Java字节码结构剖析二:字段表
上篇介绍了字节码文件的结构和其常量池分析。紧接其后呢,我们要去了解字段表的概念和组成结构。接着上篇里的字节码的常量池往后分析。
access_flags
访问标志信息包括该class文件是类还是接口,是否定义成public,是否是abstract,如果是类,是否被申明为final。access_flags 的取值范围和相应含义见下表。
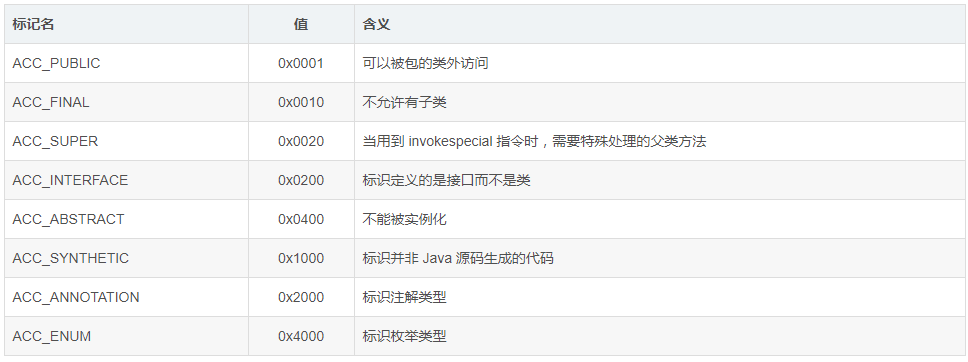
我们的字节码里该位置的16进制表示是0×0021。0×0021=0×0001 ^ 0×0020。即代表该类的访问修饰是public的。ACC_SUPER这里不做介绍,看看JVM规范对他的描述,了解即可。
ACC_SUPER 标志用于确定该 Class 文件里面的 invokespecial 指令使用的是哪一种执行语义。目前 Java 虚拟机的编译器都应当设置这个标志。ACC_SUPER 标记是为了向后兼容旧编译器编译的 Class 文件而存在的,在 JDK1.0.2 版本以前的编译器产生的 Class 文件中,access_flag 里面没有 ACC_SUPER 标志。同时,JDK1.0.2 前的 Java 虚拟机遇到 ACC_SUPER 标记会自动忽略它。
this_class_name
类索引,this_class 的值必须是对 constant_pool 表中项目的一个有效索引值。constant_pool 表在这个索引处的项必须为 CONSTANT_Class_info 类型常量,表示这个 Class 文件所定义的类或接口。
在我的字节码文件中,该16进制值为0×0005=5。通过常量池信息,最终他指向的是一个utf-8字符串,com/shengsiyuan/jvm/bytecode/MyTest2。即类的全限定名。
#5 = Class #38 // com/shengsiyuan/jvm/bytecode/MyTest2 #38 = Utf8 com/shengsiyuan/jvm/bytecode/MyTest2
super_class_name
父类索引,对于类来说,super_class 的值必须为 0 或者是对 constant_pool 表中项目的一个有效索引值。
在字节码文件中,父类索引为0x000A=10。即父类是 java/lang/Object 。
#10 = Class #43 // java/lang/Object #43 = Utf8 java/lang/Object
interfaces_count
接口计数器,interfaces_count 的值表示当前类或接口的直接父接口数量。
我们的代码没有实现任何接口,所以该项值为0,即0×0000。
interfaces[]
接口表,interfaces[]数组中的每个成员的值必须是一个对 constant_pool 表中项目的一个有效索引值,它的长度为 interfaces_count。
我们代码没有接口,所以我们的字节码文件里没有这项了。所以 interfaces_count 后面就直接是字段计数器和字段表。
fields_count
字段计数器,fields_count 的值表示当前 Class 文件 fields[]数组的成员个数。也就是当前类的类字段和实例字段的个数。
我们源代码里定义了3个字段,1个类字段,2个实例字段。所以fields_count为3。查看对应字节码文件的16进制表示0×0003=3。
fields[]
字段表用于描述类和接口中声明的变量。这里的字段包含了类级别变量以及实例变量,但是不包括方法内部声明的局部变量。
field_info结构格式如下:
field_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
access_flags 项的值是用于定义字段被访问权限和基础属性的掩码标志。access_flags 的取值范围和相应含义见如下表:
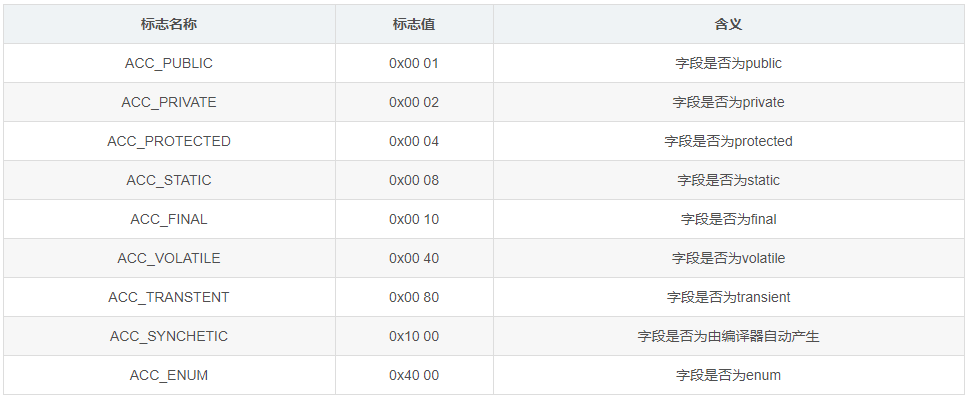
看在我字节码中的16进制表示,0×0000=0。0代表没有修饰符的意思。看我们的源码:String str = “Welcome”;,即默认修饰符。
- name_index 项的值必须是对常量池的一个有效索引。常量池在该索引处的项必须是CONSTANT_Utf8_info结构,表示一个有效的字段的非全限定名。
在字节码里是0x000B=11。常量池11处:
#11 = Utf8 str
表示字段的名称为“str”。
- descriptor_index 项的值必须是对常量池的一个有效索引。常量池在该索引处的项必须是CONSTANT_Utf8_info结构,表示一个有效的字段的描述符。
字节码中,0x000C=12。看常量池:
#12 = Utf8 Ljava/lang/String;
表示该字段是String类型。
在JVM规范中,每个变量/字段都有描述信息,描述信息主要作用是描述字段的数据类型、方法的参数列表(包括数量,类型与顺序)与返回值。根据描述符规则,基本数据类型和代表无返回值的void类型都用一个大写字符来表示,对象类型则使用字符L加对象的全限定名称来表示。为了压缩字节码文件的体积,对于基本数据类型,JVM都只使用一个大写字母表示,如下所示:B-byte、C-char、D-double、F-float、I-int、J-long、S-short、Z-boolean、V-void、L-对象类型,如Ljava/lang/String。
对于数组类型来说,每一个纬度使一个前置的[表示,如int[]被记录为[I,String[][]被记录为[[Ljava/lang/String;。- attributes_count的项的值表示当前字段的附加属性的数量。
在字节码里,0x0000=0。即该字段没有附加属性。
- attributes[]
attributes 表的每一个成员的值必须是 attribute结构,一个字段可以有任意个关联属性。
因为该字段没有附加属性,所以这项数据没有。
以上就是字段表里的第1个字段的完整字节码信息描述。也就是我们定义的『str』字段的信息。我们代码里还有2个字段 private int x = 5 和 public static Integer in = 10 。我便不再描述了,大家可以紧接着我后面把这两个字段的信息解析出来。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

