Map大家族的那点事儿(4) :HashMap – 为什么是hash?
HashMap
光从名字上应该也能猜到,HashMap肯定是基于hash算法实现的,这种基于hash实现的map叫做散列表(hash table)。
散列表中维护了一个数组,数组的每一个元素被称为一个桶(bucket),当你传入一个 key = "a" 进行查询时,散列表会先把key传入散列(hash)函数中进行寻址,得到的结果就是数组的下标,然后再通过这个下标访问数组即可得到相关联的值。
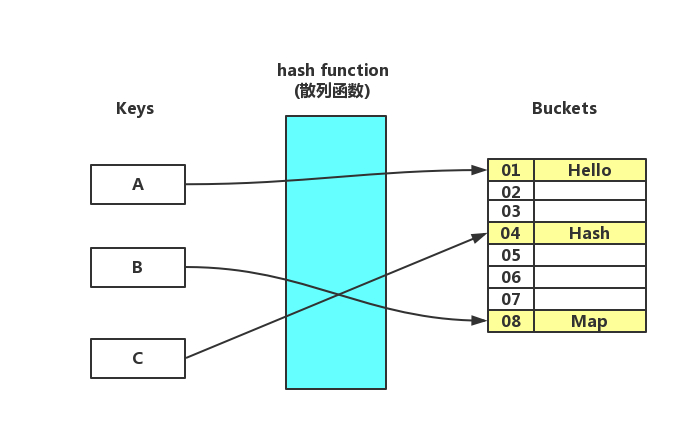
我们都知道数组中数据的组织方式是线性的,它会直接分配一串连续的内存地址序列,要找到一个元素只需要根据下标来计算地址的偏移量即可(查找一个元素的起始地址为:数组的起始地址加上下标乘以该元素类型占用的地址大小)。因此散列表在理想的情况下,各种操作的时间复杂度只有 O(1) ,这甚至超过了二叉查找树,虽然理想的情况并不总是满足的,关于这点之后我们还会提及。
为什么是hash?
hash算法是一种可以从任何数据中提取出其“指纹”的数据摘要算法,它将任意大小的数据(输入)映射到一个固定大小的序列(输出)上,这个序列被称为hash code、数据摘要或者指纹。比较出名的hash算法有MD5、SHA。
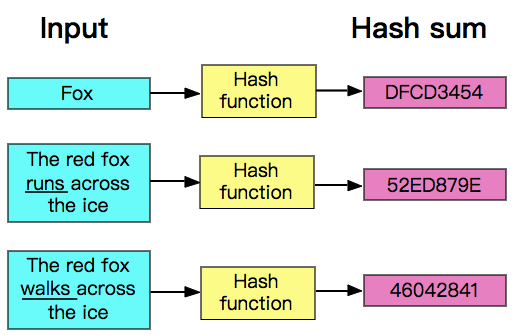
hash是具有唯一性且不可逆的,唯一性指的是相同的输入产生的hash code永远是一样的,而不可逆也比较容易理解,数据摘要算法并不是压缩算法,它只是生成了一个该数据的摘要,没有将数据进行压缩。压缩算法一般都是使用一种更节省空间的编码规则将数据重新编码,解压缩只需要按着编码规则解码就是了,试想一下,一个几百MB甚至几GB的数据生成的hash code都只是一个拥有固定长度的序列,如果再能逆向解压缩,那么其他压缩算法该情何以堪?
我们上述讨论的仅仅是在密码学中的hash算法,而在散列表中所需要的散列函数是要能够将key寻址到buckets中的一个位置,散列函数的实现影响到整个散列表的性能。
一个完美的散列函数要能够做到均匀地将key分布到buckets中,每一个key分配到一个bucket,但这是不可能的。虽然hash算法具有唯一性,但同时它还具有重复性,唯一性保证了相同输入的输出是一致的,却没有保证不同输入的输出是不一致的,也就是说,完全有可能两个不同的key被分配到了同一个bucket(因为它们的hash code可能是相同的),这叫做碰撞冲突。总之,理想很丰满,现实很骨感,散列函数只能尽可能地减少冲突,没有办法完全消除冲突。
散列函数的实现方法非常多,一个优秀的散列函数要看它能不能将key分布均匀。首先介绍一种最简单的方法:除留余数法,先对key进行hash得到它的hash code,然后再用该hash code对buckets数组的元素数量取余,得到的结果就是bucket的下标,这种方法简单高效,也可以当做对集群进行负载均衡的路由算法。
private int hash(Key key) {
// & 0x7fffffff 是为了屏蔽符号位,M为bucket数组的长度
return (key.hashCode() & 0x7fffffff) % M;
}
要注意一点,只有整数才能进行取余运算,如果hash code是一个字符串或别的类型,那么你需要将它转换为整数才能使用除留余数法,不过Java在Object对象中提供了 hashCode() 函数,该函数返回了一个int值,所以任何你想要放入HashMap的自定义的抽象数据类型,都必须实现该函数和 equals() 函数,这两个函数之间也遵守着一种约定:如果 a.equals(b) == true ,那么a与b的 hashCode() 也必须是相同的。
下面为String类的 hashCode() 函数,它先遍历了内部的字符数组,然后在每一次循环中计算hash code(将hash code乘以一个素数并加上当前循环项的字符):
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
HashMap没有采用这么简单的方法,有一个原因是HashMap中的buckets数组的长度永远为一个2的幂,而不是一个素数,如果长度为素数,那么可能会更适合简单暴力的除留余数法(当然除留余数法虽然简单却并不是那么高效的),顺便一提,时代的眼泪Hashtable就使用了除留余数法,它没有强制约束buckets数组的长度。
HashMap在内部实现了一个 hash() 函数,首先要对 hashCode() 的返回值进行处理:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
该函数将 key.hashCode() 的低16位和高16位做了个异或运算,其目的是为了扰乱低位的信息以实现减少碰撞冲突。之后还需要把 hash() 的返回值与 table.length - 1 做与运算( table 为buckets数组),得到的结果即是数组的下标。
table.length - 1 就像是一个低位掩码(这个设计也优化了扩容操作的性能),它和 hash() 做与操作时必然会将高位屏蔽(因为一个HashMap不可能有特别大的buckets数组,至少在不断自动扩容之前是不可能的,所以 table.length - 1 的大部分高位都为0),只保留低位,看似没什么毛病,但这其实暗藏玄机,它会导致总是只有最低的几位是有效的,这样就算你的 hashCode() 实现得再好也难以避免发生碰撞。这时, hash() 函数的价值就体现出来了,它对hash code的低位添加了随机性并且混合了高位的部分特征,显著减少了碰撞冲突的发生(关于 hash() 函数的效果如何,可以参考这篇文章 An introduction to optimising a hashing strategy )。
HashMap的散列函数具体流程如下图:

正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

