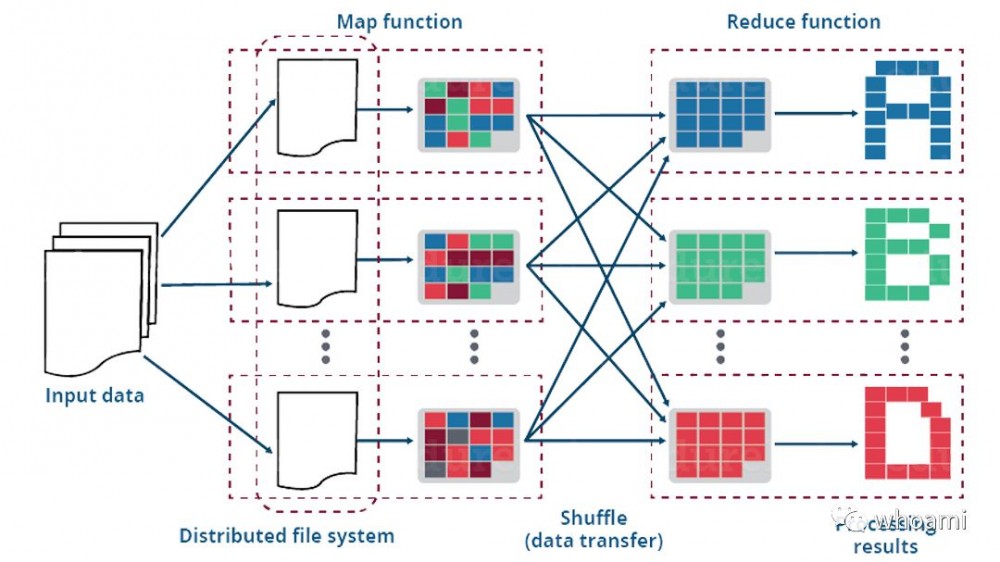
废话已然太多,今天我们谈MapReduce的核心原理,我的阅读笔记。
MapReduce设计初衷:
[1] x86架构,Linux系统,2-4G内容
[2] 普通网络硬件设备,百兆/千兆带宽
[3] 集群规模成百上千台,机器故障是常态
[4] Schedule -> Job -> n Task
MapReduce为何如此简单,很快被大规模应用。MapReduce利用限制性编程模式实现了用户的自动并发处理,并且提供了透明的容错处理功能。
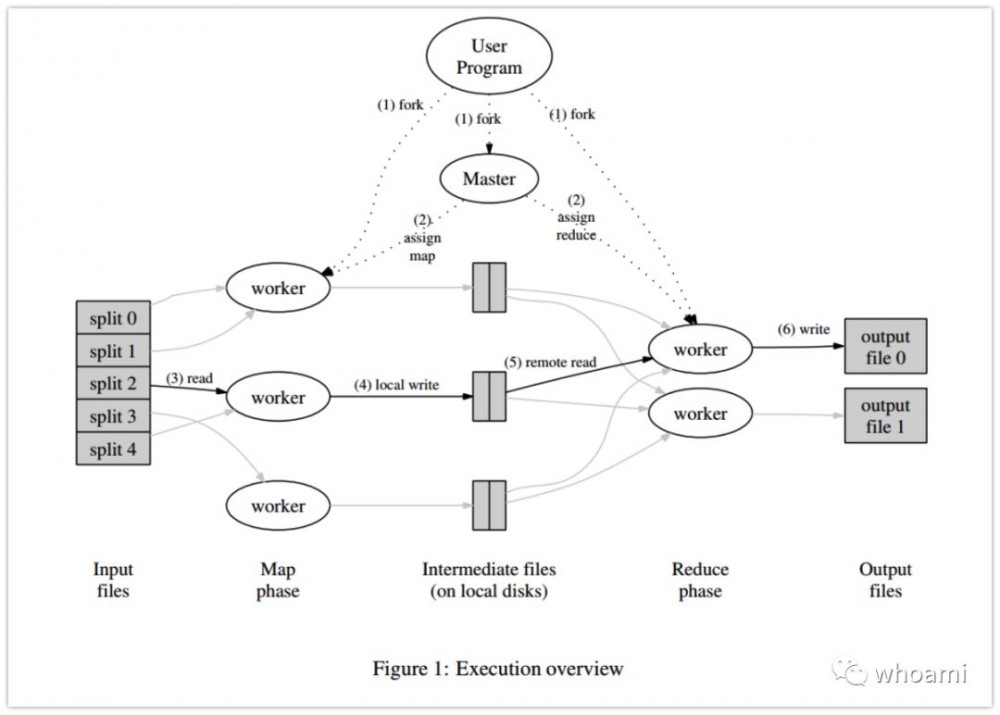
Master数据结构,主要调度、监视、Job Metadata信息(存储中间临时数据存储区域、大小与位置)。
Worker执行任务,Master调度Job Worker执行任务,通过RPC远程过程调用,Worker周期性执行Job状态汇报,通过心跳机制,超时未汇报,标记为故障节点,Master会进行处理。
容错特性,设计初衷使成百上千台机器组成集群,从而处理大规模数据。
Worker故障
情况一:
master周期性的ping worker节点,如果都能正常反馈,说明无故障。
情况二:
如果超时无反馈,master标记worker节点为失效节点。
故障情况下,master需要重置故障节点任务,重新分配相关worker重新执行一遍故障节点的任务。具体分配策略,根据ping反馈的节点负载情况调度。
Master故障
预防master故障,master需要周期性的写checkpoint,并且刷落磁盘。Master故障,可以从checkpoint恢复Job故障时的Job运行状态,继续执行任务。
确定性函数
Map和Reduce操作是确定性函数,重复执行,保障顺序,执行输出的结果总是一样的。
input(确定输入) -> Map(规则函数) -> Reduce(规则函数) -> output(必然确定输出)
数据本地性
Master在调度worker执行tasks时,会充分考虑数据本地性,尽量本地读取数据,本地计算,这样可以大大节省网络带宽,Master在调度任务时会传输相关文件位置信息给worker,即使本地性失败,也会选择就近的机架服务器执行计算。
任务粒度
MapReduce任务粒度:M=200000 ,R=5000, 使用2000台worker机器。
通常第一次批量加载数据进MapReduce程序,我们很难控制并行度,默认由文件个数决定。很多时候任务都是又多个MapReduce构成,所以Reduce常常是由用户自己控制,进而控制接下来Map的并行度。
备用任务
在一个大的Job中,有大量的任务,有些任务执行缓慢,我们称之为 落伍者 ,它会拖慢整体进度。
造成 落伍者 情况有很多,网络问题、硬件故障、系统负载、资源抢占。当大多数任务均执行完毕,通过Worker任务周期性汇报Master,获知 落伍者 执行的任务情况,这个时候master会启用备用任务,执行相同的task,通常比正常多消耗百分之几的资源,加速任务执行时间。
分区函数
[1] 控制Reduce任务 -> 控制任务输出文件数
[2] 缺省分区函数 -> hash(key) mod R
[3] hash是平衡分区比较合理的方式
[4] 用户自定义分区 -> 产生相同key数据输出到同一个文件的效果
分区中,中间key/value pari数据,保障key增量顺序处理。保障每个文件是有序的默认支持,对于基于key随机存取,排序数据友好,可加速处理。
combiner函数
特殊应用场景需要使用combiner处理,比如:单词记数程序,Map出现大量的重复记数据,而在Reduce阶段需要合并,如果在map -> reduce之间加一层combiner操作,无疑可加速reduce处理时间。
计数器
通过统计task时间发生的次数,master周期性ping worker,在反馈数据包中传输任务执行详细情况。帮助记录和监控各个节点任务执行阶段和评估预计执行时间,通过详细的统计信息,帮助优化MapReduce程序。比如:跳过损坏记录,可把跳过文件路径,文件名,跳过的文件行详细信息反馈到计数器页面,帮助开发人员,定位数据质量或程序错误。
小结
MR封装,为何能在数据分析领域大规模应用。
[1] 并行处理 [2] 负载均衡 [3] 容错处理 [4] 易于使用 [5] 数据本地化优化
除以上MapReduce优势,还得益于一个强大的分布式文件系统GFS,提供超强的高可扩展的文件管理。
我们也从 MapReduce 开发过程中学到了不少东西。首先,约束编程模式使得并行和分布式计算非常容易,也易于构造容错的计算环境;其次,网络带宽是稀有资源。大量的系统优化是针对减少网络传输量为目的的: 数据本地化优化策略使大量的数据从本地磁盘读取,中间文件写入本地磁盘、并且只写一份中间文件也节约了网络 带宽;第三,多次执行相同的任务可以减少性能缓慢的机器带来的负面影响(alex 注: 即硬件配置不平衡), 同时解决了由于机器失效导致的数据丢失问题。
推荐阅读:
[1] 分布式文件系统设计与实现
[2] MapReduce设计与实现
欢迎关注微信公众号[Whoami],阅读更多内容。

原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

