Java 集合系列3、骨骼惊奇之LinkedList
我们在前面的文章中已经介绍过 List 大家族中的ArrayList 和Vector 这两位犹如孪生兄弟一般,从底层实现,功能都有着相似之处,除了一些个人行为不同(成员变量,构造函数和方法线程安全)。接下来,我们将会认识一下他们的另一位功能强大的兄弟: LinkedList
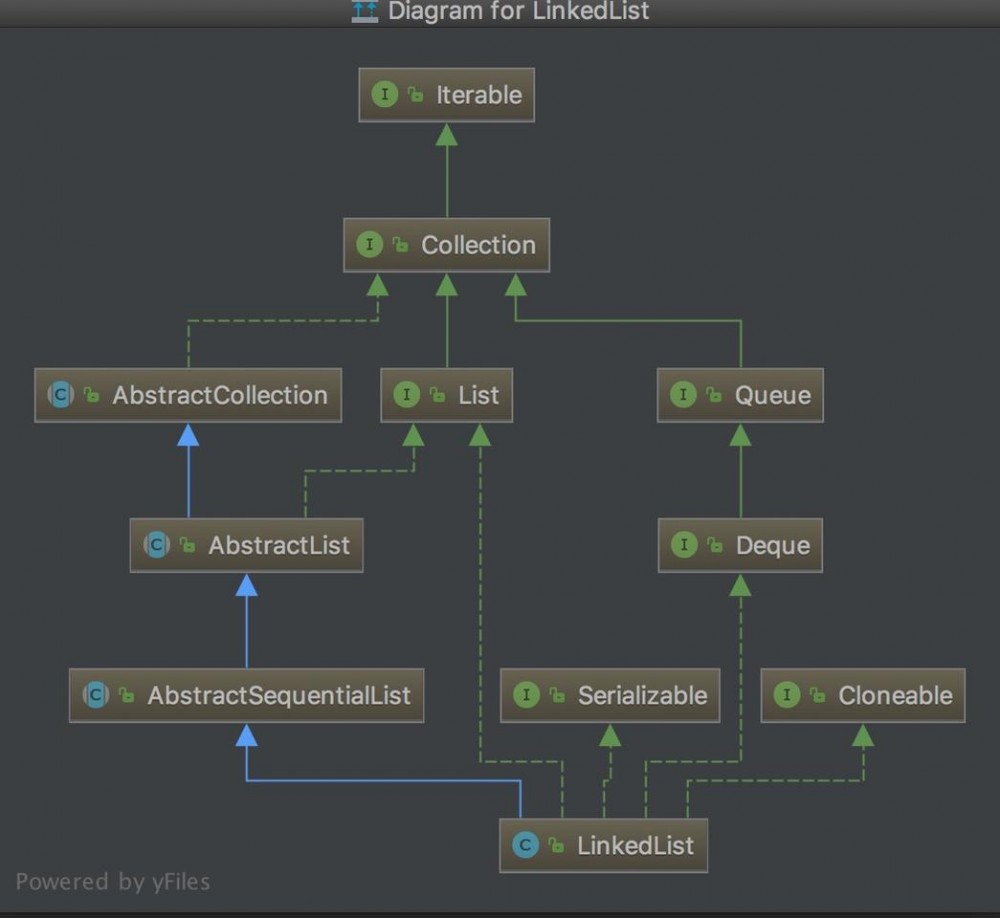
LinkedList 的依赖关系:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
- 1、继承于 AbstractSequentialList ,本质上面与继承 AbstractList 没有什么区别,AbstractSequentialList 完善了 AbstractList 中没有实现的方法。
- 2、Serializable:成员变量 Node 使用 transient 修饰,通过重写read/writeObject 方法实现序列化。
- 3、Cloneable:重写clone()方法,通过创建新的LinkedList 对象,遍历拷贝数据进行对象拷贝。
- 4、Deque:实现了Collection 大家庭中的队列接口,说明他拥有作为双端队列的功能。
eng~从上述实现接口来看,LinkedList 与 ArrayList 之间在整体上面的区别在于, LinkedList 实现了 Collection 大家庭中的Queue(Deque)接口,拥有作为双端队列的功能 。(就好比一个小孩子,他不仅仅有父母的特性,他们有些人还会有舅舅的一些特性,好比 外甥长得像舅舅一般)。
2、LinkedList 成员变量
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList 的成员变量主要由 size(数据量大小),first(头节点)和last(尾节点)。结合数据结构中双端链表的思想,每个节点需要拥有,保存数据(E item),指向下一节点(Node next )和指向上一节点(Node prev)。
LinkedList 与ArrayLit、Vector 的成员变量对比中,明显没有提供 MAX_ARRAY_SIZE 这一个最大值的限定,这是由于链表没有长度限制的原因,他的内存地址不需要分配固定长度进行存储,只需要记录下一个节点的存储地址即可完成整个链表的连续。
拓展思考: LinkedList 中 JDK 1.8 与JDK 1.6 有哪些不同?
主要不同为,LinkedList 在1.6 版本以及之前,只通过一个 header 头指针保存队列头和尾。这种操作可以说很有深度,但是从代码阅读性来说,却加深了阅读代码的难度。因此在后续的JDK 更新中,将头节点和尾节点 区分开了。节点类也更名为 Node。
3、LinkedList 构造函数
LinkedList 只提供了两个构造函数:
- LinkedList()
- LinkedList(Collection<? extends E> c)
在JDK1.8 中,LinkedList 的构造函数 LinkedList() 是一个空方法,并没有提供什么特殊操作。区别于 JDK1.6 中,会初始化 header 为一个空的指针对象。
3.1 LinkedList()
JDK 1.6
private transient Entry<E> header = new Entry<E>(null, null, null);
public LinkedList() {
header.next = header.previous = header;
}
JDK 1.8在使用的时候,才会创建第一个节点。
public LinkedList() {
}
3.2 LinkedList(Collection<? extends E> c)
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
这一构造方法主要通过 调用addAll 进行创建对象,在介绍LinkedList 添加方法的时候再进行细述。
3.3 小结
LinkedList 在新版本的实现中,除了区分了头节点和尾节点外,更加注重在使用时进行内存分配,这里跟ArrayList 类似(ArrayList 默认构造器是创建一个空的数组对象)。
4、添加方法(Add)
LinkedList 继承了 AbstractSequentialList(AbstractList),同时实现了Deque 接口,因此,他在添加方法 这一块,包含了两者的操作:
AbstractSequentialList:
- add(E e)
- add(int index,E e)
- addAll(Collection<? extends E> c)
- addAll(int index, Collection<? extends E> c)
Deque
- addFirst(E e)
- addLast(E e)
- offer(E e)
- offerFirst(E e)
- offerLast(E e)
4.1 add(E e) & addLast(E e) & offer(E e) & offerLast(E e)
虽然 LinkedList 分别实现了List 和 Deque 的添加方法,但是在某种意义上,这些方法其实都是有共性的。例如,我们调用add(E e) 方法,不管是ArrayList 或 Vector 等列表,都是默认在数组末尾进行添加,因此与 队列中在末尾添加节点 addLast(E e) 是有着一样的韵味的。所以,从LinkedList 的源码中,这几个方法,底层操作其实是一致的。
public boolean add(E e) {
linkLast(e);
return true;
}
public void addLast(E e) {
linkLast(e);
}
public boolean offer(E e) {
return add(e);
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
我们主要分析一下 linkLast 这个方法:
- 获取尾节点(last)
- 创建插入节点,并且设置上一节点为 last,下一节点为 null。
- 设置新节点为末尾节点(last)
- 如果 l(初始末尾节点)==null,说明这是第一次操作,新加入的为头节点
- 否则,设置 l(初始末尾节点)的下一节点为新加入的节点
- size + 1,操作计数 + 1
拓展思考:为什么内部变量 Node l 需要使用 final 进行修饰?
4.2 addFirst(E e) & offerFirst(E e)
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
从上述代码可以看出,offerFirst 和addFirst 其实都是一样的操作,只是返回的数据类型不同。而 linkFirst 方法,则与 linkLast 其实是一样的思想,这里也不做细述。
4.3 add(int index,E e)
这里我们主要讲一下,为什么LinkedList 在添加、删除元素这一方面优于 ArrayList。
public void add(int index, E element) {
checkPositionIndex(index);
// 如果插入节点为末尾,直接插入
if (index == size)
linkLast(element);
// 否则,找到该节点,进行插入
else
linkBefore(element, node(index));
}
Node<E> node(int index) {
// 这里顺序查找元素,通过二分查找的方式,决定从头或尾节点开始进行查找,时间复杂度为 n/2
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
LinkedList 在 add(int index,Element e)方法的流程
- 判断下标有效性
- 如果插入位置为末尾,直接插入
- 否则,遍历1/2的链表找到 index 下标的节点
- 通过 succ 设置新节点的前,后节点
LinkedList 在插入数据之所以会优于ArrayList,主要是由于在插入数据这一环节(linkBefore),插入计算只需要设置节点的前,后节点即可,而ArrayList 则需要将整个数组的数据进行后移(
System.arraycopy(elementData, index, elementData, index + 1,size - index);
)
4.4 addAll(Collection<? extends E> c)
LinkedList 中提供的两个addAll 方法中,其实内部实现也是一样的,主要通过: addAll(int index, Collection<? extends E> c)进行实现:
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
//将集合转化为数组
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
//获取插入节点的前节点(prev)和尾节点(next)
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
//将集合中的数据编织成链表
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
//将 Collection 的链表插入 LinkedList 中。
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
4.5 小结
LinkedList 在插入数据优于ArrayList ,主要是因为他只需要修改指针的指向即可,而不需要将整个数组的数据进行转移。而LinkedList 优于没有实现 RandomAccess,或者说 不支持索引搜索的原因,他在查找元素这一操作,需要消耗比较多的时间进行操作(n/2)。
5、删除方法(Remove)
AbstractSequentialList:
- remove(int index)
- remove(Object o)
Deque
- remove()
- removeFirst()
- removeLast()
- removeFirstOccurrence(Object o)
- removeLastOccurrence(Object o)
5.1 remove(int index)&remove(Object o)
在 ArrayList 中,remove(Object o) 方法,是通过遍历数组,找到下标后,通过fastRemove(与 remove(int i) 类似的操作)进行删除。而LinkedList,则是遍历链表,找到目标节点(node),通过 unlink 进行删除: 我们这里主要来看看 unlink 方法:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
整个过程为:
- 获取目标节点的 next、prev
- 如果prev 为空,说明目标节点为头节点
- 设置first 为目标节点的下一节点(next)
- 否则设置prev节点的下一节点为next(即将自己重链表中剔除)
- 如果 next 为空,说明目标节点为尾节点
- 设置last 为目标节点的上一节点
- 否则,设置next节点的上一节点为prev
- 将目标节点设置为null
可以看到,删除方法与添加方法类似,只需要修改节点关系即可,避免了类似于ArrayList 的数组平移情况,大大减少了时间损耗。
5.2 Deque 中的Remove
Deque 中的 removeFirstOccurrence 和 removeLastOccurrence 主要过程为,首先从first/last 节点开始遍历,当发现第一个目标对象,则低哦啊用remove(Object o) 进行删除对象。总体上没有什么特别之处。
稍有不同的是Deque 中的removeFirst()和removeLast()方法,在底层实现上面,由于明确知道删除的对象为first/last对象,因此在删除操作上面 会更加简单:
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
整体操作为,将first 节点的next 设置为新的头节点,然后将 f 清空。 removeLast 操作也类似。
结合队列的思想,removeFirst 和removeLast 都会返回 数据 E,相当于我们的出列操作( pollFirst / pollLast )
6 LinkedList 双端链表
我们之所以说LinkedList 为双端链表,是因为他实现了Deque 接口,支持队列的一些操作,我们来看一下有哪些方法实现:
- pop()
- poll()
- push()
- peek()
- offer()
可以看到Deque 中提供的方法主要有上述的几个方法,接下来我们来看看在LinkedList 中是如何实现这些方法的。
6.1 pop() & poll()
LinkedList#pop的源码:
public E pop() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
从上述代码可以看出,Pop() 的操作为,队列头部元素出队列,如果过first 为空 会抛出异常。
LinkedList#poll的源码:
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
对比 pop 和poll 的源码可以看到,虽然同样是 first 出列,不同的是,如果first 为null, pop()方法会抛出异常 。
6.2 push()
push() 方法的底层实现,其实就是调用了 addFirst(Object o):
public void push(E e) {
addFirst(e);
}
push()方法的操作,主要跟 栈(Stack) 中的入栈操作类似。
6.3 peek()
LinkedList#peek 操作主要为,将取队列头部元素的值(根据队列的 FIFO,peek为取头部数据)
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
6.3 offer()
offer()方法为直接调用添加方法。
public boolean offer(E e) {
return add(e);
}
7 LinkedList 遍历
LinkedList 由于没有实现 RandomAccess,因此,在以随机访问的形式进行遍历时效果会非常低下。除此之外,LinkedList 提供了类似于通过Iterator 进行遍历,节点的prev 或 next 进行遍历,还有for循环遍历,都有不错的效果。
8 总结
没有太多的拓展思考,脑子不够清晰,总体来说,List 接口下面的小家庭的源码以及分析完了。对每一个成员都有了进一步的了解,面试的时候,也不会再简单的回答,linkedList 插入删除性能比较好,ArrayList 能过快速定位元素,Vector 是线程安全。只有在充分了解其实现,你才会发现,你回答的虽然没错,但是也就60分而已,如果你想要将每一个问题回答的完美,那么请认真思考,认真去了解它。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

