致传统企业朋友:不够痛就别微服务,有坑
微服务落地是一个复杂问题,牵扯到IT架构,应用架构,组织架构多个方面
在多家传统行业的企业走访和落地了微服务之后,发现落地微服务是一个非常复杂的问题,甚至都不完全是技术问题。
当时想微服务既然是改造应用,做微服务治理,类似注册,发现,熔断,限流,降级等,当然应该从应用开发组切入,一般一开始聊的会比较开心,从单体架构,到SOA,再到微服务架构,从Dubbo聊到Spring Cloud,但是必然会涉及到微服务的发布和运维问题,涉及到DevOps和容器层,这些都不在开发组的控制范围内,一旦拉进运维组,对于容器的接受程度就成了一个问题,和传统物理机,虚拟机的差别,会带来什么风险等等等等,尤其是容器绝对不是轻量级的虚拟化这件事情,就不是一时半会儿能说的明白的。更何况就算说明白了,还有线上应用容器,一旦出了事情,谁背锅的问题,容器往往会导致应用层和基础设施层界限模糊,这使得背锅双方都会犹豫不决。

有的企业的微服务化是运维部门发起的,运维部门已经意识到了各种各样不统一的应用给运维带来的苦,也乐意接受容器的运维模式,这就涉及到容器直接的服务发现是否应该运维在容器层搞定,还是应用应该自己搞定的问题,还涉及Dockerfile到底是开发写还是运维写的问题。一旦容器化的过程中,开发不配合,运维单方面去做这个事情,是徒增烦恼却收益有限的。
下图是微服务实施的过程中涉及到的层次,具体的描述参考文章:《 云架构师进阶攻略 》。
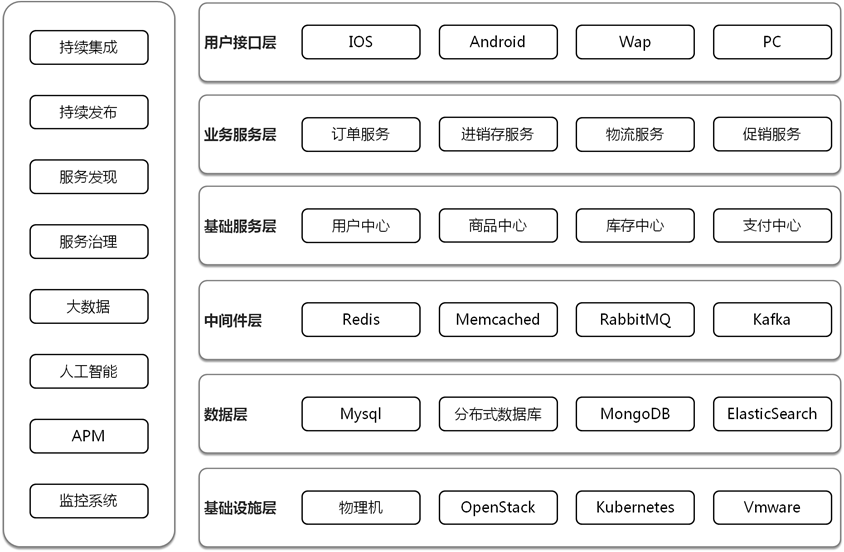
在一些相对先进的企业,会在运维组和开发组之间,有个中间件组,或者叫做架构组,来负责推动微服务化改造的事情,架构组就既需要负责劝说业务开发实施微服务化,也要劝说运维组实施容器化,如果架构组的权威性不足,推动往往也会比较困难。
所以微服务,容器,DevOps的推动,不单单是一个技术问题,更是一个组织问题,在推动微服务的过程中,更加能够感觉到康威定律的作用,需要更高层次技术总监或者CIO的介入,方能够推动微服务的落地。
然而到了CIO层,在很多企业又体会不到技术层面的痛点了,而更加关注业务的层面了,只要业务能赚钱,架构的痛,中间件的痛,运维的痛,高层不是非常能够感知,也就体会不到微服务,容器化的技术优势了,而微服务和容器化对于业务的优势,很多厂家在说,能够说到表面,说不到心里。
因而微服务和容器化的改造,更加容易发生在一个扁平化的组织里面,由一个能够体会到基层技术细节的痛的CIO,高瞻远瞩的推动这件事情。这也是为什么微服务的落地一般率先落地在互联网公司,因为互联网公司的组织架构实在太平台,哪怕是高层,也离一线非常的近,了解一线的痛。
然而在传统行业就没有那么幸运了,层级往往会比较多,这个时候就需要技术上的痛足够痛,能够痛到影响业务,能够痛到影响收入,能够痛到被竞争对手甩在后面,才能上达天听。
我们接下来就梳理一下,在这个过程中的那些痛。
阶段一:单体架构群,多个开发组,统一运维组
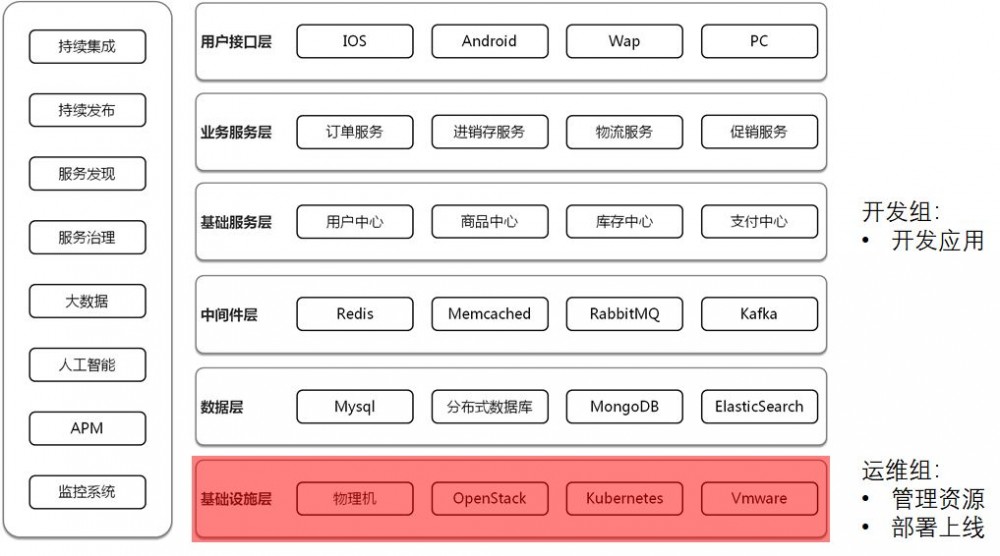
阶段一的组织状态
组织状态相对简单。
统一的运维组,管理物理机,物理网络,Vmware虚拟化等资源,同时部署上线由运维部负责。
开发组每个业务都是独立的,负责写代码,不同的业务沟通不多,开发除了做自己的系统外,还需要维护外包公司开发的系统,由于不同的外包公司技术选型差异较大,因而处于烟囱式的架构状态。
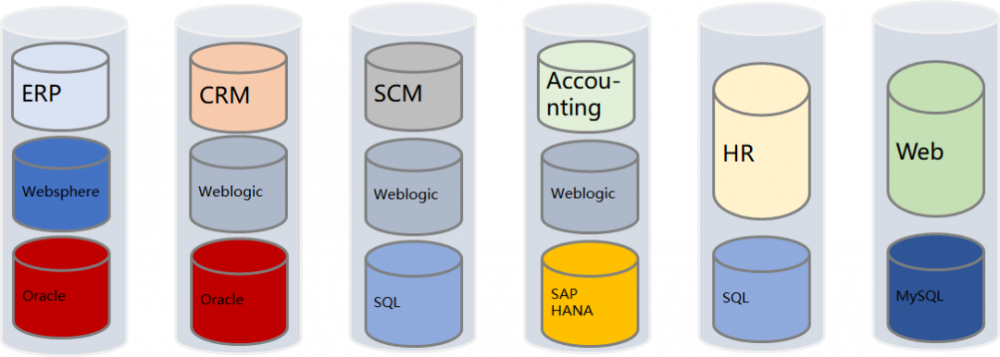
传统烟囱式架构如下图所示:
阶段一的运维模式
在传统架构下,基础设施层往往采取物理机或者虚拟化进行部署,为了不同的应用之间方便相互访问,多采取桥接扁平二层机房网络,也即所有的机器的IP地址都是可以相互访问的,不想互相访问的,多采用防火墙进行隔离。
无论是使用物理机,还是虚拟化,配置是相对复杂的,不是做过多年运维的人员,难以独立的创建一台机器,而且网络规划也需要非常小心,分配给不同业务部门的机器,网段不能冲突。所有这一切,都需要运维部门统一进行管理,一般的IT人员或者开发人员既没有专业性,也不可能给他们权限进行操作,要申请机器怎么办,走个工单,审批一下,过一段时间,机器就能创建出来。
阶段一的应用架构
传统架构数据库层,由于外包公司独立开发,或者不同开发部门独立开发,不同业务使用不同的数据库,有用Oracle的,有用SQL Server的,有用MySQL的,有用MongoDB的,各不相同。
传统架构的中间件层,每个团队独立选型中间件:
- 文件:NFS,FTP,Ceph,S3
- 缓存:Redis Cluster,主备,Sentinel,Memcached
- 分布式框架:Spring Cloud,Dubbo,Restful or RPC不同的部门自己选型
- 分库分表:Sharding-jdbc,Mycat
- 消息队列:RabbitMQ,Kafka
- 注册中心:Zk,Euraka,Consul
传统架构的服务层,系统或者由外包公司开发,或者由独立团队开发。
传统架构前端,各自开发各自的前端。
阶段一有什么问题吗?
其实阶段一没有任何问题,我们甚至能找出一万个理由说明这种模式的好处。
运维部和开放部是天然分开的,谁也不想管对方,两边的老大也是平级的,本相安无事。
机房当然只能运维人员能碰,这里面有安全的问题,专业性的问题,线上系统严肃的问题。如果交给没有那么专业的开发去部署环境,一旦系统由漏洞,谁能担责任,一旦线上系统挂了,又是谁的责任,这个问题问出来,能够让任何争论鸦雀无声。
数据库无论使用Oracle,DB2,还是SQL Server都没有问题,只要公司有足够的预算,而且性能也的确杠杠的,里面存储了大量存储过程,会使得应用开发简单很多,而且有专业的乙方帮忙运维,数据库如此关键,如果替换称为Mysql,一旦抗不出挂了,或者开源的没人维护,线上出了事情,谁来负责?
中间件,服务层,前端,全部由外包商或者乙方搞定,端到端维护,要改什么招手即来,而且每个系统都是完整的一套,部署方便,运维方便。
其实没有任何问题,这个时候上容器或者上微服务,的确自找麻烦。
什么情况下才会觉得阶段一有问题?
当然最初的痛点应该在业务层面,当用户的需求开始变的多种多样,业务方时不时的就要上一个新功能,做一个新系统的时候,你会发现外包公司不是能完全搞定所有的事情,他们是瀑布模型的开发,而且开发出来的系统很难变更,至少很难快速变更。
于是你开始想自己招聘一些开发,开发自己能够把控的系统,至少能够将外包公司开发的系统接管过来,这个时候,应对业务部门的需求,就会灵活的多。
但是自己开发和维护就带来了新的问题,多种多样的数据库,根本不可能招聘到如此多样的DBA,人都非常的贵,而且随着系统的增多,这些数据库的License也非常的贵。
多种多样的中间件,每个团队独立选型中间件,没有统一的维护,没有统一的知识积累,无法统一保障SLA。一旦使用的消息队列,缓存,框架出了问题,整个团队没有人能够搞定这个事情,因为大家都忙于业务开发,没人有时间深入的去研究这些中间件的背后原理,常见的问题,如何调优等等。
前端框架也有相同的问题,技术栈不一致,界面风格不一致,根本无法自动做UI测试。
当维护了多套系统之后,你会发现,这些系统各个层次都有很多的共同点,很多能力是可以复用的,很多数据是可以打通的。同样一套逻辑,这里也有,那里也有,同样类型的数据,这里一份,那里一份,但是信息是隔离的,数据模型不统一,根本无法打通。
当出现这些问题的时候,才是您考虑进入第二个阶段。
阶段二:组织服务化,架构SOA化,基础设施云化

阶段二的组织形态
怎么解决上面的问题呢?
根据康威定理,组织方面就需要有一定的调整,整个公司还是分运维组和开发组。
由于痛点是从业务层面发生的,开始调整的应该是开发组。
应该建立独立的前端组,统一前端框架,界面一致,所有人掌握统一的前端开发能力,积累前端代码,在有新的需求的时候,能够快速的进行开发。
建立中间件组,或者架构师组,这部分人不用贴近业务开发,每天的任务就是研究如何使用这些中间件,如何调优,遇到问题如何Debug,形成知识积累。如果有统一的一帮人专注中间件,就可以根据自身的情况,选择有限几个中间件集中研究,限定业务组只使用这些中间件,可保证选型的一致性,如果中间件被这个组统一维护,也可以提供可靠的SLA给业务方。
将业务开发组分出一部分来,建立中台组,将可以复用的能力和代码,交由这几个组开发出服务来,给业务组使用,这样数据模型会统一,业务开发的时候,首先先看看有哪些现成的服务可以使用,不用全部从零开发,也会提高开发效率。
阶段二的应用架构
要建立中台,变成服务为其他业务使用,就需要使用SOA架构,将可以复用的组件服务化,注册到服务的注册中心。
对于有钱的企业,可能会采购商用的ESB总线,也有使用Dubbo自己封装称为服务注册中心。
接下来就是要考虑,哪些应该拆出来? 最后考虑的是如何拆出来?
这两个题目的答案,不同的企业不同,其实分为两个阶段,第一个阶段是尝试阶段,也即整个公司对于服务化拆分没有任何经验,当然不敢拿核心业务上手,往往选取一个边角的业务,先拆拆看,这个时候拆本身是重要的,其实是为了拆而拆,拆的比较理想化,符合领域驱动设计的最好,如何拆呢?当然是弄一个两个月,核心员工大家闭门开发,进行拆分和组合,来积累经验。很多企业目前处于这个阶段。
但是其实这个阶段的拆法也只能用来积累经验,因为咱们最初要拆分,是为了快速响应业务请求,而这个边角的模块,往往不是最痛的核心业务。本来业务就边角,拆不拆收益不大,而且也没办法很好的做能力复用。复用当然都想复用核心能力。
所以其实最重要的是第二个阶段,业务真正的服务化的阶段。当然要拿业务需求最多的核心业务逻辑下手,才能起到快速响应业务请求,复用能力的作用。
例如考拉最初也是一个使用Oracle,对外只有一个online业务的单体应用,而真正的拆分,就是围绕核心的下单业务逻辑进行的。

那核心业务逻辑中,哪些应该拆出来呢?很多企业会问我们,其实企业自己的开发最清楚。
这个时候经常犯的错误是,先将核心业务逻辑从单体应用中拆分出来。例如将下单逻辑形成下单服务,从online服务中拆分出来。
当然不应该这样,例如两军打仗,当炊事班的烟熏着战士了,是将中军大营搬出去,还是讲炊事班搬出去呢?当然是炊事班了。
另外一点是,能够形成复用的组件,往往不是核心业务逻辑。这个很好理解,两个不同的业务,当然是核心业务逻辑不同(要不就成一种业务了),核心业务逻辑往往是组合逻辑,虽然复杂,但是往往不具备复用性,就算是下单,不同的电商也是不一样的,这家推出了什么什么豆,那家推出了什么什么券,另一家有个什么什么活动,都是核心业务逻辑的不同,会经常变。能够复用的,往往是用户中心,支付中心,仓储中心,库存中心等等核心业务的周边逻辑。
所以拆分,应该将这些核心业务的周边逻辑,从核心业务里面拆出来,最终Online就剩下下单的核心路径了,就可以改成下单服务了。当业务方突然有了需求推出一个抢购活动,就可以复用刚才的周边逻辑了。抢购就成了另一个应用的核心逻辑,其实核心逻辑是传真引线的,周边逻辑是保存数据,提供原子化接口的。
那哪些周边逻辑应该先拆出来呢?问自己的开发吧,那些战战兢兢,自己修改后生怕把核心逻辑搞挂了的组,是自己有动力从核心逻辑中拆分出来的,这个不需要技术总监和架构师去督促,他们有自己的原有动力,是一个很自然的过程。

这里的原有动力,一个是开发独立,一个是上线独立,就像考拉的online系统里面,仓库组就想自己独立出去,因为他们要对接各种各样的仓储系统,全球这么多的仓库,系统都很传统,接口不一样,没新对接一个,开发的时候,都担心把下单核心逻辑搞挂了,造成线上事故,其实仓储系统可以定义自己的重试和容灾机制,没有下单那么严重。物流组也想独立出去,因为对接的物流公司太多了,也要经常上线,也不想把下单搞挂。
您也可以梳理一下贵公司的业务逻辑,也会有自行愿意拆分的业务,形成中台服务。
当周边的逻辑拆分之后,一些核心的逻辑,互相怕影响,也可以拆分出去,例如下单和支付,支付对接多个支付方的时候,也不想影响下单,也可以独立出去。
然后我们再看,如何拆分的问题?
关于拆分的前提,时机,方法,规范等,参考文章:《 微服务化之服务拆分与服务发现 》。

首先要做的,就是原有工程代码的标准化,我们常称为“任何人接手任何一个模块都能看到熟悉的面孔”
例如打开一个Java工程,应该有以下的package:
- API接口包:所有的接口定义都在这里,对于内部的调用,也要实现接口,这样一旦要拆分出去,对于本地的接口调用,就可以变为远程的接口调用
- 访问外部服务包:如果这个进程要访问其他进程,对于外部访问的封装都在这里,对于单元测试来讲,对于这部分的Mock,可以使得不用依赖第三方,就能进行功能测试。对于服务拆分,调用其他的服务,也是在这里。
- 数据库DTO:如果要访问数据库,在这里定义原子的数据结构
- 访问数据库包:访问数据库的逻辑全部在这个包里面
- 服务与商务逻辑:这里实现主要的商业逻辑,拆分也是从这里拆分出来。
- 外部服务:对外提供服务的逻辑在这里,对于接口的提供方,要实现在这里。
另外是测试文件夹,每个类都应该有单元测试,要审核单元测试覆盖率,模块内部应该通过Mock的方法实现集成测试。
接下来是配置文件夹,配置profile,配置分为几类:
- 内部配置项(启动后不变,改变需要重启)
- 集中配置项(配置中心,可动态下发)
- 外部配置项(外部依赖,和环境相关)
当一个工程的结构非常标准化之后,接下来在原有服务中,先独立功能模块 ,规范输入输出,形成服务内部的分离。在分离出新的进程之前,先分离出新的jar,只要能够分离出新的jar,基本也就实现了松耦合。
接下来,应该新建工程,新启动一个进程,尽早的注册到注册中心,开始提供服务,这个时候,新的工程中的代码逻辑可以先没有,只是转调用原来的进程接口。
为什么要越早独立越好呢?哪怕还没实现逻辑先独立呢?因为服务拆分的过程是渐进的,伴随着新功能的开发,新需求的引入,这个时候,对于原来的接口,也会有新的需求进行修改,如果你想把业务逻辑独立出来,独立了一半,新需求来了,改旧的,改新的都不合适,新的还没独立提供服务,旧的如果改了,会造成从旧工程迁移到新工程,边迁移边改变,合并更加困难。如果尽早独立,所有的新需求都进入新的工程,所有调用方更新的时候,都改为调用新的进程,对于老进程的调用会越来越少,最终新进程将老进程全部代理。
接下来就可以将老工程中的逻辑逐渐迁移到新工程,由于代码迁移不能保证逻辑的完全正确,因而需要持续集成,灰度发布,微服务框架能够在新老接口之间切换。
最终当新工程稳定运行,并且在调用监控中,已经没有对于老工程的调用的时候,就可以将老工程下线了。
阶段二的运维模式
经过业务层的的服务化,也对运维组造成了压力。
应用逐渐拆分,服务数量增多。
在服务拆分的最佳实践中,有一条就是,拆分过程需要进行持续集成,保证功能一致。
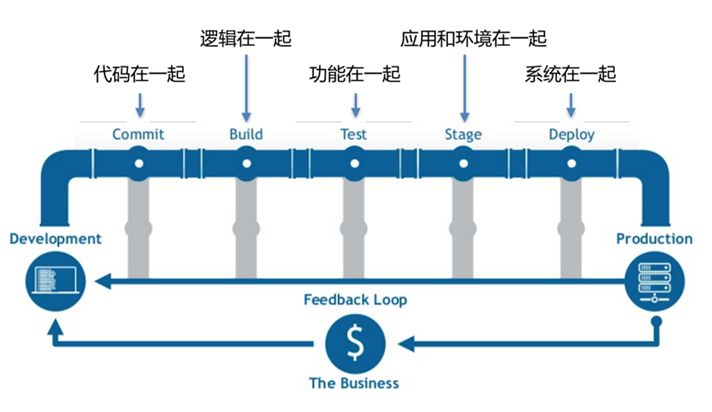
而持续集成的流程,往往需要频繁的部署测试环境。
随着服务的拆分,不同的业务开发组会接到不同的需求,并行开发功能增多,发布频繁,会造成测试环境,生产环境更加频繁的部署。
而频繁的部署,就需要频繁创建和删除虚拟机。
如果还是采用上面审批的模式,运维部就会成为瓶颈,要不就是影响开发进度,要不就是被各种部署累死。
这就需要进行运维模式的改变,也即基础设施层云化。
虚拟化到云化有什么不一样呢?
首先要有良好的租户管理,从运维集中管理到租户自助使用模式的转换。

也即人工创建,人工调度,人工配置的集中管理模式已经成为瓶颈,应该变为租户自助的管理,机器自动的调度,自动的配置。
其次,要实现基于Quota和QoS的资源控制。
也即对于租户创建的资源的控制,不用精细化到运维手动管理一切,只要给这个客户分配了租户,分配了Quota,设置了QoS,租户就可以在运维限定的范围内,自由随意的创建,使用,删除虚拟机,无需通知运维,这样迭代速度就会加快。
再次,要实现基于虚拟网络,VPC,SDN的网络规划。
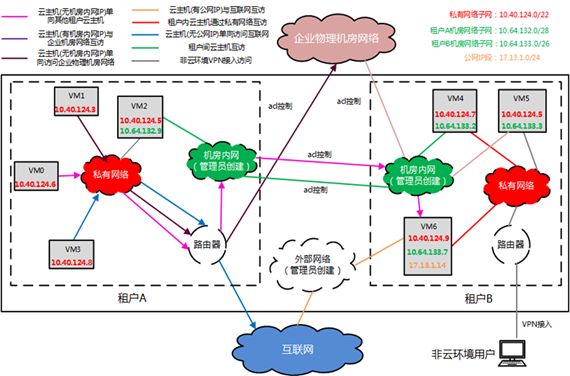
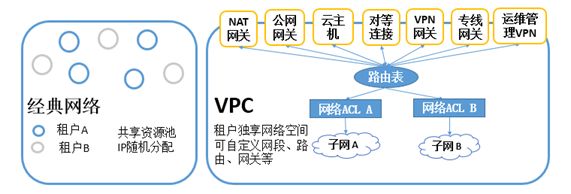
原来的网络使用的都是物理网络,问题在于物理网络是所有部门共享的,没办法交给一个业务部门自由的配置和使用。因而要有VPC虚拟网络的概念,每个租户可以随意配置自己的子网,路由表,和外网的连接等,不同的租户的网段可以冲突,互不影响,租户可以根据自己的需要,随意的在界面上,用软件的方式做网络规划。
除了基础设施云化之外,运维部门还应该将应用的部署自动化。
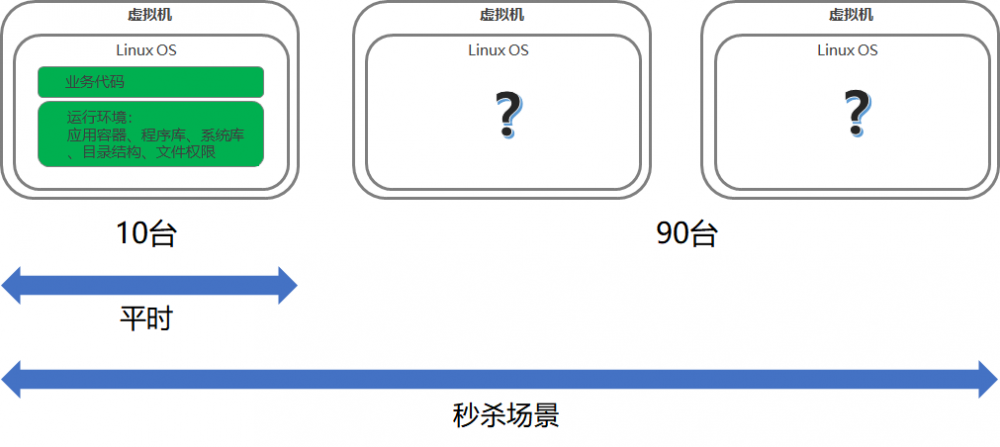
因为如果云计算不管应用,一旦出现扩容,或者自动部署的需求,云平台创建出来的虚拟机还是空的,需要运维手动上去部署,根本忙不过来。因而云平台,也一定要管理应用。
云计算如何管理应用呢?我们将应用分成两种,一种称为通用的应用,一般指一些复杂性比较高,但大家都在用的,例如数据库。几乎所有的应用都会用数据库,但数据库软件是标准的,虽然安装和维护比较复杂,但无论谁安装都是一样。这样的应用可以变成标准的PaaS层的应用放在云平台的界面上。当用户需要一个数据库时,一点就出来了,用户就可以直接用了。

所以对于运维模式的第二个改变是,通用软件PaaS化。
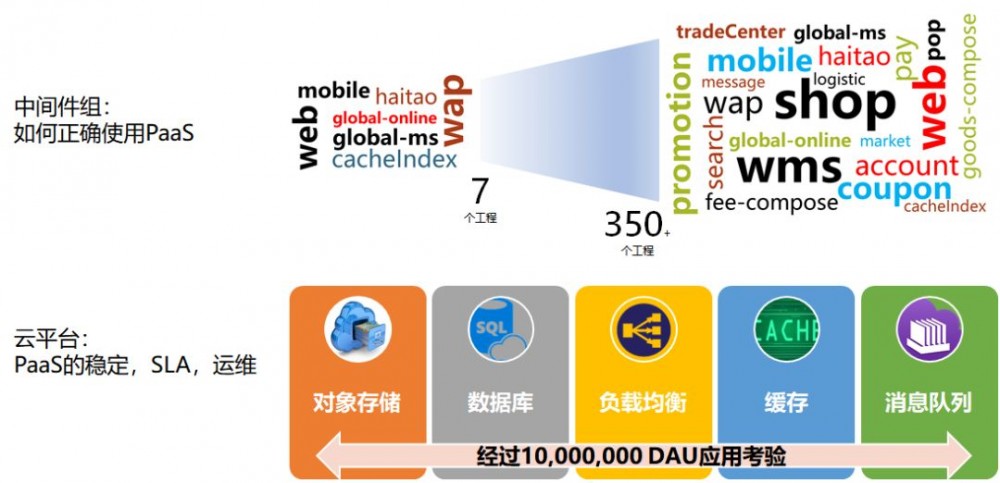
前面说过了,在开发部门有中间件组负责这些通用的应用,运维也自动部署这些应用,两个组的界限是什么样的呢?
一般的实践方式是,云平台的PaaS负责创建的中间件的稳定,保证SLA,当出现问题的时候,会自动修复。
而开发部门的中间件组,主要研究如何正确的使用这些PaaS,配置什么样的参数,使用的正确姿势等等,这个和业务相关。
除了通用的应用,还有个性化的应用,应该通过脚本进行部署,例如工具Puppet,Chef,Ansible,SaltStack等。
这里有一个实践是,不建议使用裸机部署,因为这样部署非常的慢,推荐基于虚拟机镜像的自动部署。在云平台上,任何虚拟机的创建都是基于镜像的,我们可以在镜像里面,将要部署的环境大部分部署好,只需要做少量的定制化,这些由部署工具完成。
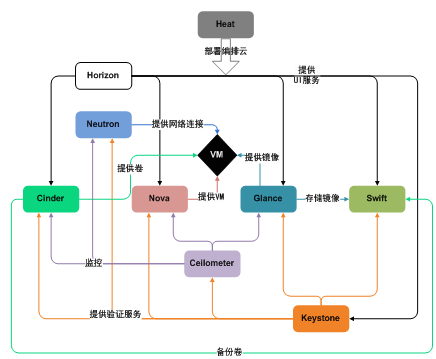
下图是OpenStack基于Heat的虚拟机编排,除了调用OpenStack API基于镜像创建虚拟机之外,还要调用SaltStack的master,将定制化的指令下发给虚拟机里面的agent。
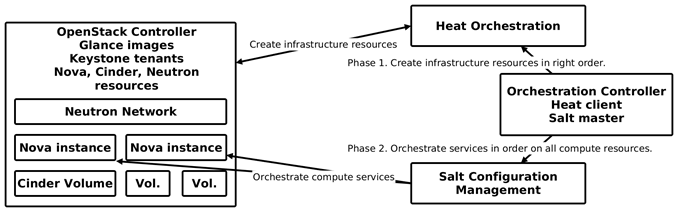
基于虚拟机镜像和脚本下发,可以构建自动化部署平台NDP。
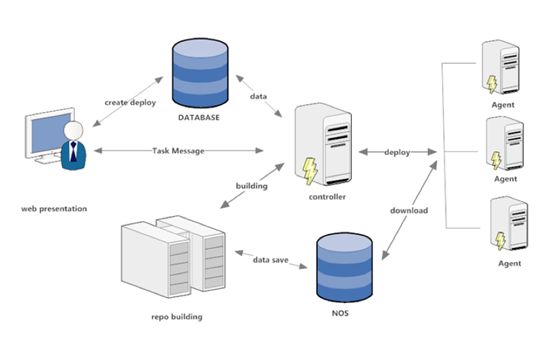
这样可以基于虚拟机镜像,做完整的应用的部署和上线,称为编排。基于编排,就可以进行很好的持续集成,例如每天晚上,自动部署一套环境,进行回归测试,从而保证修改的正确性。
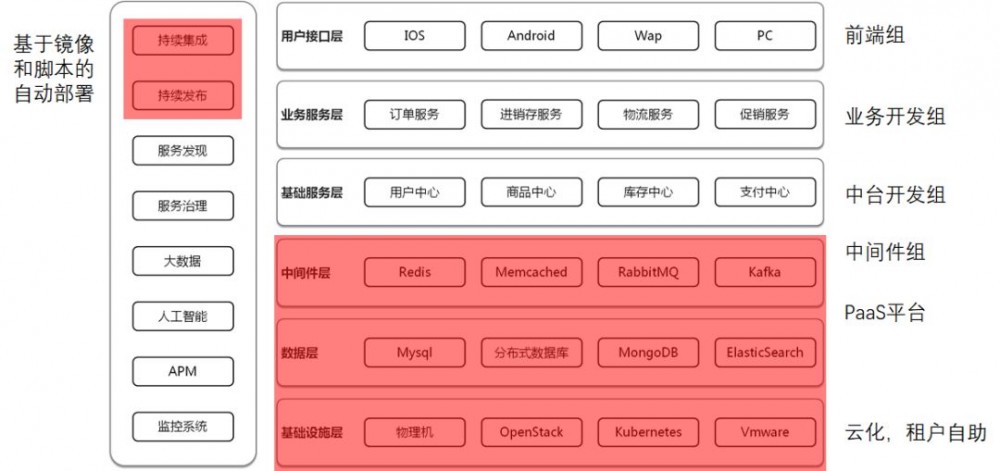
进行完第二阶段之后,整个状态如上图所示。
这里运维部门的职能有了一定的改变,除了最基本的资源创建,还要提供自助的操作平台,PaaS化的中间件,基于镜像和脚本的自动部署。
开发部门的职能也有了一定的改变,拆分称为前端组,业务开发组,中台组,中间件组,其中中间件组合运维部门的联系最紧密。
阶段二有什么问题吗?
其实大部分的企业,到了这个阶段,已经可以解决大部分的问题了。
能够做到架构SOA化,基础设施云化的公司已经是传统行业在信息化领域的佼佼者了。
中台开发组基本能够解决中台的能力复用问题,持续集成也基本跑起来了,使得业务开发组的迭代速度明显加快。
集中的中间件组或者架构组,可以集中选型,维护,研究消息队列,缓存等中间件。
在这个阶段,由于业务的稳定性要求,很多公司还是会采用Oracle商用数据库,也没有什么问题。
实现到了阶段二,在同行业内,已经有一定的竞争优势了。
什么情况下才会觉得阶段二有问题?
我们发现,当传统行业不再满足于在本行业的领先地位,希望能够对接到互联网业务的时候,上面的模式才出现新的痛点。
对接互联网所面临的最大的问题,就是巨大的用户量所带来的请求量和数据量,会是原来的N倍,能不能撑得住,大家都心里没底。
例如有的客户推出互联网理财秒杀抢购,原来的架构无法承载近百倍的瞬间流量。
有的客户对接了互联网支付,甚至对接了国内最大的外卖平台,而原来的ESB总线,就算扩容到最大规模(13个节点),也可能撑不住。
有的客户虽然已经用了Dubbo实现了服务化,但是没有熔断,限流,降级的服务治理策略,有可能一个请求慢,高峰期波及一大片,或者请求全部接进来,最后都撑不住而挂一片。
有的客户希望实现工业互连网平台,可是接入的数据量动辄PB级别,如果扛的住是一个很大的问题。
有的客户起初使用开源的缓存和消息队列,分布式数据库,但是读写频率到了一定的程度,就会出现各种奇奇怪怪的问题,不知道应该如何调优。
有的客户发现,一旦到了互联网大促级别,Oracle数据库是肯定扛不住的,需要从Oracle迁移到DDB分布式数据库,可是怎么个迁移法,如何平滑过渡,心里没底。
有的客户服务拆分之后,原来原子化的操作分成了两个服务调用,如何仍然保持原子化,要不全部成功,要不全部失败,需要分布式事务,虽然业内有大量的分布式方案,但是能够承载高并发支付的框架还没有。
当出现这些问题的时候,才应该考虑进入第三个阶段,微服务化。
阶段三:组织DevOps化,架构微服务化,基础设施容器化

阶段三的应用架构
从SOA到微服务化这一步非常关键,复杂度也比较高,上手需要谨慎。
为了能够承载互联网高并发,业务往往需要拆分的粒度非常的细,细到什么程度呢?我们来看下面的图。

在这些知名的使用微服务的互联网公司中,微服务之间的相互调用已经密密麻麻相互关联成为一个网状,几乎都看不出条理来。
为什么要拆分到这个粒度呢?主要是高并发的需求。
但是高并发不是没有成本的,拆分成这个粒度会有什么问题呢?你会发现等拆完了,下面的这些措施一个都不能少。
- 拆分如何保证功能不变,不引入Bug——持续集成,参考:《 微服务化的基石——持续集成 》。
- 静态资源要拆分出来,缓存到接入层或者CDN,将大部分流量拦截在离用户近的边缘节点或者接入层缓存,参考:《 微服务的接入层设计与动静资源隔离 》。
- 应用的状态要从业务逻辑中拆分出来,使得业务无状态,可以基于容器进行横向扩展,参考:《 微服务化之无状态化与容器化 》。
- 核心业务和非核心业务要拆分,方便核心业务的扩展以及非核心业务的降级,参考:《 微服务化之服务拆分与服务发现 》。
- 数据库要读写分离,要分库分表,才能在超大数据量的情况下,数据库具有横向扩展的能力,不成为瓶颈,参考:《 微服务化的数据库设计与读写分离 》
- 要层层缓存,只有少数的流量到达中军大营数据库,参考:《微服务化之缓存的设计》。
- 要使用消息队列,将原来连续调用的多个服务异步化为监听消息队列,从而缩短核心逻辑。
- 服务之间要设定熔断,限流,降级策略,一旦调用阻塞应该快速失败,而不应该卡在那里,处于亚健康状态的服务要被及时熔断,不产生连锁反应。非核心业务要进行降级,不再调用,将资源留给核心业务。要在压测到的容量范围内对调用限流,宁可慢慢处理,也不用一下子都放进来,把整个系统冲垮。
- 拆分成的服务太多了,没办法一个个配置,需要统一的一个配置中心,将配置下发。
- 拆分成的服务太多了,没办法一个个看日志,需要统一的日志中心,将日志汇总。
- 拆分成的服务太多了,很难定位性能瓶颈,需要通过APM全链路应用监控,发现性能瓶颈,及时修改。
- 拆分成的服务太多了,不压测一下,谁也不知道到底能够抗住多大的量,因而需要全链路的压测系统。
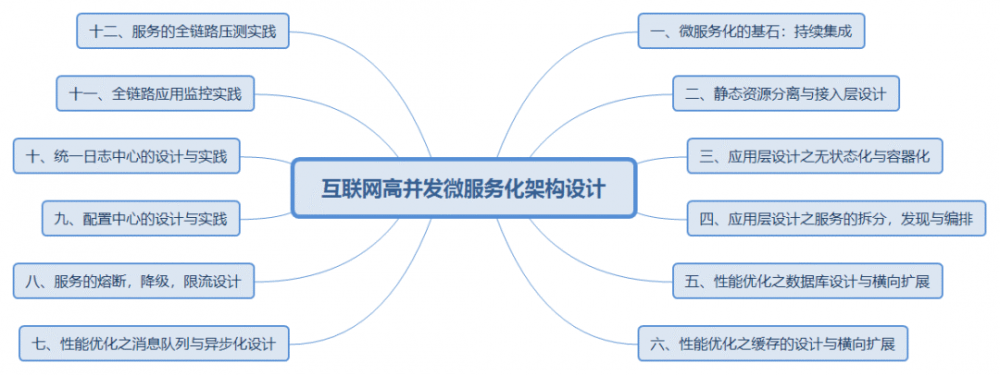
应用层需要处理这十二个问题,最后一个都不能少,实施微服务,你做好准备了吗?你真觉得攒一攒Spring Cloud,就能够做好这些吗?
阶段三的运维模式
业务的微服务化改造之后,对于运维的模式是有冲击的。

如果业务拆成了如此网状的细粒度,服务的数目就会非常的多,每个服务都会独立发布,独立上线,因而版本也非常多。
这样环境就会非常的多,手工部署已经不可能,必须实施自动部署。好在在上一个阶段,我们已经实施了自动部署,或者基于脚本的,或者基于镜像的,但是到了微服务阶段都有问题。
如果基于脚本的部署,脚本原来多由运维写,由于服务太多,变化也多,脚本肯定要不断的更新,而每家公司的开发人员都远远多于运维人员,运维根本来不及维护自动部署的脚本。那脚本能不能由开发写呢?一般是不可行的,开发对于运行环境了解有限,而且脚本没有一个标准,运维无法把控开发写的脚本的质量。
基于虚拟机镜像的就会好很多,因为需要脚本做的事情比较少,大部分对于应用的配置都打在镜像里面了。如果基于虚拟机镜像进行交付,也能起到标准交付的效果。而且一旦上线有问题,也可以基于虚拟机镜像的版本进行回滚。
但是虚拟机镜像实在是太大了,动不动几百个G,如果一共一百个服务,每个服务每天一个版本,一天就是10000G,这个存储容量,谁也受不了。
这个时候,容器就有作用了。镜像是容器的根本性发明,是封装和运行的标准,其他什么namespace,cgroup,早就有了。
原来开发交付给运维的,是一个war包,一系列配置文件,一个部署文档,但是由于部署文档更新不及时,常常出现运维部署出来出错的情况。有了容器镜像,开发交付给运维的,是一个容器镜像,容器内部的运行环境,应该体现在Dockerfile文件中,这个文件是应该开发写的。
这个时候,从流程角度,将环境配置这件事情,往前推了,推到了开发这里,要求开发完毕之后,就需要考虑环境部署的问题,而不能当甩手掌柜。由于容器镜像是标准的,就不存在脚本无法标准化的问题,一旦单个容器运行不起来,肯定是Dockerfile的问题。
而运维组只要维护容器平台就可以,单个容器内的环境,交给开发来维护。这样做的好处就是,虽然进程多,配置变化多,更新频繁,但是对于某个模块的开发团队来讲,这个量是很小的,因为5-10个人专门维护这个模块的配置和更新,不容易出错。自己改的东西自己知道。
如果这些工作量全交给少数的运维团队,不但信息传递会使得环境配置不一致,部署量会大非常多。
容器作用之一就是环境交付提前,让每个开发仅仅多做5%的工作,就能够节约运维200%的工作,并且不容易出错。
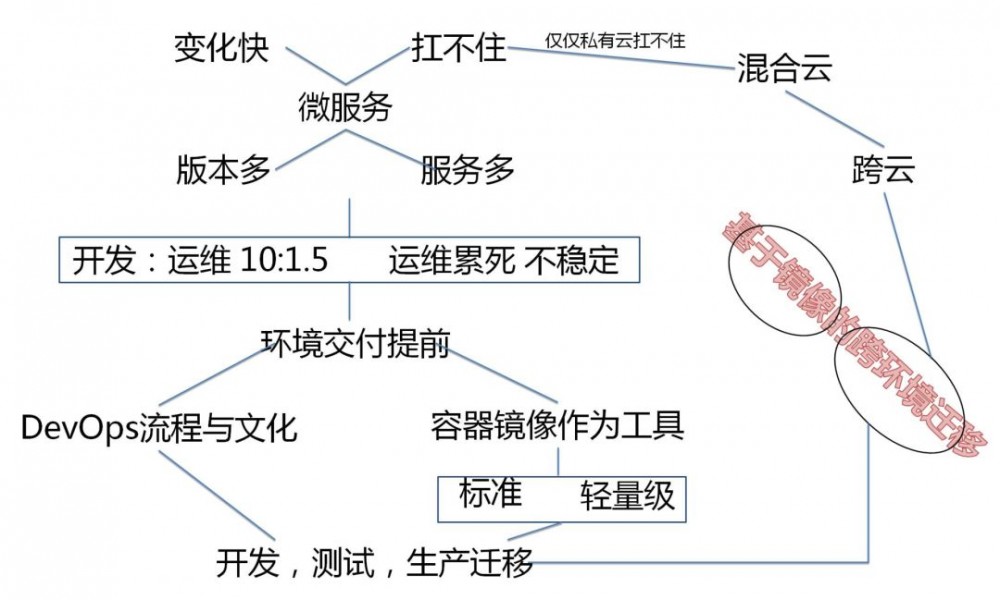
容器的另外一个作用,就是不可改变基础设施。
容器镜像有个特点,就是SSH到里面做的任何修改,重启都不见了,恢复到镜像原来的样子,也就杜绝了原来我们部署环境,这改改,那修修最后部署成功的坏毛病。
因为如果机器数目比较少,还可以登录到每台机器上改改东西,一旦出了错误,比较好排查,但是微服务状态下,环境如此复杂,规模如此大,一旦有个节点,因为人为修改配置导致错误,非常难排查,所以应该贯彻不可改变基础设施,一旦部署了,就不要手动调整了,想调整从头走发布流程。
这里面还有一个概念叫做一切即代码,单个容器的运行环境Dockerfile是代码,容器之间的关系编排文件是代码,配置文件是代码,所有的都是代码,代码的好处就是谁改了什么,Git里面一清二楚,都可以track,有的配置错了,可以统一发现谁改的。
阶段三的组织形态
到了微服务阶段,实施容器化之后,你会发现,然而本来原来运维该做的事情开发做了,开发的老大愿意么?开发的老大会投诉运维的老大么?
这就不是技术问题了,其实这就是DevOps,DevOps不是不区分开发和运维,而是公司从组织到流程,能够打通,看如何合作,边界如何划分,对系统的稳定性更有好处。
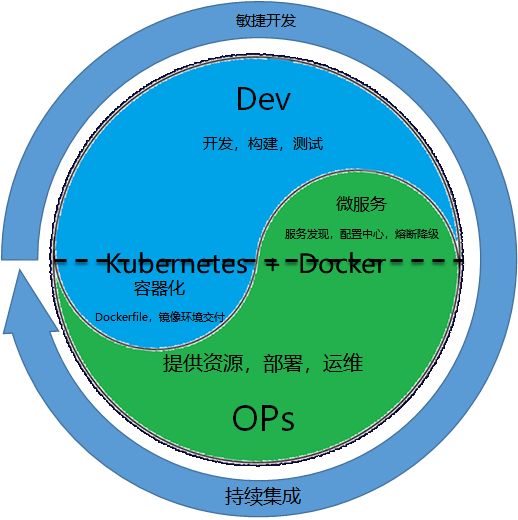
其实开发和运维变成了一个融合的过程,开发会帮运维做一些事情,例如环境交付的提前,Dockerfile的书写。
运维也可以帮助研发做一些事情,例如微服务之间的注册发现,治理,配置等,不可能公司的每一个业务都单独的一套框架,可以下沉到运维组来变成统一的基础设施,提供统一的管理。
实施容器,微服务,DevOps后,整个分工界面就变成了下面的样子。
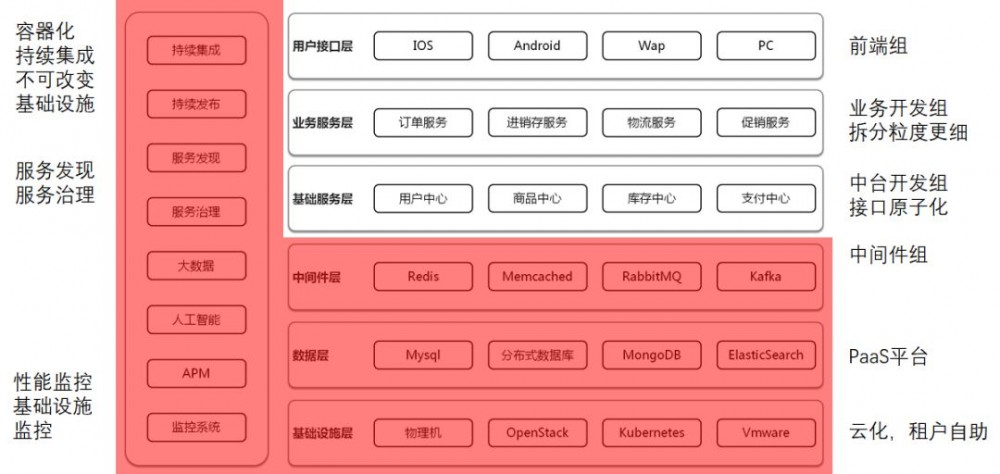
在网易就是这个模式,杭州研究院作为公共技术服务部门,有运维部门管理机房,上面是云平台组,基于OpenStack开发了租户可自助操作的云平台。PaaS组件也是云平台的一部分,点击可得,提供SLA保障。容器平台也是云平台的一部分,并且基于容器提供持续集成,持续部署的工具链。
微服务的管理和治理也是云平台的一部分,业务部门可以使用这个平台进行微服务的开发。
业务部门的中间件组或者架构组合云平台组沟通密切,主要是如何以正确的姿势使用云平台组件。
业务部门分前端组,业务开发组,中台开发组。
如何实施微服务,容器化,DevOps
实施微服务,容器化,DevOps有很多的技术选型。
其中容器化的部分,Kubernetes当之无愧的选择。但是Kubernetes可不仅仅志在容器,他是为微服务而设计的。对于实施微服务各方面都有涉及。
详细分析参考:《 为什么Kubernetes天然适合微服务 》。
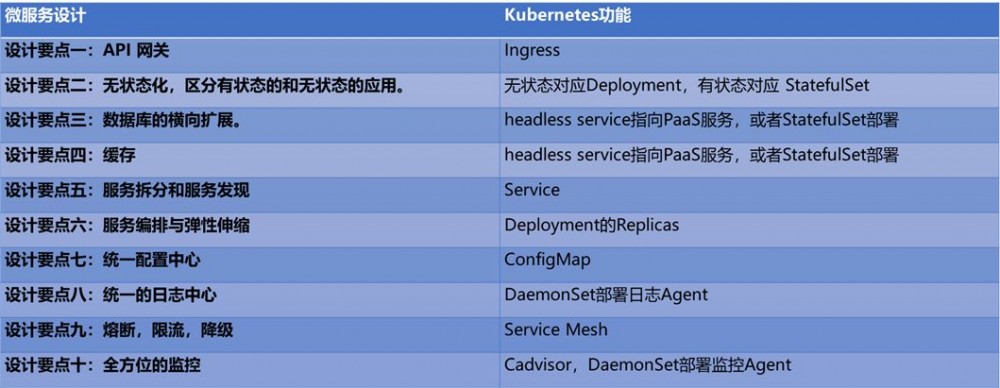
但是Kubernetes对于容器的运行时生命周期管理比较完善,但是对于服务治理方面还不够强大。
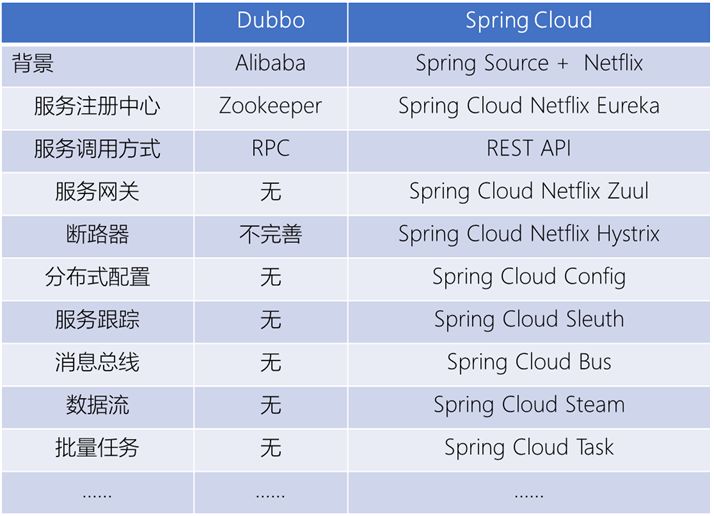
因而对于微服务的治理方面,多选择使用Dubbo或者Spring Cloud。使用Dubbo的存量应用比较多,相对于Dubbo来讲,Spring Cloud比较新,组件也比较丰富。但是Spring Cloud的组件都不到开箱即用的程度,需要比较高的学习曲线。
因而基于Kubernetes和Spring Cloud,就有了下面这个微服务,容器,DevOps的综合管理平台。包含基于Kubernetes的容器平台,持续集成平台,测试平台,API网关,微服务框架,APM应用性能管理。
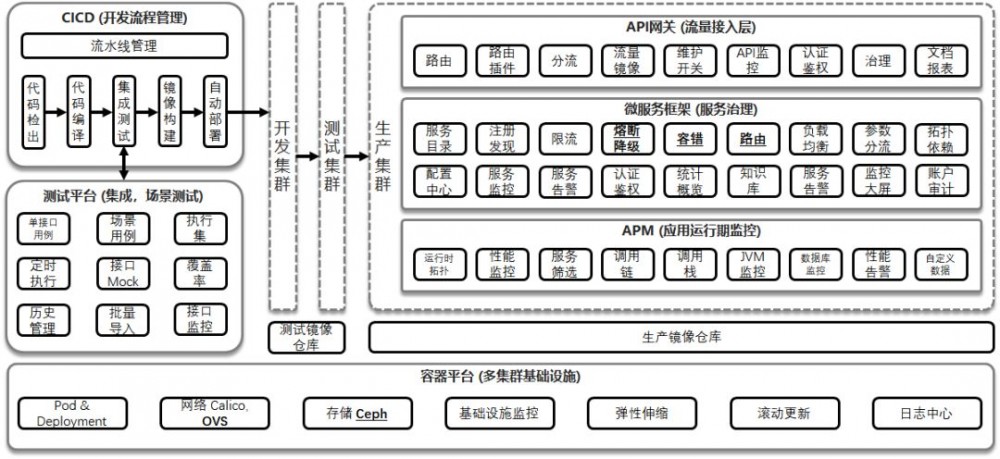
主要为了解决从阶段一到阶段二,或者阶段二到阶段三的改进中的痛点。
下面我们列举几个场景。
场景一:架构SOA拆分时,如何保证回归测试功能集不变
前面说过,服务拆分后,最怕的是拆完了引入一大堆的Bug,通过理智肯定不能保证拆分后功能集是不变的,因而需要有回归测试集合保证,只要测试集合通过了,功能就没有太大的问题。
回归测试最好是基于接口的,因为基于UI的很危险,有的接口是有的,但是UI上不能点,这个接口如果有Bug,就被暂时隐藏掉了,当后面有了新的需求,当开发发现有个接口能够调用的时候,一调用就挂了。
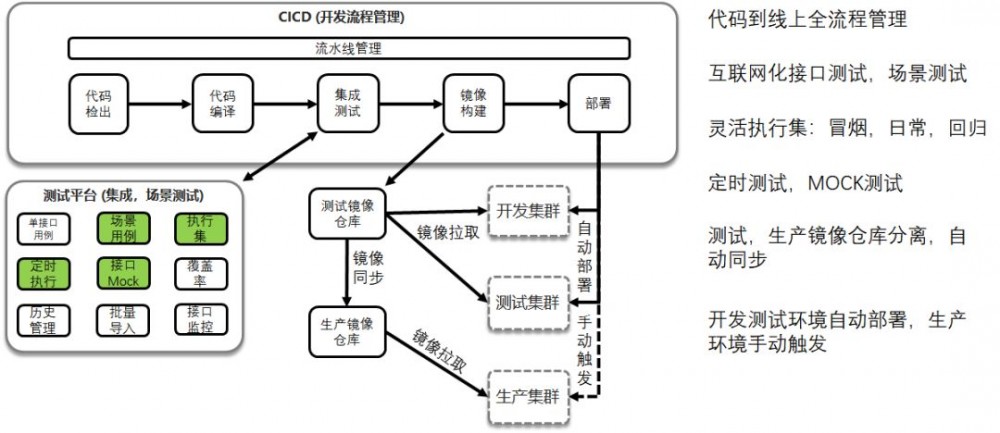
有了基于Restful API的接口测试之后,可以组成场景测试,将多个API调用组合成为一个场景,例如下单,扣优惠券,减库存,就是一个组合场景。
另外可以形成测试集合,例如冒烟测试集合,当开发将功能交付给测试的时候,执行一下。再如日常测试集合,每天晚上跑一遍,看看当天提交的代码有没有引入新的Bug。再如回归测试集合,上线之前跑一遍,保证大部分的功能是正确的。
场景二:架构SOA化的时候,如何统一管理并提供中台服务
当业务要提供中台服务的时候,中台服务首先希望能够注册到一个地方,当业务组开发业务逻辑的时候,能够在这个地方找到中台的接口如何调用的文档,当业务组的业务注册上来的时候,可以进行调用。
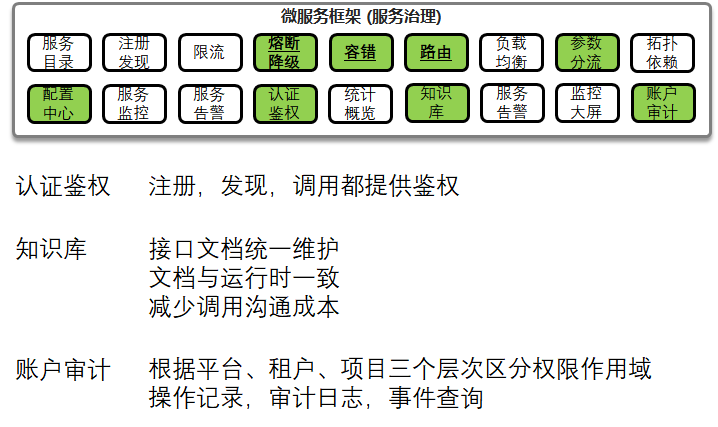
在微服务框架普通的注册发现功能之外,还提供知识库的功能,使得接口和文档统一维护,文档和运行时一致,从而调用方看着文档就可以进行调用。
另外提供注册,发现,调用期间的鉴权功能,不是谁看到中台服务都能调用,需要中台管理员授权才可以。
为了防止中台服务被恶意调用,提供账户审计功能,记录操作。
场景三:服务SOA化的时候,如何保证关键服务的调用安全
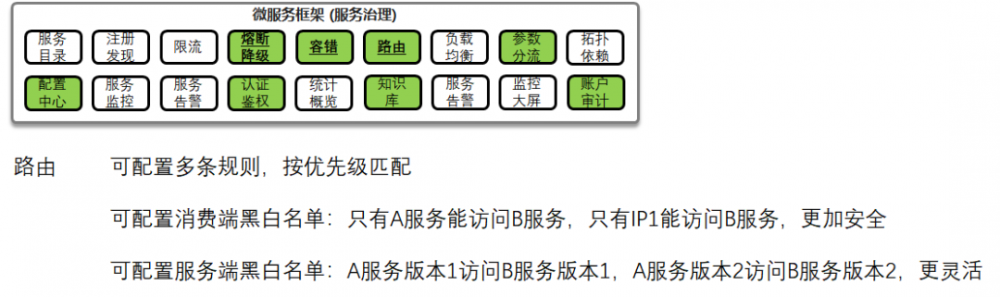
有的服务非常关键,例如支付服务,和资金相关,不是谁想调用就能调用的,一旦被非法调用了,后果严重。
在服务治理里面有路由功能,除了能够配置灵活的路由功能之外,还可以配置黑白名单,可以基于IP地址,也可以基于服务名称,配置只有哪些应用可以调用,可以配合云平台的VPC功能,限制调用方。
场景四:架构SOA化后,对外提供API服务,构建开放平台
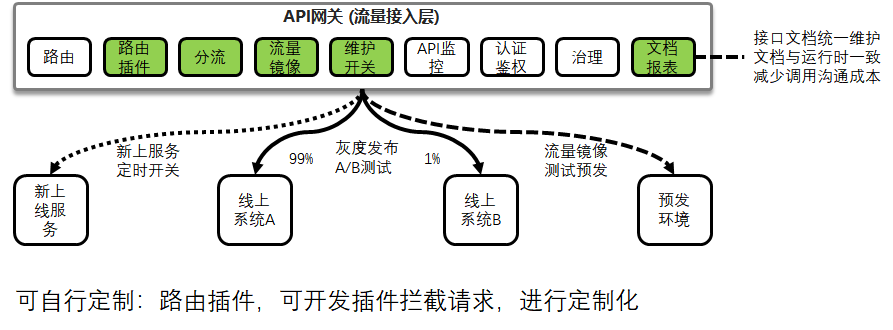
架构SOA化之后,除了对内提供中台服务,很多能力也可以开放给外部的合作伙伴,形成开放平台。例如你是一家物流企业,除了在你的页面上下单寄快递之外,其他的电商也可以调用你的API来寄快递,这就需要有一个API网关来管理API,对接你的电商只要登录到这个API网关,就能看到API以及如何调用,API网关上面的文档管理就是这个作用。
另外API网关提供接口的统一认证鉴权,也提供API接口的定时开关功能,灵活控制API的生命周期。
场景五:互联网场景下的灰度发布和A/B测试
接下来我们切换到互联网业务场景,经常会做A/B测试,这就需要API网关的流量分发功能。
例如我们做互联网业务,当上一个新功能的 时候,不清楚客户是否喜欢,于是可以先开放给山东的客户,当HTTP头里面有来自山东的字段,则访问B系统,其他客户还是访问A系统,这个时候可以看山东的客户是否都喜欢,如果都喜欢,就推向全国,如果不喜欢,就撤下来。
场景六:互联网场景下的预发测试
这个也是互联网场景下经常遇到的预发测试,虽然我们在测试环境里面测试了很多轮,但是由于线上场景更加复杂,有时候需要使用线上真实数据进行测试,这个时候可以在线上的正式环境旁边部署一套预发环境,使用API网关将真实的请求流量,镜像一部分到预发环境,如果预发环境能够正确处理真实流量,再上线就放心多了。
场景七:互联网场景下的性能压测
互联网场景下要做线上真实的性能压测,才能知道整个系统真正的瓶颈点。但是性能压测的数据不能进真实的数据库,因而需要进入影子库,性能压测的流量,也需要有特殊的标记放在HTTP头里面,让经过的业务系统知道这是压测数据,不进入真实的数据库。
这个特殊的标记要在API网关上添加,但是由于不同的压测系统要求不一样,因而需要API网关有定制路由插件功能,可以随意添加自己的字段到HTTP头里面,和压测系统配合。
场景八:微服务场景下的熔断,限流,降级
微服务场景下,大促的时候,需要进行熔断,限流,降级。这个在API网关上可以做,将超过压测值的流量,通过限流,拦在系统外面,从而保证尽量的流量,能够下单成功。
在服务之间,也可以通过微服务框架,进行熔断,限流,降级。Dubbo对于服务的控制在接口层面,Spring Cloud对于服务的管理在实例层面,这两个粒度不同的客户选择不一样,都用Dubbo粒度太细,都用Spring Cloud粒度太粗,所以需要可以灵活配置。
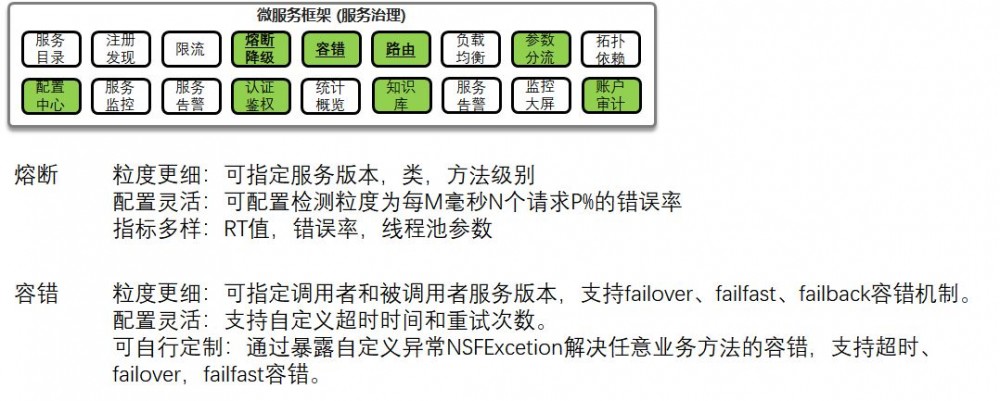
场景九:微服务场景下的精细化流量管理
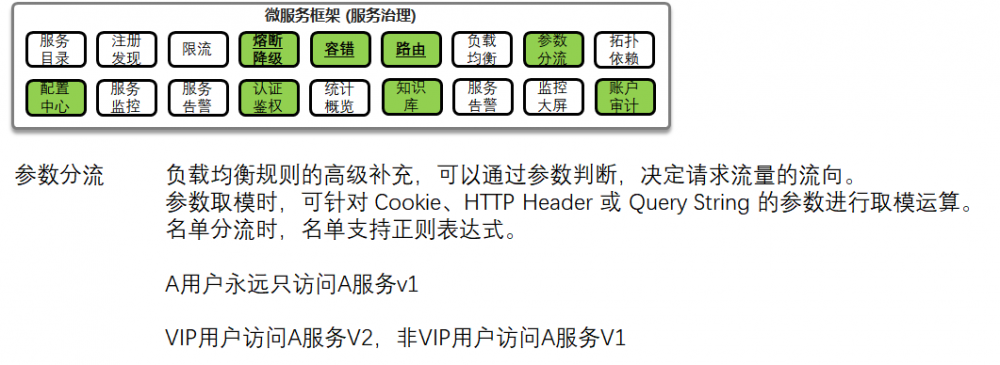
在互联网场景下,经常需要对于流量进行精细化的管理,可以根据HTTP Header里面的参数进行分流,例如VIP用户访问一个服务,非VIP用户访问另一个服务,这样可以对高收入的用户推荐更加精品的产品,增加连带率。
原文链接: 致传统企业朋友:不够痛就别微服务,有坑 (来源:刘超的通俗云计算)
正文到此结束
- 本文标签: Sentinel 自动化 架构师 nfs 开关功能 资金 数据 API MongoDB REST SQL Server 生命 IO rabbitmq spring db consul 微服务 互联网 UI SOA Kubernetes 软件 dubbo 删除 cache 高并发 云 mongo 服务注册 CDN 限流 压力 配置 RESTful 时间 插件 http 业务层 分布式 虚拟化 Dockerfile db2 注册中心 https 单元测试 进程 安装 管理 需求 组织 开源 src 用户中心 应用架构 mysql bug 认证 配置中心 git 测试环境 数据库 sql 大数据 代码 分布式事务 锁 ftp 招聘 Master 做自己 测试 Spring cloud ip Agent Oracle 安全 漏洞 IT人 消息队列 开发 详细分析 文章 希望 专注 定制 sharding VMware 缓存 理财 并发 cat PaaS OpenStack Docker 参数 企业 数据模型 IO层 一致性 ssh 灰度发布 质量 JDBC 事故 覆盖率 产品 redis SDN 实例 最大规模 Uber ACE MQ 模型 java
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

