将Java 应用容器化改造并迁移到Kubernetes 平台

为了能够适应容器云平台的管理模式和管理理念,应用系统需要完成容器化的改造过程。对于新开发的应用,建议直接基于微服务架构进行容器化的应用开发;对于已经运行多年的传统应用系统,也应该逐步将其改造成能够部署到容器云平台上的容器化应用。本文针对传统的Java 应用,对如何将应用进行容器化改造和迁移到Kubernetes 平台上进行说明。
要将传统Java 应用改造迁移到Kubernetes 平台上运行,通常要经过以下几个步骤。
(1)进行应用代码改造,要考虑配置文件、多实例部署下的分布式架构问题,并对程序代码和架构做出相应的改造。
(2)进行容器化改造,选择合适的基础镜像并打包生成新的应用镜像,使得应用能以容器方式部署、运行。
(3)进行Kubernetes 建模与部署,采用合适的Kubernetes 资源对象建模Java 应用,最终发布到Kubernetes 平台上实现应用的自动化运维。
接下来以一个传统的Java 应用改造迁移过程为例,来说明上述步骤中的细节。
1 Java 应用的容器化改造迁移
我们的目标是搭建一个简单的学员分数管理系统(Study Application),应用界面与架构如下图。
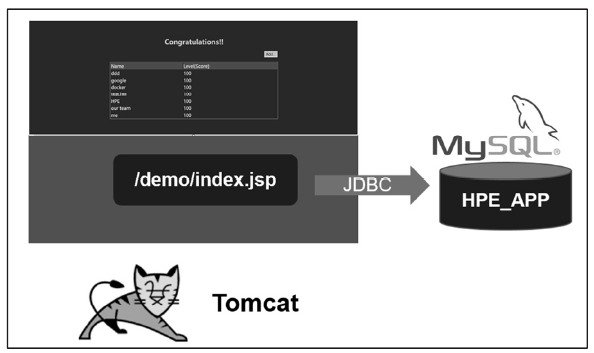
Study Application 是一个典型的J2EE 系统,为了方便理解,并没有采用额外的框架技术,而是采用了MySQL 数据库,将JSP 作为Web 页面,并通过JDBC 进行数据库操作,整个系统以标准方式部署在Tomcat 的webapp 目录下。
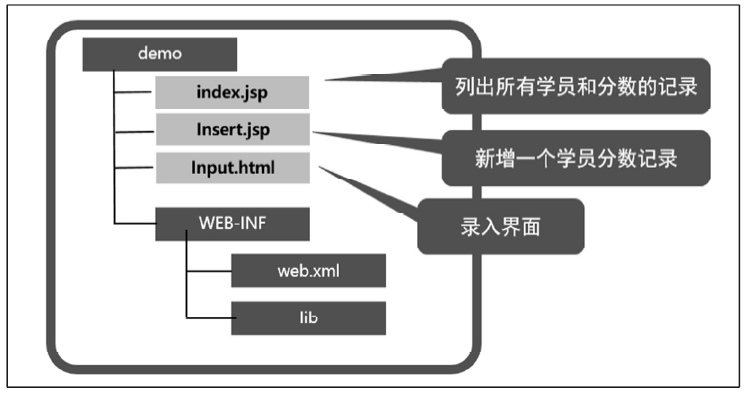
下图所示是Study Application的目录结构与说明。
下面是在index.jsp 中访问数据库的关键代码, 数据库连接的配置信息被放在jdbc.properties 属性文件中,便于在不同的环境下修改:

Class.forName("com.mysql.jdbc.Driver");
java.util.Properties pps = new java.util.Properties();
pps.load(new java.io.FileInputStream("jdbc.properties"));
String ip=pps.getProperty("mysql_ip");
String user=pps.getProperty("user");
String password=pps.getProperty("password");
System.out.println("Connecting to database...");
conn =
java.sql.DriverManager.getConnection("jdbc:mysql://"+ip+":3306"+"?useUnicode=tru
e&characterEncoding=UTF-8", user,password)
stmt = conn.createStatement();
String sql = "show databases like 'HPE_APP'";
rs =stmt.executeQuery(sql);
我们知道,应用在以容器化运行以后,是不建议进入容器里修改配置文件的(在多实例情况下很难保持配置文件同步更新),因此,需要修改从jdbc.properties 属性文件中获取数据库连接的以上代码,根据容器环境的要求,将其改为从环境变量中获取,改造后的代码如下:

String ip=System.getenv("mysql_ip");
String user=System.getenv("user");
String password=System.getenv("password");
改造后的代码基本达到了容器化的要求,但对于一个完整的应用来说,由于还存在用户Session 会话保持的问题,因此还需要实现分布式的Session 会话机制,才能做到多实例部署,此时可以考虑采用Spring Session 框架来改造、升级我们的单体应用。对于大部分RESTful 服务,由于不需要会话保持功能,因此可以直接多副本部署,多个实例可以同时提供服务。
2 Java 应用的容器镜像构建
接下来,我们需要将自己的Java 应用打包为Docker 镜像,以容器方式启动并提供服务。在打包镜像时,需要注意以下几个关键问题。
(1)需要注意基础镜像的选择问题。选择基础镜像的两个原则:标准化与精简化。尽可能选择Docker 官方发布的基础镜像,这些基础镜像通常符合标准化与精简化这两个目标。比如,它们都有Dockerfile 源文件,我们可以获知此镜像是如何制作的,并可以在此基础上实现诸如软件版本、性能优化、日志及安全等方面的特殊定制,然后打包为公司级别的内部标准镜像,供各个项目使用。
(2)需要注意业务进程的启动方式。与在物理机上将自己的程序放到后台运行的方式不同,在容器化时,我们需要将自己的业务进程放到前台运行。这样一来,当业务进程由于某种原因而停止时,容器也随之销毁,我们就能及时观察到这种严重故障,并做出相应的行动来恢复系统。目前有一些系统在容器化的过程中采用了supervisord 这样的工具,将业务的主进程和辅助进程放到后台启动,并交给supervisord 监管,这种做法虽然在一定程度上也能实现自动重启故障进程的目标,但它将问题隐藏得更深,即使业务进程由于特殊故障始终无法重启成功,运维人员也发现不了问题,因此不建议采用这种方式启动业务进程。
(3)需要注意程序的日志输出问题。在物理机上运行业务进程时,我们通常会把程序日志输出到指定的文件中,以便更好地排查故障。但在容器化以后,我们需要改变这种做法,将程序的日志直接输出在容器的屏幕上(或者说控制台Console 上),此时Docker 会将这些输出日志存放到容器之外的特定文件中,第三方的日志收集工具(例如Elasticsearch)就可以方便采集这些日志并实现集中化的日志搜索和分析功能。此外,Docker 也提供了统一的log 命令来查看容器的日志,这推进了系统运维的标准化。Java 中常用的Log4j 及Slf4j日志框架都支持把日志输出到控制台的配置方式,在打包应用时,需要对日志的配置文件做出相应的修改。
(4)需要注意文件操作的问题。当业务进程运行在物理机上时,它看到的文件系统就是物理机的文件系统;但当业务进程运行在容器中时,它所访问的文件系统就是一种特殊的、被隔离的、分层模式的虚拟文件系统,在这种情况下,频繁进行I/O 操作的性能比较低。为了解决这个问题,容器可以使用Volume 将频繁进行操作的目录映射到容器外部(通常是物理机上);同时,Volume 也是容器与外部交换文件的重要工具,因此在制作镜像和运行容器时,需要考虑Volume 映射的问题,对于在程序运行过程中产生的大量临时文件和被频繁读写的文件,或者在需要跟外界交换文件时,可以选择挂载Volume。
下图是Study Application 打包镜像的示意图及对应的Dockerfile 源码。
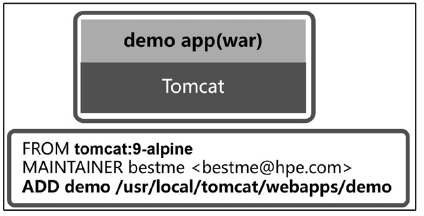
Study Application 的镜像继承了tomcat:9-alpine 这个官方的基础镜像,这个镜像基于Alpine Linux,如果对比一下,我们会发现,基于alpine 的镜像不到5MB,而基于Ubuntu或CentOS 的镜像都在100MB 以上。此外,从Study Application 的Dockerfile 来看,制作Java 类型应用的Docker 镜像是很方便的一件事,通常只需几行代码。
3 在Kubernetes 上建模与部署
在应用容器化后,就可以在Kubernetes 上建模与部署了,在建模的过程中,我们需要考虑一些关键问题,这些问题及其答案如下。
(1)将业务进程建模为Pod 还是RC?
对于这个问题,最重要的判断依据是该进程提供的是有状态服务还是无状态服务。对于无状态服务,比如大多数REST 接口的服务,通常是可以在任意节点上启动并提供服务的,例如我们这里的Web 应用程序就符合无状态服务。但对于有状态服务,比如MySQL服务,我们通常不能这么做,因为它依赖本地存储的数据库文件。对于有状态服务,我们通常只能将业务进程建模为Pod,这是因为RC 控制的Pod 实例可以从一台节点飘到另一台节点上,如果我们能够通过共享存储解决Pod 的状态问题,则也可以把某些有状态服务的进程建模为RC,这种做法与StatefulSet 很类似。
(2)我们是否需要在Pod 的基础上,继续建模对应的Service?
这主要取决于此Pod 是否会被其他业务进程(或终端用户)所访问,对于不会被其他业务进程所访问的Pod,我们无须建模对应的Service。实际上,在一个分布式系统中,大多数进程都会被建模为Service 并对应一个微服务,如果某个服务还需要被终端用户访问,则往往还需要“导出”外网访问地址,比如NodePort 端口。对于无须外部访问的Service,还可以考虑建模为Headless Service,在这种情况下,该Service 不会分配一个虚拟的ClusterIP,通信效率更高。
(3)是否需要考虑应用的数据存储问题?
如果只是本机存储,则可以直接使用Kubernetes Volume 资源对象;如果希望有远程存储功能,则可以考虑使用PV(Persistent Volume)。这样一来,不管Pod 被调度到哪台机器,都可以继续访问原来的存储数据。如果希望系统自动管理共享存储的空间,则可以考虑建模对应的StorageClass。
(4)是否需要考虑应用的配置问题?
我们知道,在几乎所有应用开发中,都会涉及配置文件的管理问题,比如StudyApplication 中的数据库配置信息,常见的互联网应用还有缓存中间件、消息队列、全文检索等一系列中间件的配置文件。而在分布式情况下,发布在多个节点上的Pod 副本都需要访问同一份配置文件,这也加大了配置管理的难度,为此业内的一些大公司专门开发了自己的一套配置管理中心,如360 的Qcon、百度的Disconf 等,但这些解决方案都比较复杂而且有侵入性。Kubernetes 则提供了无侵入的更简单的方案,这就是ConfigMap,我们可以把任意数量的配置文件放入ConfigMap 中,实现集中化管理,然后通过环境变量的方式将配置数据传递到Pod 里,或者通过Volume 方式挂载到Pod 内。
在Study Application 中,Web 应用在Kubernetes 上的建模如图6-4 所示。我们通过定义一个RC 来控制Web 的Pod 实例,数据库连接信息则通过环境变量传递到Pod 里,然后定义一个Service,并且通过NodePort 方式暴露到集群外供用户访问,即可完成这个Java应用的容器化改造工作。
正文到此结束
- 本文标签: 云 tab js 安全 代码 REST Word 分布式系统 stream mysql 源码 https centos RESTful 软件 http Elasticsearch 微服务 linux 定制 ip 集群 管理 消息队列 src 分布式 缓存 web tomcat cat 数据 Docker Connection 希望 Statement java 自动化 互联网 UI 实例 Uber 文件系统 JDBC spring db 进程 配置 Kubernetes 同步 IO session Ubuntu node 数据库 map App 百度 Service 性能优化 目录 端口 sql 空间 开发 Property Dockerfile
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

