Android 注解系列之APT工具(三)
在上篇文章 Android 注解系列之Annotation(二) 中,简要的介绍了注解的基本使用与定义。同时也提出了以下几个问题, 当我们声明了一个注解后,是不是需要手动找到所有的Class对象或Field、Method? , 怎么通过注解生成新的类的定义呢? 当面对这些问题的时候,我相信大家的第一反应肯定会想,"有不有相应的三方库呢?Java是否提供了相应库或者方法来解决呢?",当然Java肯定给我们提供了啦,就是我们既陌生又熟悉的 APT 工具啦。
为什么这里我会说既陌生又熟悉呢?我相信对于大多数安卓程序,我们都或多或少使用了一些主流库,如 Dagger2、ButterKnife、EventBus 等,这些库都使用了APT技术。既然大佬们都在使用,那我们怎么不去了解呢?好了,书归正传,下面我们就来看看怎么通过APT来处理之前我们提到的问题。
APT技术简介
在具体了解APT技术之前,先简单的对其进行介绍。 APT(Annotation Processing Tool) 是javac中提供的一种编译时扫描和处理注解的工具,它会对源代码文件进行检查,并找出其中的注解,然后根据用户自定义的注解处理方法进行额外的处理。APT工具不仅能解析注解,还能根据注解生成其他的源文件,最终将生成的新的源文件与原来的源文件共同编译( 注意:APT并不能对源文件进行修改操作,只能生成新的文件,例如在已有的类中添加方法 )。具体流程图如下图所示:
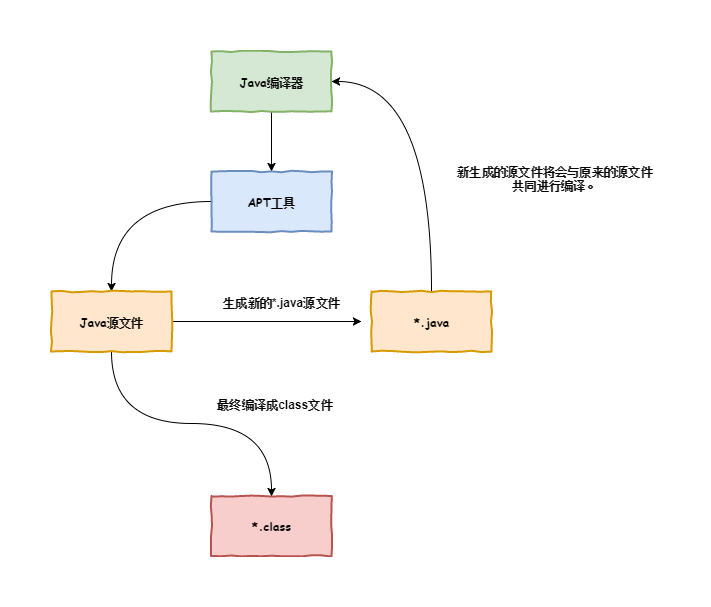
APT技术使用规则
APT技术的使用,需要我们遵守一定的规则。大家先看一下整个APT项目项目构建的一个规则图,具体如下所示:
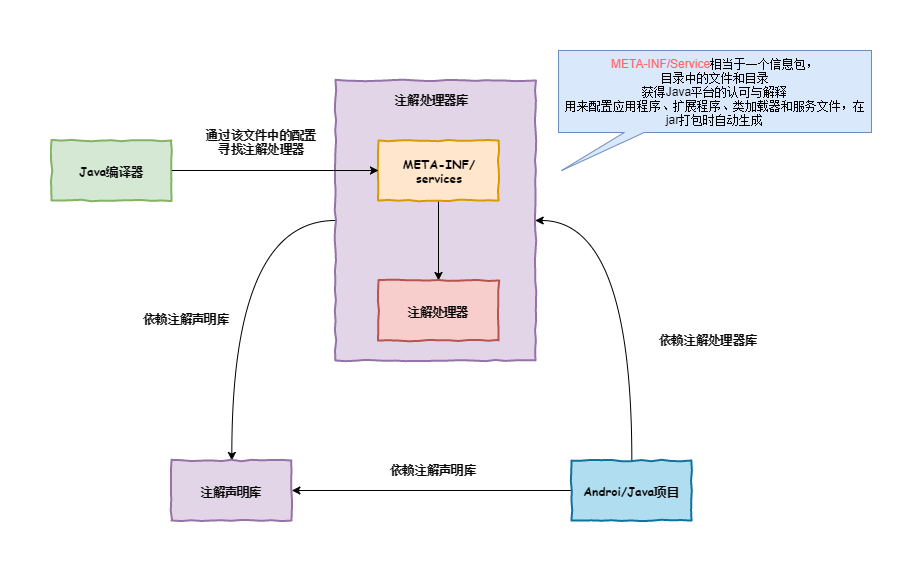
APT使用依赖
从图中我们可以整个APT项目的构建需要三个部分:
- 注解处理器库(包含我们的注解)
- 注解声明库(用于存储声明的注解)
- 实际使用APT的Android/Java项目
且三个部分的依赖关系为 注解处理工具依赖注解声明库 , Android/Java项目同时依赖注解处理工具库与注解声明库 。
为什么把注解处理器独立抽成一个库呢?
对于Android项目默认是不包含 APT相关类的。所以要使用APT技术,那么就必须创建一个Java Library。对于Java项目,独立抽成一个库,更容易维护与扩展。
为什么把注解声明也单独抽成一个库,而不放到注解处理工具库中呢?
举个例子,如果注解声明与注解处理器为同一个库,如果有开发者希望把我们的注解处理器用于他的项目中,那么就必须包含注解声明与整个注解处理器的代码,我们能非常确定是,他并不希望已经编译好的项目中包含处理器相关的代码。他仅仅希望使用我们的注解。所以将注解处理器与注解分开单独抽成一个库时非常有意义的。接下来的文章中会具体会描述有哪些方法可以将我们的注解处理器不打包在我们的实际项目中。
注解处理器的声明
在了解了ATP的使用规则后,现在我们再来看看怎么声明一个注解处理器,每一个注解处理器都需要承 AbstractProcessor 类,具体代码如下所示:
class MineProcessor extends AbstractProcessor {
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
return false;
}
@Override
public SourceVersion getSupportedSourceVersion() { }
@Override
public Set<String> getSupportedAnnotationTypes() { }
}
复制代码
-
init(ProcessingEnvironment processingEnv):每个注解处理器被初始化的时候都会被调用,该方法会被传入ProcessingEnvironment 参数。ProcessingEnvironment 能提供很多有用的工具类,Elements、Types和Filer。后面我们将会看到详细的内容。 -
process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv):注解处理器实际处理方法,一般要求子类实现该抽象方法,你可以在在这里写你的扫描与处理注解的代码,以及生成Java文件。其中参数RoundEnvironment ,可以让你查询出包含特定注解的被注解元素,后面我们会看到详细的内容。 -
getSupportedAnnotationTypes(): 返回当前注解处理器处理注解的类型,返回值为一个字符串的集合。其中字符串为处理器需要处理的注解的合法全称。 -
getSupportedSourceVersion():用来指定你使用的Java版本,通常这里返回SourceVersion.latestSupported()。如果你有足够的理由指定某个Java版本的话,你可以返回SourceVersion.RELAEASE_XX。但是还是推荐使用前者。
在Java1.6版本中提供了 SupportedAnnotationTypes 与 SupportedSourceVersion 两个注解来替代 getSupportedSourceVersion 与 getSupportedAnnotationTypes 两个方法,也就是这样:
@SupportedSourceVersion(SourceVersion.RELEASE_6)
@SupportedAnnotationTypes({"合法注解的名称"})
class MineProcessor extends AbstractProcessor {
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
return false;
}
}
复制代码
这里需要注意的是以上提到的两个注解是JAVA 1.6新增的,所以出于兼容性的考虑,建议还是直接重写 getSupportedSourceVersion() 与 getSupportedAnnotationTypes() 方法。
注册注解处理器
到了现在我们基本了解了处理器声明,现在我们可能会有个疑问, 怎么样将注解处理器注册到Java编译器中去呢? 你必须提供一个 .jar 文件,就像其他.jar文件一样,你需要打包你的注解处理器到此文件中,并且在你的jar中,你需要打包一个特定的文件 javax.annotation.processing.Processor 到 META-INF/services路径 下。就像下面这样:
META-INF/services 相当于一个信息包,目录中的文件和目录获得Java平台的认可与解释用来配置应用程序、扩展程序、类加载器和服务文件,在jar打包时自动生成
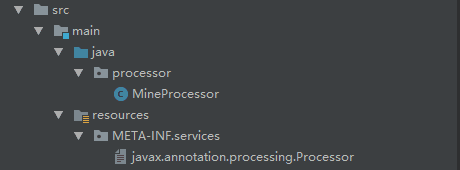
其中javax.annotation.processing.Processor文件中的内容为每个注解处理器的合法的全名列表,每一个元素换行分割,也就是类似下面这样:
com.jennifer.andy.processor.MineProcessor1 com.jennifer.andy.processor.MineProcessor2 com.jennifer.andy.processor.MineProcessor3 复制代码
最后我们只要将你生成的 .jar 放到你的buildPath中,那么Java编译器会自动的检查和读取 javax.annotation.processing.Processor 中的内容,并注册该注解处理器。
当然对于现在我们的编译器,如IDEA、AndroidStudio等中,我们只创建相应文件与文件夹就行了,并不同用放在buildPath中去。当然原因是这些编译器都帮我们处理了啦。如果你还是嫌麻烦,那我们可以使用Google为我们提供的 AutoService 注解处理器,用于生成META-INF/services/javax.annotation.processing.Processor文件的。也就是我们可以像下面这样使用:
@SupportedSourceVersion(SourceVersion.RELEASE_6)
@SupportedAnnotationTypes({"合法注解的名称"})
@AutoService(Processor.class)
class MineProcessor extends AbstractProcessor {
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
return false;
}
}
复制代码
我们只需要在类上声明 @AutoService(Processor.class) ,那么就不用考虑其他的东西啦。是不是很方便呢?(当然使用AutoService在Gralde中你需要添加依赖 compile 'com.google.auto.service:auto-service:1.0-rc2' )。
注解处理器的扫描
在注解处理过程中,我们需要扫描所有的Java源文件,源代码的每一个部分都是一个特定类型的 Element ,也就是说Element代表源文件中的元素,例如包、类、字段、方法等。整体的关系如下图所示:
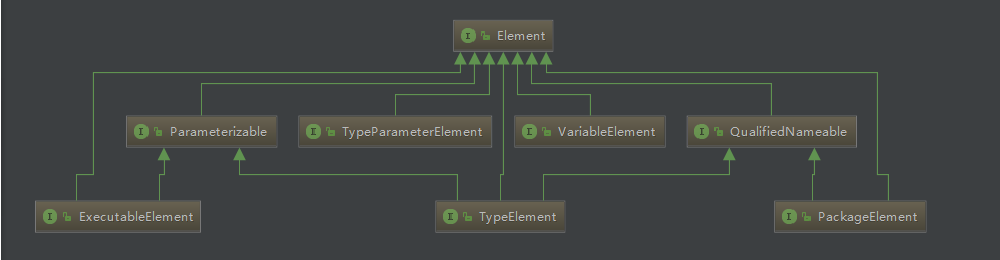
- Parameterizable:表示混合类型的元素(不仅只有一种类型的Element)
- TypeParameterElement:带有泛型参数的类、接口、方法或者构造器。
- VariableElement:表示字段、常量、方法或构造函数。参数、局部变量、资源变量或异常参数。
- QualifiedNameable:具有限定名称的元素
- ExecutableElement:表示类或接口的方法、构造函数或初始化器(静态或实例),包括注释类型元素。
- TypeElement :表示类和接口
- PackageElement:表示包
那接下来我们通过下面的例子来具体的分析:
package com.jennifer.andy.aptdemo.domain;//PackageElement
class Person {//TypeElement
private String where;//VariableElement
public void doSomething() { }//ExecutableElement
public void run() {//ExecutableElement
int runTime;//VariableElement
}
}
复制代码
通过上述例子我们可以看出,APT对整个源文件的扫描。有点类似于我们解析XML文件(这种结构化文本一样)。
既然在扫描的时候, 源文件是一种结构化的数据 ,那么我们能不能获取一个元素的父元素和子元素呢?。当然是可以的啦,举例来说,假如我们有个 public class Person的TypeElement元素 ,那么我们可以遍历它的所有的孩子元素。
TypeElement person= ... ;
for (Element e : person.getEnclosedElements()){ // 遍历它的孩子
Element parent = e.getEnclosingElement(); // 拿到孩子元素的最近的父元素
}
复制代码
其中 getEnclosedElements() 与 getEnclosingElement() 为 Element 中接口的声明,想了解更多的内容,大家可以查看一下源码。
元素种类判断
现在我们已经了解了 Element 元素的分类,但是我们发现Element有时会代表多种元素。例如 TypeElement代表类或接口 ,那有什么方法具体区别呢?我们继续看下面的例子:
public class SpiltElementProcessor extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
//这里通过获取所有包含Who注解的元素set集合
Set<? extends Element> elements = roundEnvironment.getElementsAnnotatedWith(Who.class);
for (Element element : elements) {
if (element.getKind() == ElementKind.CLASS) {//如果元素是类
} else if (element.getKind() == ElementKind.INTERFACE) {//如果当前元素是接口
}
}
return false;
}
...省略部分代码
}
复制代码
在上述例子中,我们通过 roundEnvironment.getElementsAnnotatedWith(Who.class) 获取源文件中所有包含 @Who 注解的元素,通过调用element.getKind()具体判断当前元素种类,其中具体元素类型为 ElementKind枚举类型 。 ElementKind 枚举声明如下表所示:
| 枚举类型 | 种类 |
|---|---|
| PACKAGE | 包 |
| ENUM | 枚举 |
| CLASS | 类 |
| ANNOTATION_TYPE | 注解 |
| INTERFACE | 接口 |
| ENUM_CONSTANT | 枚举常量 |
| FIELD | 字段 |
| PARAMETER | 参数 |
| LOCAL_VARIABLE | 本地变量 |
| EXCEPTION_PARAMETER | 异常参数 |
| METHOD | 方法 |
| CONSTRUCTOR | 构造函数 |
| OTHER | 其他 |
| 省略... | 省略... |
元素类型判断
那接下来大家又会有一个问题了,既然我们在扫描的是获取的元素且这些元素代表着源文件中的结构化数据。那么假如我们想获得元素更多的信息怎么办呢?例如对于某个类,现在我们已经知道了其为 ElementKind.CLASS 种类,但是我想获取其父类的信息,需要通过什么方式呢?对于某个方法,我们也同样知道了其为 ElementKind.METHOD 种类,那么我想获取该方法的返回值类型、参数类型、参数名称,需要通过什么方式呢?
当然Java已经为我们提供了相应的方法啦。使用 mirror API 就能解决这些问题啦, 它能使我们在未经编译的源代码中查看方法、域以及类型信息 。在实际使用中通过 TypeMirror 来获取元素类型。看下面的例子:
public class TypeKindSpiltProcessor extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
Set<? extends Element> elements = roundEnvironment.getElementsAnnotatedWith(Who.class);
for (Element element : elements) {
if (element.getKind() == ElementKind.METHOD) {//如果当前元素是接口
ExecutableElement methodElement = (ExecutableElement) element;
TypeMirror returnType = methodElement.getReturnType();//获取TypeMirror
TypeKind kind = returnType.getKind();//获取元素类型
System.out.println("print return type----->" + kind.toString());
}
}
return false;
}
}
复制代码
观察上述代码我们可以发现,当我们使用注解处理器时,我们会先找到相应的Element,如果你想获得该Element的更多的信息,那么可以配合TypeMirror使用 TypeKind 来判断当前元素的类型。当然对于不同种类的Element,其获取的TypeMirror方法可能会不同。 TypeKind 枚举声明如下表所示:
| 枚举类型 | 类型 |
|---|---|
| BOOLEAN | boolean 类型 |
| BYTE | byte 类型 |
| SHORT | short 类型 |
| INT | int 类型 |
| LONG | long 类型 |
| CHAR | char 类型 |
| FLOAT | float 类型 |
| DOUBLE | double 类型 |
| VOID | void类型,主要用于方法的返回值 |
| NONE | 无类型 |
| NULL | 空类型 |
| ARRAY | 数组类型 |
| 省略... | 省略... |
元素可见性修饰符
在注解处理器中,我们不仅能获得元素的种类和信息,我们还能获取该元素的可见性修饰符(例如public、private等)。我们可以直接调用 Element.getModifiers() ,具体代码如下所示:
public class GetModifiersProcessor extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
Set<? extends Element> elements = roundEnvironment.getElementsAnnotatedWith(Who.class);
for (Element element : elements) {
if (element.getKind() == ElementKind.CLASS) {//如果元素是类
Set<Modifier> modifiers = element.getModifiers();//获取可见性修饰符
if (!modifiers.contains(Modifier.PUBLIC)) {//如果当前类不是public
throw new ProcessingException(classElement, "The class %s is not public.",
classElement.getQualifiedName().toString());
}
}
return false;
}
}
复制代码
在上述代码中 Modifer为枚举类型 ,具体枚举如下所示:
public enum Modifier {
/** The modifier {@code public} */ PUBLIC,
/** The modifier {@code protected} */ PROTECTED,
/** The modifier {@code private} */ PRIVATE,
/** The modifier {@code abstract} */ ABSTRACT,
/**
* The modifier {@code default}
* @since 1.8
*/
DEFAULT,
/** The modifier {@code static} */ STATIC,
/** The modifier {@code final} */ FINAL,
/** The modifier {@code transient} */ TRANSIENT,
/** The modifier {@code volatile} */ VOLATILE,
/** The modifier {@code synchronized} */ SYNCHRONIZED,
/** The modifier {@code native} */ NATIVE,
/** The modifier {@code strictfp} */ STRICTFP;
}
复制代码
错误处理
在注解处理器的自定义中,我们不仅能调用相关方法获取源文件中的元素信息,还能通过处理器提供的 Messager 来报告错误、警告以及提示信息。可以直接使用 processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE, msg); 需要注意的是它并不是处理器开发中的日志工具,而是用来写一些信息给使用此注解库的第三方开发者的。也就是说如果我们像传统的Java应用程序抛出一个异常的话,那么运行注解处理器的JVM就会崩溃,并且关于JVM中的错误信息对于第三方开发者并不是很友好,所以推荐并且强烈建议使用 Messager 。就像下面这样,当我们判断某个类不是public修饰的时候,我们通过 Messager 来报告错误。
注解处理器是运行它自己的虚拟机JVM中。是的,你没有看错,javac启动一个完整Java虚拟机来运行注解处理器。
public class GetModifiersProcessor extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
Set<? extends Element> elements = roundEnvironment.getElementsAnnotatedWith(Who.class);
for (Element element : elements) {
if (element.getKind() == ElementKind.CLASS) {//如果元素是类
Set<Modifier> modifiers = element.getModifiers();//获取可见性修饰符
if (!modifiers.contains(Modifier.PUBLIC)) {//如果当前类不是public
roundEnvironment.getMessager().printMessage(Diagnostic.Kind.ERROR, "the class is not public");
}
}
return false;
}
}
复制代码
同时,在官方文档中,描述了消息的不同级别,关于更多的消息级别,大家可以通过从 Diagnostic.Kind 枚举中查看。
文件生成
到了现在我们已经基本了解整个APT的基础知识。现在来讲讲APT技术如何 生成新的类的定义(也就是创建新的源文件) 。对于创建新的文件,我们并不用像基本文件操作一样,通过调用IO流来进行读写操作。而是通过 JavaPoet 来构造源文件。(当然当你使用 JavaPoet 时,在gradle中你需要添加依赖 compile 'com.google.auto.service:auto-service:1.0-rc2' ), JavaPoet 的使用也非常简单,就像下面这样:
当进行注释处理或与元数据文件(例如,数据库模式、协议格式)交互时,JavaPoet对于源文件的生成可能非常有用。通过生成代码,消除了编写样板的必要性,同时也保持了元数据的单一来源。
@AutoService(Processor.class)
@SupportedAnnotationTypes("com.jennifer.andy.apt.annotation.Who")
@SupportedSourceVersion(SourceVersion.RELEASE_7)
public class CreateFileByJavaPoetProcessor extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
createFileByJavaPoet(set, roundEnvironment);
return false;
}
/**
* 通过JavaPoet生成新的源文件
*/
private void createFileByJavaPoet(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
//创建main方法
MethodSpec main = MethodSpec.methodBuilder("main")
.addModifiers(Modifier.PUBLIC, Modifier.STATIC)//设置可见性修饰符public static
.returns(void.class)//设置返回值为void
.addParameter(String[].class, "args")//添加参数类型为String数组,且参数名称为args
.addStatement("$T.out.println($S)", System.class, "Hello, JavaPoet!")//添加语句
.build();
//创建类
TypeSpec helloWorld = TypeSpec.classBuilder("HelloWorld")
.addModifiers(Modifier.PUBLIC, Modifier.FINAL)
.addMethod(main)//将main方法添加到HelloWord类中
.build();
//创建文件,第一个参数是包名,第二个参数是相关类
JavaFile javaFile = JavaFile.builder("com.jennifer.andy.aptdemo.domain", helloWorld)
.build();
try {
//创建文件
javaFile.writeTo(processingEnv.getFiler());
} catch (IOException e) {
log(e.getMessage());
}
}
/**
* 调用打印语句而已
*/
private void log(String msg) {
processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE, msg);
}
}
复制代码
当我们build上述代码后,我们可以在我们的build目录下得到下列文件:
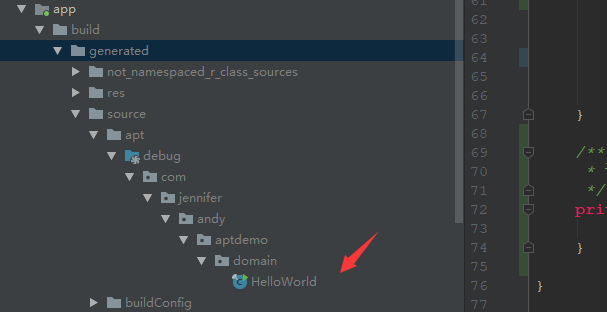
关于JavaPoet的更多的详细使用,大家可以参考官方文档--------> JavaPoet
分离处理器和项目
在上文中描述的APT使用规则中,我们是将 注解声明库 与 注解处理器库 分成了两个库,具体原因我也做了详细的解释,现在我们来思考如下问题。就算我们把两个库都抽成了两个独立的库,但是如果有开发者想把我们自定义的注解处理器用于他的项目中,那么他整个项目的编译就必须也要把注解处理器与注解声明库包括进来。对于开发者来说,他们并不希望已经编译好的项目中有包含注解处理器的相关代码。所以将 注解声明库与注解处理器库不打包进入项目是非常有必要的!! 换句话说,注解处理器只在编译处理期间需要用到,编译处理完后就没有实际作用了,而主项目添加了这个库会引入很多不必要的文件。
因为作者我本身是Android开发人员,所以以下都是针对Android项目展开讨论。
使用android-apt
anroid-apt是Hugo Visser开发的一个Gradle插件,该插件的主要作用有如下两点:
- 允许只将编译时注释处理器配置为依赖项,而不在最终APK或库中包括工件
- 设置源路径,以便Android Studio能正确地找到注释处理器生成的代码
但是 Google爸爸看到别人这个功能功能不错,所以为自己的Android Gradle 插件也添加了名为 annotationProcessor 的功能来完全代替 android-apt,既然官方支持了。那我们就去看看annotationProcessor的使用吧。
annotationProcessor使用
其实annotationProcessor的使用也非常简单,分为两种类型,具体使用如下代码所示:
annotationProcessor project(':apt_compiler')//如果是本地库
annotationProcessor 'com.jakewharton:butterknife-compiler:9.0.0-rc1'//如果是远程库
复制代码
总结
整个APT的流程下来,自己也查阅了非常多的资料,也解决了许多问题。虽然写博客也花了非常多的时间。但是自己也发现了很多有趣的问题。我发现查阅的相关资料都会有一个 通病 。也就是没有真正搞懂 android apt与annotationProcessor 的具体作用。所以这里这里也要告诫大家, 对于网上的资料,自己一定要带着怀疑与疑问的态度去浏览 。
同时个人觉得Gradle这一块的知识点也非常重要。因为关于怎么不把库打包到实际项目中也是构建工具的特性与功能。希望大家有时间, 一定要学习下相关Gradle知识 。作者最近也在学习呢。和我一起加油吧~
该文章中涉及的代码,我已经提交到GitHub上了,大家按需下载----> 源码
正文到此结束
- 本文标签: zab db UI 时间 XML build 下载 MQ Statement tab 配置 代码 实例 总结 文章 IO 类加载器 源码 cat GitHub DOM final ACE 自动生成 synchronized 协议 数据库 Google 遍历 volatile Word constant JVM 编译 API 解析 开发 博客 Service bus java https IDE Android 返回值类型 http 处理器 id 目录 git 数据 CTO 参数 src message tk struct 开发者 注释 插件 lib FAQ 希望
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

