Shading - jdbc 源码分析(四) - sql 路由
上一篇文章我们分析了sharding-jdbc 解析 select 语句(sql 解析之 Select),今天我们分析下sql路由。
声明:本文基于1.5.M1版本
时序图:
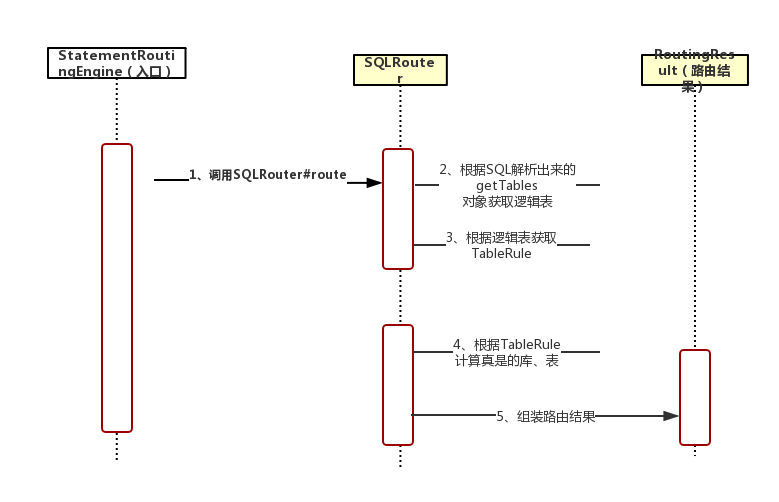
执行逻辑
下面我们以上篇文章的Select语句分析:
SELECT o.order_id FROM order o WHERE o.order_id = 4
在分析之前首先看下分库分表的配置:
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds_0", null);
dataSourceMap.put("ds_1", null);
DataSourceRule dataSourceRule = new DataSourceRule(dataSourceMap);
TableRule orderTableRule = TableRule.builder("order").actualTables(Lists.newArrayList("order_0", "order_1")).dataSourceRule(dataSourceRule).build();
TableRule orderItemTableRule = TableRule.builder("order_item").actualTables(Lists.newArrayList("order_item_0", "order_item_1")).dataSourceRule(dataSourceRule).build();
TableRule orderAttrTableRule = TableRule.builder("order_attr").actualTables(Lists.newArrayList("ds_0.order_attr_a", "ds_1.order_attr_b")).dataSourceRule(dataSourceRule)
.tableShardingStrategy(new TableShardingStrategy("order_id", new OrderAttrShardingAlgorithm())).build();
shardingRule = ShardingRule.builder().dataSourceRule(dataSourceRule).tableRules(Lists.newArrayList(orderTableRule, orderItemTableRule, orderAttrTableRule))
.bindingTableRules(Collections.singletonList(new BindingTableRule(Arrays.asList(orderTableRule, orderItemTableRule))))
.databaseShardingStrategy(new DatabaseShardingStrategy("order_id", new OrderShardingAlgorithm()))
.tableShardingStrategy(new TableShardingStrategy("order_id", new OrderShardingAlgorithm())).build();
复制代码
order表分了2个库,2个表,以order_id为分片键
1、StatementRoutingEngine 路由入口:
- 构造方法:通过ShardingContext(分片上下文)创建SQLRouter
- SQLRouter 解析SQL(内部调用上一片文章的SQLParsingEngine),并路由
public StatementRoutingEngine(final ShardingContext shardingContext) {
sqlRouter = SQLRouterFactory.createSQLRouter(shardingContext);
}
/**
* SQL路由.
*
* @param logicSQL 逻辑SQL
* @return 路由结果
*/
public SQLRouteResult route(final String logicSQL) {
SQLStatement sqlStatement = sqlRouter.parse(logicSQL, 0);
return sqlRouter.route(logicSQL, Collections.emptyList(), sqlStatement);
}
复制代码
这里判断是否只分库,若只分库,则new UnparsingSQLRouter,不需要走SQL解析的逻辑(直接落到具体的库,执行SQL即可),否则new ParsingSQLRouter
/**
* 创建SQL路由器.
*
* @param shardingContext 数据源运行期上下文
* @return SQL路由器
*/
public static SQLRouter createSQLRouter(final ShardingContext shardingContext) {
return HintManagerHolder.isDatabaseShardingOnly() ? new UnparsingSQLRouter(shardingContext) : new ParsingSQLRouter(shardingContext);
}
复制代码
2、ParsingSQLRouter#route:
public SQLRouteResult route(final String logicSQL, final List<Object> parameters, final SQLStatement sqlStatement) {
final Context context = MetricsContext.start("Route SQL");
SQLRouteResult result = new SQLRouteResult(sqlStatement);
if (sqlStatement instanceof InsertStatement && null != ((InsertStatement) sqlStatement).getGeneratedKey()) {
//insert 语句处理主键(有空分析分析)
processGeneratedKey(parameters, (InsertStatement) sqlStatement, result);
}
//路由
RoutingResult routingResult = route(parameters, sqlStatement);
...(后面是重写的逻辑,先省略)
MetricsContext.stop(context);
logSQLRouteResult(result, parameters);
return result;
}
复制代码
2-1、根据sqlStatement解析的表对象获取逻辑表
若单表,走SimpleRoutingEngine#route,否则走ComplexRoutingEngine#route
private RoutingResult route(final List<Object> parameters, final SQLStatement sqlStatement) {
Collection<String> tableNames = sqlStatement.getTables().getTableNames();
RoutingEngine routingEngine;
if (1 == tableNames.size() || shardingRule.isAllBindingTables(tableNames)) {
routingEngine = new SimpleRoutingEngine(shardingRule, parameters, tableNames.iterator().next(), sqlStatement);
} else {
// TODO 可配置是否执行笛卡尔积
routingEngine = new ComplexRoutingEngine(shardingRule, parameters, tableNames, sqlStatement);
}
return routingEngine.route();
}
复制代码
2-2、SimpleRoutingEngine#route
正常情况下都是单表,我们就以单表的情况分析
- 根据逻辑表名词获取我们配置的TableRule
- 根据TableRule获取真实的db、table
- 组装RoutingResult
public RoutingResult route() {
TableRule tableRule = shardingRule.getTableRule(logicTableName);
Collection<String> routedDataSources = routeDataSources(tableRule);
Collection<String> routedTables = routeTables(tableRule, routedDataSources);
return generateRoutingResult(tableRule, routedDataSources, routedTables);
}
复制代码
- getTableRule: 首先根据逻辑表查找,找到了就直接返回,没找到的话判断我们的默认数据库是不是存在,然后用默认数据库帮我们创建一个无需分库分表的TableRule
/**
* 根据逻辑表名称查找分片规则.
*
* @param logicTableName 逻辑表名称
* @return 该逻辑表的分片规则
*/
public TableRule getTableRule(final String logicTableName) {
Optional<TableRule> tableRule = tryFindTableRule(logicTableName);
if (tableRule.isPresent()) {
return tableRule.get();
}
if (dataSourceRule.getDefaultDataSource().isPresent()) {
return createTableRuleWithDefaultDataSource(logicTableName, dataSourceRule);
}
throw new ShardingJdbcException("Cannot find table rule and default data source with logic table: '%s'", logicTableName);
}
复制代码
private TableRule createTableRuleWithDefaultDataSource(final String logicTableName, final DataSourceRule defaultDataSourceRule) {
Map<String, DataSource> defaultDataSourceMap = new HashMap<>(1);
defaultDataSourceMap.put(defaultDataSourceRule.getDefaultDataSourceName(), defaultDataSourceRule.getDefaultDataSource().get());
return TableRule.builder(logicTableName)
.dataSourceRule(new DataSourceRule(defaultDataSourceMap))
.databaseShardingStrategy(new DatabaseShardingStrategy("", new NoneDatabaseShardingAlgorithm()))
.tableShardingStrategy(new TableShardingStrategy("", new NoneTableShardingAlgorithm())).build();
}
复制代码
- routeDataSources:(注释就写在代码里了)
private Collection<String> routeDataSources(final TableRule tableRule) {
1、根据TableRule 获取数据库分片策略
DatabaseShardingStrategy strategy = shardingRule.getDatabaseShardingStrategy(tableRule);
2、判断有没有用强制路由,有的话直接用强制路由的value,没有的话就用我们查询条件里面用到的分片value
List<ShardingValue<?>> shardingValues = HintManagerHolder.isUseShardingHint() ? getDatabaseShardingValuesFromHint(strategy.getShardingColumns())
: getShardingValues(strategy.getShardingColumns());
logBeforeRoute("database", logicTableName, tableRule.getActualDatasourceNames(), strategy.getShardingColumns(), shardingValues);
3、调用分片策略计算分片值
Collection<String> result = strategy.doStaticSharding(sqlStatement.getType(), tableRule.getActualDatasourceNames(), shardingValues);
logAfterRoute("database", logicTableName, result);
Preconditions.checkState(!result.isEmpty(), "no database route info");
return result;
}
复制代码
- routeTables(没区别嘛)
private Collection<String> routeTables(final TableRule tableRule, final Collection<String> routedDataSources) {
TableShardingStrategy strategy = shardingRule.getTableShardingStrategy(tableRule);
List<ShardingValue<?>> shardingValues = HintManagerHolder.isUseShardingHint() ? getTableShardingValuesFromHint(strategy.getShardingColumns())
: getShardingValues(strategy.getShardingColumns());
logBeforeRoute("table", logicTableName, tableRule.getActualTables(), strategy.getShardingColumns(), shardingValues);
Collection<String> result = tableRule.isDynamic() ? strategy.doDynamicSharding(shardingValues)
: strategy.doStaticSharding(sqlStatement.getType(), tableRule.getActualTableNames(routedDataSources), shardingValues);
logAfterRoute("table", logicTableName, result);
Preconditions.checkState(!result.isEmpty(), "no table route info");
return result;
}
复制代码
强制路由的感觉可以单独写一篇文章说,所以就不分析了,以后写,我们看不走强制路由的逻辑。
- getShardingValues
private List<ShardingValue<?>> getShardingValues(final Collection<String> shardingColumns) {
List<ShardingValue<?>> result = new ArrayList<>(shardingColumns.size());
for (String each : shardingColumns) {
//SQL解析的getConditions对象(上一篇文章简单分析过),这里查找分片列是否存在,存在就转换为ShardingValue
Optional<Condition> condition = sqlStatement.getConditions().find(new Column(each, logicTableName));
if (condition.isPresent()) {
result.add(condition.get().getShardingValue(parameters));
}
}
return result;
}
复制代码
- getShardingValue
operator:这个可以理解为条件对象的操作符号(=、in、between)
/**
* 将条件对象转换为分片值.
*
* @param parameters 参数列表
* @return 分片值
*/
public ShardingValue<?> getShardingValue(final List<Object> parameters) {
List<Comparable<?>> conditionValues = getValues(parameters);
switch (operator) {
case EQUAL:
return new ShardingValue<Comparable<?>>(column.getTableName(), column.getName(), conditionValues.get(0));
case IN:
return new ShardingValue<>(column.getTableName(), column.getName(), conditionValues);
case BETWEEN:
return new ShardingValue<>(column.getTableName(), column.getName(), Range.range(conditionValues.get(0), BoundType.CLOSED, conditionValues.get(1), BoundType.CLOSED));
default:
throw new UnsupportedOperationException(operator.getExpression());
}
}
复制代码
- getValues
positionValueMap:存放条件值(分片Value),positionIndexMap:这段逻辑似乎没太看懂。。
private List<Comparable<?>> getValues(final List<Object> parameters) {
List<Comparable<?>> result = new LinkedList<>(positionValueMap.values());
for (Entry<Integer, Integer> entry : positionIndexMap.entrySet()) {
Object parameter = parameters.get(entry.getValue());
if (!(parameter instanceof Comparable<?>)) {
throw new ShardingJdbcException("Parameter `%s` should extends Comparable for sharding value.", parameter);
}
if (entry.getKey() < result.size()) {
result.add(entry.getKey(), (Comparable<?>) parameter);
} else {
result.add((Comparable<?>) parameter);
}
}
return result;
}
复制代码
- ShardingStrategy#doStaticSharding:
/**
* 计算静态分片.
*
* @param sqlType SQL语句的类型
* @param availableTargetNames 所有的可用分片资源集合
* @param shardingValues 分片值集合
* @return 分库后指向的数据源名称集合
*/
public Collection<String> doStaticSharding(final SQLType sqlType, final Collection<String> availableTargetNames, final Collection<ShardingValue<?>> shardingValues) {
Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
if (shardingValues.isEmpty()) {
Preconditions.checkState(!isInsertMultiple(sqlType, availableTargetNames), "INSERT statement should contain sharding value.");
result.addAll(availableTargetNames);
} else {
result.addAll(doSharding(shardingValues, availableTargetNames));
}
return result;
}
复制代码
一般我们的表实现 SingleKeyShardingAlgorithm 类,定义我们自己的分片逻辑,返回计算出来的结果值
private Collection<String> doSharding(final Collection<ShardingValue<?>> shardingValues, final Collection<String> availableTargetNames) {
if (shardingAlgorithm instanceof NoneKeyShardingAlgorithm) {
return Collections.singletonList(((NoneKeyShardingAlgorithm) shardingAlgorithm).doSharding(availableTargetNames, shardingValues.iterator().next()));
}
if (shardingAlgorithm instanceof SingleKeyShardingAlgorithm) {
SingleKeyShardingAlgorithm<?> singleKeyShardingAlgorithm = (SingleKeyShardingAlgorithm<?>) shardingAlgorithm;
ShardingValue shardingValue = shardingValues.iterator().next();
switch (shardingValue.getType()) {
case SINGLE:
return Collections.singletonList(singleKeyShardingAlgorithm.doEqualSharding(availableTargetNames, shardingValue));
case LIST:
return singleKeyShardingAlgorithm.doInSharding(availableTargetNames, shardingValue);
case RANGE:
return singleKeyShardingAlgorithm.doBetweenSharding(availableTargetNames, shardingValue);
default:
throw new UnsupportedOperationException(shardingValue.getType().getClass().getName());
}
}
if (shardingAlgorithm instanceof MultipleKeysShardingAlgorithm) {
return ((MultipleKeysShardingAlgorithm) shardingAlgorithm).doSharding(availableTargetNames, shardingValues);
}
throw new UnsupportedOperationException(shardingAlgorithm.getClass().getName());
}
复制代码
- 最后
过滤获取真实的DataNode,组装RoutingResult
private RoutingResult generateRoutingResult(final TableRule tableRule, final Collection<String> routedDataSources, final Collection<String> routedTables) {
RoutingResult result = new RoutingResult();
for (DataNode each : tableRule.getActualDataNodes(routedDataSources, routedTables)) {
result.getTableUnits().getTableUnits().add(new TableUnit(each.getDataSourceName(), logicTableName, each.getTableName()));
}
return result;
}
复制代码
最后:
小尾巴走一波,欢迎关注我的公众号,不定期分享编程、投资、生活方面的感悟:)

正文到此结束
- 本文标签: 注释 value http ArrayList tab 数据库 代码 key src LinkedList 源码 find Collections build HashMap ssh tar 数据 Select dataSource sharding tk UI parse 投资 id Statement https 配置 解析 final Collection JDBC ip map CTO 参数 IO 构造方法 db sql CEO list 文章 equals node Datanode
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

