读源码:深入研究 Java CAS 实现
本篇博客基于 OpenJdk8 简单的一条线的看看 CAS 的实现过程。
如果你也想方便在 IDE 中查看 OpenJdk 的代码,你可以看看这篇 在 NetBeans 中编译调试 OpenJdk 。
本文会涉及 Java 代码, C++ 代码和汇编代码。
一、Java 层
随便找个会调用到 CAS 的方法,例如 AtomicInteger 中有一个原子方式 i++ 操作,代码如下:
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
在 unsafe 中, getAndAddInt 如下:
/**
* Atomically adds the given value to the current value of a field
* or array element within the given object <code>o</code>
* at the given <code>offset</code>.
*
* @param o object/array to update the field/element in
* @param offset field/element offset
* @param delta the value to add
* @return the previous value
* @since 1.8
*/
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
在这里我们就看到了 CAS 的一种方式 compareAndSwapInt , CAS 的意思就是比较并交换。
在往下深入前,先了解一下这里的参数。 incrementAndGet 调用方法中有一个 valueOffset 参数,这个参数值在 AtomicInteger 中静态初始化的,这个值是 value 值在 AtomicInteger 类型中内存的偏移地址。传入的 valueOffset 参数会在后续方法中,直接从内存位置读取这个字段的值。所有 CAS 的地方,都使用的这种方式。另外两个参数很简单,不多说。
本文目的是 CAS,所以其他无关的内容,例如如何获取偏移地址都不在本文介绍之内,看懂本文后,你自己也能分析这个方法。
在 getAndAddInt 方法中,会先使用 getIntVolatile 读取 Object 对应偏移 offset 中的值,从 Volatile 可以看出来(底层实现就是),这个值肯定是内存中实时的最新值。
得到最新值后,调用 compareAndSwapInt 来更新最新值,方法代码如下:
/**
* Atomically update Java variable to <tt>x</tt> if it is currently
* holding <tt>expected</tt>.
* @return <tt>true</tt> if successful
*/
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
如果对象 o 中 offset 偏移位置的值等于期望值( expected ),就将该 offset 处的值更新为 x ,当更新成功时,返回 true 。结合前面调用来看,如果当前值是 v ,就设置为 v+1 。
不仅仅是 AtomicInteger 用到了 CAS,整个 java.util.concurrent 中所有无阻塞共享内存和锁的实现都是基于 CAS 实现的。
可以先略过这段内容:对锁来说,那就是期望是没有其他线程占有该锁,如果没占有,就设置自己占有该锁,当占有成功时,返回值 true ,此时其他线程就不能再获取这个锁,但是他们会一直调用 CAS 尝试占有,这情况下所有线程在自己的CPU时间片执行,不需要线程切换。
再往下,就需要看 unsafe.cpp 中的方法实现了。
二、C++
unsafe.cpp 中的该方法如下:
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(
JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
为了方便以后阅读方便,这里对这段代码进行详细的展开。实际阅读时,并不需要这么做。
1. 展开 UNSAFE_ENTRY
UNSAFE_ENTRY 是一个宏定义,代码如下:
#define UNSAFE_ENTRY(result_type, header) / JVM_ENTRY(result_type, header)
这段代码又引用了另一个 JVM_ENTRY ,这里这么设计就是为了方便区分 UNSAFE_ENTRY 方法,通过这个名字就知道这段属于 UNSAFE 。
2. 继续展开 JVM_ENTRY
宏定义代码如下:
#define JVM_ENTRY(result_type, header) /
extern "C" { /
result_type JNICALL header { /
JavaThread* thread=JavaThread::thread_from_jni_environment(env); /
ThreadInVMfromNative __tiv(thread); /
debug_only(VMNativeEntryWrapper __vew;) /
VM_ENTRY_BASE(result_type, header, thread)
extern "C" 就是下面代码以 C 语言方式进行编译,C++可以嵌套 C 代码,后面还会嵌套汇编。
源码中特别常见的 JNICALL 就是一个空的宏定义,只是为了告诉人这是一个 JNI 调用,宏定义如下:
#define JNICALL
3. 继续展开 VM_ENTRY_BASE
定义如下:
#define VM_ENTRY_BASE(result_type, header, thread) / TRACE_CALL(result_type, header) / HandleMarkCleaner __hm(thread); / Thread* THREAD = thread; / os::verify_stack_alignment(); / /* begin of body */
这里的 TRACE_CALL 定义如下:
#ifdef ASSERT
class RuntimeHistogramElement : public HistogramElement {
public:
RuntimeHistogramElement(const char* name);
};
#define TRACE_CALL(result_type, header) /
InterfaceSupport::_number_of_calls++; /
if (TraceRuntimeCalls) /
InterfaceSupport::trace(#result_type, #header); /
if (CountRuntimeCalls) { /
static RuntimeHistogramElement* e = new RuntimeHistogramElement(#header); /
if (e != NULL) e->increment_count(); /
}
#else
#define TRACE_CALL(result_type, header) /
/* do nothing */
#endif
存在 ASSERT 时才会有代码,这里考虑 #else ,直接当空处理。
THREAD 宏定义如下:
#define THREAD __the_thread__
4. 展开后
经过层层展开,最后还有 UnsafeWrapper 是个空, UNSAFE_END 是两个结束的大括号 } } 。
经过手工格式化的代码如下:
"C" {
jboolean Unsafe_CompareAndSwapInt (
JNIEnv * env , jobject unsafe ,
jobject obj , jlong offset , jint e , jint x ) {
JavaThread* thread=JavaThread::thread_from_jni_environment(env);
ThreadInVMfromNative __tiv(thread);
HandleMarkCleaner __hm( thread );
Thread* __the_thread__ = thread ;
os::verify_stack_alignment();
;
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
}
}
如果你使用 NetBeas 查看展开前的方法,你能直接看到 NetBeans 帮你展开后的代码,如下图所示:
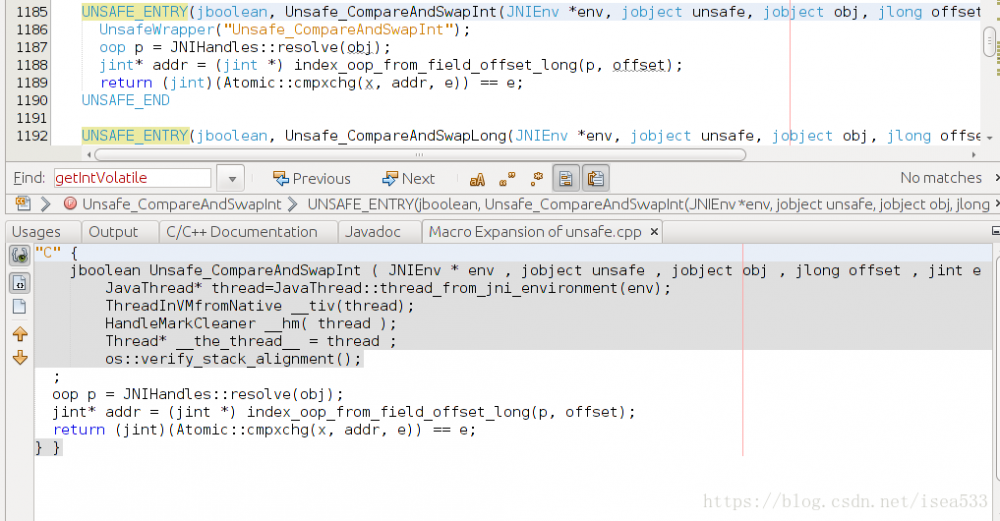
5. 关键代码
即使不懂 C++ 也能看出来,在这个方法中,展开的那部分代码对原来的代码没影响,真正执行的下面这 3 行代码:
oop p = JNIHandles::resolve(obj); jint* addr = (jint *) index_oop_from_field_offset_long(p, offset); return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
下面就分析这 3 行代码。
JNIHandles::resolve 方法代码如下:
inline oop JNIHandles::resolve(jobject handle) {
oop result = (handle == NULL ? (oop)NULL : *(oop*)handle);
assert(result != NULL ||
(handle == NULL || !CheckJNICalls || is_weak_global_handle(handle)),
"Invalid value read from jni handle");
assert(result != badJNIHandle, "Pointing to zapped jni handle area");
return result;
};
*(oop*)handle 分解开就是 (oop*)handle 转换为 oop 类型的指针,最后 *指针 就是取该指针的值。
index_oop_from_field_offset_long 方法就是用 p 的地址加上 offset 得到这个值的具体内存地址。
最后执行 Atomic::cmpxchg(x, addr, e) 方法,并用返回值和 e 进行比较。如果返回值和期望值相同就会返回 true 。
继续看 Atomic::cmpxchg 方法。
三、内联汇编
Atomic::cmpxchg 方法代码如下:
inline jint Atomic::cmpxchg(
jint exchange_value,
volatile jint* dest,
jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
这里也有判断当前是否多处理器的配置宏 LOCK_IF_MP ,代码如下:
// Adding a lock prefix to an instruction on MP machine #define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
宏展开并且格式化后的代码如下:
inline jint Atomic::cmpxchg(
jint exchange_value,
volatile jint* dest,
jint compare_value) {
int mp = os::is_MP();
__asm__ volatile ("cmp $0, " "%4" "; je 1f; lock; 1: " "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
这里首先会获取当前系统的核心数, 如果只有一个核心,就不存在多个CPU核心读写内存的问题,如果是多个核心,就需要通过加锁保证 cmpxchgl 是一个原子操作(读写安全)。
汇编代码中用到了 %n 形式的占位符,这里简单说一下语法,如果想要自己完全理解,建议看看 Linux 汇编语言开发指南 或 C语言ASM汇编内嵌语法zz 。
完整的内联汇编参数如下:
__asm__ volatile("asm statements" : outputs : inputs : registers-modified);
下面挨个介绍这 4 个参数。
1. "asm statements" 汇编代码
和前面代码对照看, "asm statements" 对应的汇编代码模板部分,格式化后如下:
cmp $0, %4;
je 1f;
lock;
1: cmpxchgl %1,(%3)
代码中可以通过索引使用后续参数,后面有详细说明。
2. outputs 输出
outputs 是执行汇编代码 后 的输出部分,用于获取执行结果,这里对应的是:
"=a" (exchange_value)
"=a" 有两个意思, = 说明后面的参数是 只写 的, a 说明用的是 eax 寄存器。
(exchange_value) 指定的 C++ 代码中的变量名。
上面这行代码翻译成汇编代码后形式(不是实际的)如下:
movl %eax exchange_value内存数据
这儿只是为了简单说明问题,真正编译时是知道 exchange_value 地址的。
3. inputs 输入
inputs 是执行汇编代码 前 执行输入部分,也就是给寄存器或者内存赋初始值。这里对应下面的代码:
"r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
"r" 的意思是说用 任何一个寄存器 存后面指定的变量值。
"a" 和前面一样,就是用 eax 寄存器存 compare_value 的值。
这部分代码翻译为汇编代码时形式(不是实际的)如下:
movl exchange_value edx #gcc选择的寄存器 movl compare_value eax #通过a指定的寄存器 movl dest xxx #gcc选择的寄存器 movl mp xxx #gcc选择的寄存器
4. registers-modified 副作用标记
registers-modified 用于说明汇编代码执行后对寄存器内存等存储的影响。这里对应的代码如下:
"cc", "memory"
cc 的意思是说标志位发生了变化,后面会涉及 ZF 标志位的变化。
memory 意思是说内存数据发生了变化。
在这里增加的所有标记都会影响 gcc 的编译。
5. 汇编代码中的索引
内联汇编最多允许的出参和入参总和为 10 个,参数的序号是按出参到入参的顺序排,从 0 开始。
在上面的例子中,参数的序号对应关系如下:
| 序号 | 参数 |
|---|---|
| 0 | "=a" (exchange_value) |
| 1 | "r" (exchange_value) |
| 2 | "a" (compare_value) |
| 3 | "r" (dest) |
| 4 | "r" (mp) |
四、CPU 指令
了解内联汇编的基本语法后,我们将前面的汇编最终替换如下:
movl %eax;
cmp $0, mp;
je 1f;
lock;
1: cmpxchgl exchange_value,(dest)
$0 是 AT&T 汇编中的立即数形式,首先比较核心数是否为 0(核心数默认0,系统初始化时会设置核心数,不清楚什么时候会出现 0 的情况,现在系统都多核,忽略这个问题)。如果是 0 会跳转到 1: 处执行,也就是跳过了 lock 指令。
lock 指令说明: https://www.felixcloutier.com/x86/LOCK.html
lock 指令可以保证在多处理器环境中,LOCK#信号确保处理器在信号有效时独占使用共享内存。配合 lock 可以使得 cmpxchgl 指令成为一个原子操作。
cmpxchgl 指令说明: https://www.felixcloutier.com/x86/CMPXCHG.html
注意:AT&T 和 intel 汇编指令中,源操作数和目的操作数位置是颠倒的。
在上面代码中,cmpxchgl 需要用到 3 个参数,分别是 eax 寄存器和指令后的两个参数。
在前面讲 input 参数的时候,说过 "a" (compare_value) 对应的指令就在上面汇编代码执行前,给 eax 寄存器赋值,代码如下:
movl compare_value %eax
所以,cmpxchgl 在这里用的参数分别如下:
| 参数 | 说明 |
|---|---|
compare_value |
存在 eax 寄存器中的预期值 |
exchange_value |
源操作数 |
(dest) |
目的操作数,带上括号是取内存值 |
cmpxchgl 指令就是比较 eax 寄存器的值( compare_value 预期值)和 目的操作数( (dest) )的值是否相同。
这里就相当于比较预期值和 AtomicInteger 中的 value 值。
- 如果 相同 ,就把源操作数(
exchange_value)的值赋值给目的操作数((dest)),并且设置标志位ZF=1(影响的cc)。这种情况下,就成功的修改了内存中的数据,后续的操作成功就是指的这种情况。 - 如果 不同 ,就把源操作数(
exchange_value)的值赋值给 eax 寄存器,并且设置ZF=0。
执行完这个汇编指令后,下一步就处理 output 操作数,前面代码写的是 "=a" (exchange_value) ,也就是将 eax 寄存器的值赋值给 exchange_value 。这里分别针对上面 相同 和 不同 进行说明。
- 相同 ,此时 eax 的值还是 input 中设置的 compare_value 预期值,所以 exchange_value=compare_value 交换值等于预期值了。
- 不同 ,此时 eax 的值被设置为 exchange_value ,所以 exchange_value=exchange_value ,值不变。
在 Atomic::cmpxchg 方法最后会返回 exchange_value 。
在 unsafe 的方法中,有如下判断:
(jint)(Atomic::cmpxchg(x, addr, e)) == e
- 相同 的时候,返回值是预期值,因此这里最后就是
e == e,在 Java 中就是true。 - 不同 的时候,返回值是
x,因为x != e,所以最后就是false。
内联汇编示例
为了更容易理解前面对参数讲解,这里列举一个简单的例子,通过对比可以更好的理解。
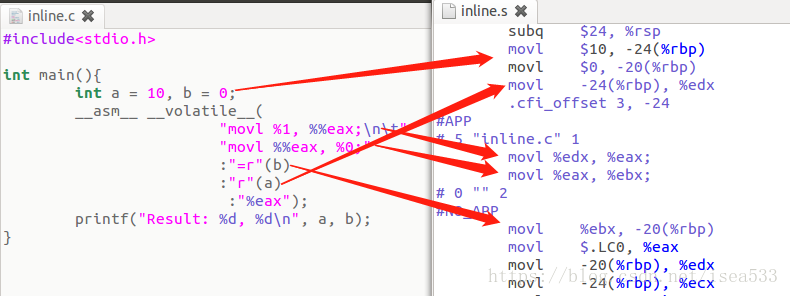
最后
看到这里的时候希望你是清楚的,如果觉得本文有问题,欢迎指出,欢迎交流。
如果你还是没看明白,如果你有兴趣想要继续了解,可以先参考 在 NetBeans 中编译调试 OpenJdk 这篇配置好环境,然后自己在代码中和这篇博客对照阅读,文中出现的其他链接也都建议阅读。
本文的目的不仅仅是在看 CAS 在底层如何实现,更主要的目的还是在于如何一步步去阅读你感兴趣的源码。
如果你通过微信读到这篇文章,你可以点击【阅读原文】来点开文中的其他链接。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

