【译】Java引用对象
在写了15年C/C++之后,我于1999年开始写Java。借助指针切换(pointer handoffs)等编码实践或者Purify等工具,我认为自己对C风格的内存管理已经得心应手了,甚至已经不记得上次发生内存泄露是什么时候了。所以起初我接触到Java的自动内存管理时有些不屑,但很快就爱上它了。在我不需要再管理内存后我才意识到之前耗费了多少精力。
接着我就遇到了第一个 OutOfMemoryError 。当时我就坐在那面对着控制台,没有堆栈,因为堆栈也需要内存。调试这个错误很困难,因为常用的工具都不能用了,甚至 malloc logger 都没有,而且1999年的时候Java的调试器还很原始。
我不记得当时是什么原因导致的错误了,但我肯定当时没有用引用对象解决它。引用对象是在一年后我写服务端数据库缓存,尝试用软引用来限制缓存大小时才进入我的“工具箱”的。结果证明它们在这种场景下用处不大,我下面会解释原因。但当引用类型才进入我的“工具箱”后,我发现了很多其他用途,并且对JVM也有了更好的理解。
Java堆和对象生命周期
对于刚接触Java的C++程序员来说,栈和队之间的关系很难理解。在C++中,对象可以通过 new 操作在堆上创建,也可以通过“自动”分配在栈上创建。下面这种在C++中是合法的,会在栈上创建一个新的 Integer 对象,但对于Java编译器来说这有语法错误。
Integer foo = Integer(1);
不同于C++,Java的所有对象都在堆保存,要求用 new 操作来创建对象。局部变量仍然储存在栈中,但它们持有这个对象的指针而不是这个对象本身(更让C++程序员困惑的是这些指针被叫做“引用”)。下面这个Java方法,有一个 Integer 变量引用一个从 String 解析而来的值:
public static void foo(String bar)
{
Integer baz = new Integer(bar);
}
下图显示了这个方法相应的堆和栈之间的关系。栈被分割为栈帧,用于保存调用树中各个方法的参数和局部变量。这些变量指向对象–这个例子中的参数 bar 和局部变量 baz –指23
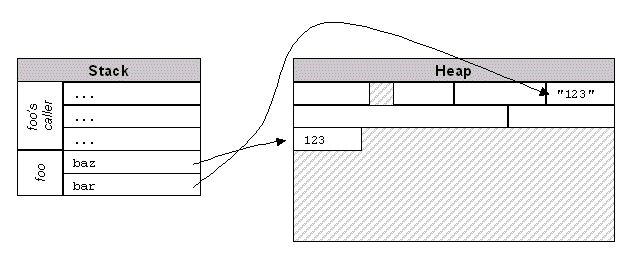
现在仔细看看 foo() 的第一行,创建了一个 Integer 对象。这种情况下,JVM会先试图去为这个对象找足够的堆空间–在32位JVM上大约12 bytes,如果可以分配出空间,就调用 Integer 的构造函数, Integer 的构造函数会解析传入的String然后初始化这个新创建的对象。最后,JVM在变量 baz 中保存一个指向该对象的指针。
这是理想的道路,还有一些不那么美好的道路,其中我们关心的是当 new 操作不能为这个对象找到12 bytes的情况。在这种情况下,JVM会在放弃并抛出 OutOfMemoryError 之前调用垃圾回收器尝试腾出空间。
垃圾回收
虽然Java给了你 new 操作来在堆上分配对象,但是没有给你对应的 delete 操作来移除它们。当方法 foo() 返回,变量 baz 离开了作用域,但是它指向的对象依然存在于堆中。如果只是这样的话,那所有的程序都会很快耗尽内存。Java提供了垃圾回收器来清理那些不再被引用的对象。
垃圾回收器会在程序尝试创建一个新对象但堆没有足够的空间时工作。回收器在堆上寻找那些不再被程序使用的对象并回收它们的空间时,请求创建对象的线程会暂停。如果回收器无法腾出足够的空间,并且JVM无法扩展堆, new 操作就会失败并抛出 OutOfMemoryError ,通常接下来你的应用会停止。
标记-清除
其中一个关于垃圾回收器的误区是,很多人认为JVM为每个对象保存了一个引用计数,回收器只会回收那些引用计数为0的对象。事实上,JVM使用被称为“标记-清除”的技术。标记-清除算法的思路很简单:所有不能被程序访问到的对象都是垃圾,都可以被收集。
标记-清除算法有以下阶段:
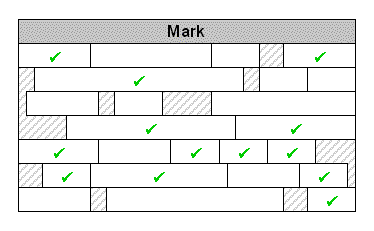
阶段一:标记
垃圾回收器从“root”引用开始,标记所有可以到达的对象。
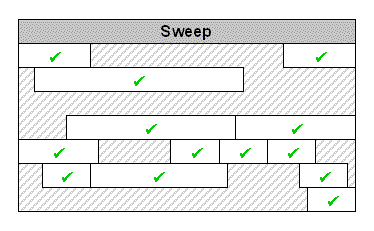
阶段二:清除
在第一阶段没有被标记的都是不可到达的,也就是垃圾。如果垃圾对象定义了 finalizer ,它会被加到 finalization 队列(后文详细讨论)。否则,它占用的空间就可以被重新分配使用(具体的情况视GC的实现而定,有很多种实现)。
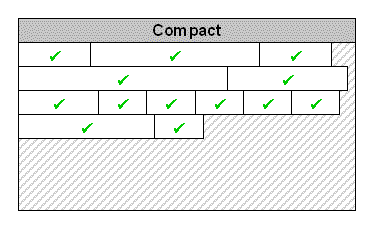
阶段三:压缩(可选)
一些回收器有第三步——压缩。在这一步,GC会移动对象使回收的对象留下的空闲空间合并,这可以防止堆变得碎片化,避免大块相邻内存分配的失败。
例如,Hotspot JVM,在新生代使用会压缩的回收器,而在老年代使用非压缩的回收器(至少在1.6和1.7的“server” JVM是这样)。想了解更多信息,可以看本文后面的参考文献。
那么什么是“roots”呢?在一个简单的Java应用中,它们是方法参数和局部变量(保存在栈中)、当前执行的表达式操作的对象(也保存在栈中)、静态类成员变量。
对于使用自己classloader的程序,例如应用服务器,情况复杂一些:只有被 system classloader (JVM启动时使用这个loader)加载的类包含root引用。那些被应用创建的classloader一旦没有其他引用也会被回收。这是应用服务器可以热部署的原因:它们为每个部署的应用创建独立的classloader,当应用下线或重新部署时释放classloader引用。
理解root引用很重要,因为这定义了“强引用”,即如果可以从root沿着引用链到达某个对象,那么这个对象就被“强引用”了,则不会被回收。
回到 foo() 方法,参数 bar 和局部变量 baz 使用当方法执行时才是强引用,一旦方法结束,它们都超出了作用域,被他们引用的对象就可以回收。另一种可能是, foo() 返回一个它创建的Integer引用,这意味着这个对象会被调用 foo() 的那个方法保持强引用。
看下面这个例子:
LinkedList foo = new LinkedList(); foo.add(new Integer(123));
变量 foo 是一个指向LinkedList对象的root引用,列表中有0个或多个元素,都指向其对象。当我们调用 add() 时,向列表中添加了一个指向值为123的Integer实例的元素,这是一个强引用,意味着这个Integer实例不会被回收。一旦 foo 超出了作用域,这个LinkedList和它里面的一切都可以被回收,当前前提是没有其他强引用指向它了。
你也许想知道循环引用会发生什么,即对象A包含一个对象B的引用,同时对象B也包含对象A的引用。答案是标记-清除回收器并不傻,如果A和B都无法由强引用链到达,那么它们都可以被回收。
Finalizers
C++允许对象定义析构方法,当对象离开作用域或者被明确删除时,它的析构函数会被调用来清理它使用的资源,对大多数对象来说即释放通过 new 或 malloc 分配的内存。在Java中,垃圾回收器会为你处理内存清理,所以不需要明确的析构函数来做这些。
然而,内存并不是唯一可能需要被清理的资源。例如 FileOutputStream ,当创建这个对象的实例时,会从操作系统分配一个文件操作符(文件句柄),如果你在关闭流之前让它的所有引用都离开作用域了,这个文件操作符会发生什么呢?答案是流有 finalizer ,这个方法会在垃圾回收器回收对象前被JVM调用。这个例子中的 FileOutputStream 在 finalizer 方法中会关闭流,这样就会将文件操作符返回给操作系统,同时也会刷新缓存,确保所有数据被正确地写到磁盘。
任何对象都可以有 finalizer ,你只需要定义 finalize() 方法即可:
protected void finalize() throws Throwable
{
// 在这里释放你的对象
}
finalizers 看上去是一个由你自己清理的简单方式,但实际上有严重的限制。首先,你永远也不要依赖它做重要的事,因为对象的 finalizers 可能不会被调用,应用可能在对象被回收之前就结束了。 finalizers 还有一些更微妙的问题,我会在虚引用时讨论。
对象的生命周期(无引用对象)
总结起来,对象的一生可以用下面的图总结:被创建、被使用、可回收、最终被回收。阴影部分表示对象是“强可达”的时期,这是与引用对象规定的可达性比较而言很重要的时期。

进入引用对象的世界
JDK 1.2引入了 java.lang.ref 包,对象的生命周期增加了3种阶段:软可达、弱可达、虚可达。这些阶段只用来可否被回收,换言之,那些不是强引用的对象,必须是其中一种引用对象的被引用者:
-
软可达
对象是
SoftReference的被引用者,并且没有强引用指向它。垃圾回收器会尽可能地保留它,但会在抛出OutOfMemoryError之前回收它。 -
弱可达
对象是
WeakReference的被引用者,并且没有强引用指向它。垃圾回收器可以在任何时间回收它,不会试图去保留它。通常这个对象会在Major GC被回收,可能在Minor GC中存活。 -
虚可达
对象是
PhantomReference的被引用者,它已经被选择要回收并且finalizer(如果有)已经运行了。这里的“可达”有点用词不当,在这个时候你已经没有办法访问到原始的对象了。
如你所想,把这三种新的可选状态加到对象生命周期图中会变得很复杂。尽管文档指出了一个逻辑上从强可达到软可达、弱可达、虚可达的回收过程,但实际过程取决于你的程序创建了哪种引用对象。如果你创建了一个 WeakReference 而不是一个 SoftReference ,那么对象回收的过程是直接从强可达到弱可达最后被回收的。
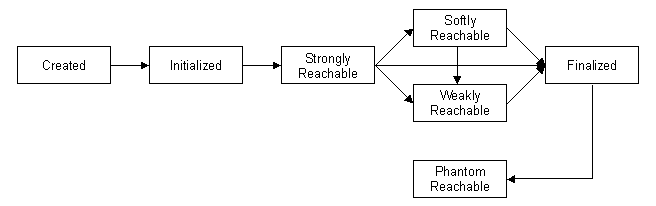
还有一点需要清楚的是,不是所有的对象都需要与引用对象关联,事实上,只有极少部分对象需要。引用对象是一个间接层:你通过引用对象去访问它的被引用者,你肯定不希望你的代码中充斥着这些间接层。事实上大部分程序只会使用引用对象去访问很少一部分它创建的对象。
引用和被引用者
引用对象是在你程序代码和一些称为被引用者的对象之间的中间层。每个引用对象都是围绕它的被引用者创建,并且被引用者是不能修改的。

引用对象提供了 get() 方法来获取被引用者的强引用。垃圾回收器可能在某些情况下回收被引用者,一旦回收了, get() 会返回 null 。正确使用引用,你需要类似下面这样的代码:
SoftReference<List<Foo>> ref = new SoftReference<List<Foo>>(new LinkedList<Foo>());
// 代码其他地方创建了`Foo`,你想把它添加到列表中
List<Foo> list = ref.get();
if (list != null)
{
list.add(foo);
}
else
{
// 列表已经被回收了,做一些恰当的事
}
换言之:
- 你必须总是检查看被引用者是否是null。
垃圾回收器可能在任何时间回收被引用者,如果你无所顾忌地使用,很快就会收获NullPointerException。 - 当你想使用被引用者时,你必须持有一个它的强引用。
再次强调, 垃圾回收器可能在任何时间回收被引用者,甚至是在单个表达式之间。上面的例子如果我不定义list变量,我而是简单地调用ref.get().add(foo),被引用者可能在检查是否为null和实际使用之间被回收。牢记垃圾回收器是在它自己的线程运行的,它不关心你的代码在干什么。 - 你必须持有引用类型的强引用。
如果你创建了一个引用对象,但超出了它的作用域,那么这个引用对象自己也会被回收。这是显然的,但很容易被忘记,特别是在用引用队列(qv)追踪引用对象的时候。
同样要记住的是软引用、弱引用、虚引用只有在没有其他强引用指向被引用者时才有意义,它们让你可以在对象通常会成为垃圾回收器的食物时候获得该对象。这可能看起来很奇怪,如果不再持有强引用了,为什么我还关心这个对象呢?原因视特殊的引用类型而定。
软引用
我们先从软引用开始来回答这个问题。如果一个对象是 SoftReference 的被引用者,并且它没有强引用,那么垃圾回收器可以回收但尽量不去回收它。因此,只要JVM有足够的内存,软引用对象就会在垃圾回收中存活,甚至经历好几轮垃圾回收依然存活。
JDK文档说软引用适用于内存敏感的缓存:每个缓存对象都通过 SoftReference 访问,如果JVM觉得需要内存,它就会清除一些或者所有引用并回收对应的被引用者。如果JVM不需要内存,被引用者就会留在堆中,并且可以被程序代码访问到。在这种方案下,被引用者在使用时是强引用的,其他情况是软引用的,如果软引用被清除了,你需要刷新缓存。
想作为这种角色使用,被缓存的对象需要比较大,如每个几kB。比如说,你想实现一个文件服务相同的文件会被定期检索,或者有一些大的图片对象需要缓存时会有用。但如果你的对象很小,你只有在需要定义大量对象时情况才会不同,引用对象还会增加整个程序的负担。
内存限制型缓存被认为是有害的
我的观点是,可用内存绝对是最差的管理缓存的方式。如果你的堆很小,你不时需要重新加载对象,无论它们是不是被活跃地使用,你也无法知道这个,因为缓存会静默地处理它们。大的堆更糟:你会持有对象远大于它的正常寿命,当每次垃圾回收时会使你的应用变慢,因为需要检查这些对象。如果这些对象没有被访问,这一部分堆有可能被交换出去,回收过程中可能有大量页错误。
底线:如果你要用缓存,详细它会如何被使用,选一个适合的缓存策略(LRU、timed LRU),在选择基于内存的策略前仔细考虑。
软引用用于断路器
用软引用为内存分配提供断路器是更好的选择:在你的代码和它分配的内存之间使用软引用,你就可以避免可怕的 OutOfMemoryError 。这个技巧可以正常运作是因为在应用里内存的分配是趋于局部的:从数据库中读取行、从一个文件中处理数据。
例如,如果你写过很多JDBC的代码,你可能会有类似下面这样的方法以某种方式处理查询的结果并且确保 ResultSet 被正确地关闭。这只有一个小缺陷:如果查询返回了一百万行,你没有可用的内存去保存它们时会发生什么?
public static List<List<Object>> processResults(ResultSet rslt)
throws SQLException
{
try
{
List<List<Object>> results = new LinkedList<List<Object>>();
ResultSetMetaData meta = rslt.getMetaData();
int colCount = meta.getColumnCount();
while (rslt.next())
{
List<Object> row = new ArrayList<Object>(colCount);
for (int ii = 1 ; ii <= colCount ; ii++)
row.add(rslt.getObject(ii));
results.add(row);
}
return results;
}
finally
{
closeQuietly(rslt);
}
}
答案当然是会得到 OutOfMemoryError 。这是使用断路器的绝佳地方:如果在处理查询时JVM要耗尽内存了,那就释放所有已经使用的那些内存,抛出一个应用特殊的异常。
你可能很奇怪,这种情况下这次查询将被忽略,为什么不直接让内存耗尽的错误来做这件事呢?原因是并不仅仅只有你的应用被内存耗尽影响。如果你在一个应用服务器上运行,你的内存使用可能干掉其他应用。即使是在一个独有的环境,断路器也能提升你的应用的健壮性,因为它能限制问题,让你有机会恢复并继续运行。
要创建一个断路器,首先你需要做的是把结果的列表包装在 SoftReference 中(你在前面已经见过这个代码了):
SoftReference<List<List<Object>>> ref
= new SoftReference<List<List<Object>>>(new LinkedList<List<Object>>());
然后,你遍历结果,在你需要更新这个列表时为它创建强引用:
while (rslt.next())
{
rowCount++;
// store the row data
List<List<Object>> results = ref.get();
if (results == null)
throw new TooManyResultsException(rowCount);
else
results.add(row);
results = null;
}
这可以满足要求是因为这个方法几乎所有的内存分配都发生在2个地方:调用 next() 时和代码把行里的数据存放到它自己的列表中时。第一种情况当你调用 next() 时会发生很多事情: ResultSet 一般会在包含多行的一大块二进制数据中检索,然后当你调用 getObject() ,它会取出一部分数据把它转成Java对象。
当这些昂贵的操作发生时,这个list只有来自 SoftReference 的引用,如果内存耗尽,引用会被清除,list会变成垃圾。这意味着这个方法可能抛出异常,但抛出异常的影响是有限的,也许调用方能以一点数量限制重新进行查询。
一旦昂贵的操作完成,你可以没有影响地拿到list的强引用。注意到我用 LinkedList 保存结果而不是 ArrayList , LinkedList 增长时只会增加少量字节,不太可能引起 OutOfMemoryError ,而如果 ArrayList 需要增加容量,它需要创建一个新数组,对于大列表来说,这可能意味着数MB的内存分配。
还注意到我在添加新元素后把 results 变量设置为 null ,这是少数几种这样做是合理的情形之一。尽管在循环的最后变量超出了作用域,但垃圾回收器可能并不知道(因为JVM没有理由去清除变量在调用栈中的位置)。因此如果我不清除这个变量的话,它会在随后的循环中成为隐藏的强引用。
软引用不是万能的
软引用可以预防很多内存耗尽的情况,但不能预防所有。问题在于:为了真正地使用软引用,你需要创建一个被引用者的强引用,即为了向 results 中添加一行,我们需要持有实际列表的引用。我们持有强引用的时候就会面临发生内存耗尽错误的风险。
使用断路器的目标是把一些无用的东西的时间窗口减到最小:你持有对象强引用的时间,更重要的是在这段时间中分配内存的总量。在我们的例子中,我们限制强引用去添加一行到 results 中,我们使用 LinkedList 而不是 ArrayList 因为前者扩容时增长更小。
我想重申的是,如果我一个变量持有强引用,但这个变量很快超出了作用域,语言细则没有说JVM需要清除超出作用域的变量,如果是像写的这样,Oracle/OpenJDK JVM都没有这样做,如果我不明确地清除 results 变量,在遍历期间会保持强引用,阻止软引用做它的工作。
最后,仔细考虑那些隐藏的强引用。例如,你可能会想在使用DOM构造XML文档时加入断路器。在DOM中,每个节点都持有它父节点的引用,从而导致持有了树中每个其他节点的引用。如果你用递归去创建文档,你的栈中可能塞满了个别节点的引用。
弱引用
弱引用,正如它名字显示,是一个当垃圾回收器来敲门时不会反抗的引用对象。如果被引用者没有强引用或软引用而只有弱引用,那它就可以被回收。所以弱引用有什么用呢?有2个主要用途:关联没有内在联系的对象,或者通过 canonicalizing map 减少重复。
ObjectOutputStream 的问题
第一个例子,我准备聚焦不使用弱引用的对象序列化。 ObjectOutputStream 以及它的伙伴 ObjectInputStream 提供了任意Java对象与字节流之间相互转换的方式。根据对象模型的观点,流和用这些流写的对象之间是没有联系的。流不是由这些被写的对象组成的,也不是它们的聚集。
但是当你看这些流的说明时,你会看到事实上是有联系的:为了维持对象的唯一性,输出流会和每个被写的对象关联一个唯一的标识符,随后的写对象的请求被替换为写这个标识符。这个特征对于流序列号对象的能力来说绝对是很重要的,如果没有这个特征,自我引用的对象会变成一个无限的字节流。
要实现这个特征,流需要持有每个写到流中的对象的强引用。对于决定在socket通信时用对象流作为消息协议的程序员来说,有这么一个问题:消息被设计为短暂的,但流会在内存中持有它们,不久之后,程序会耗尽内存(除非程序员知道在每次通信后调用 reset() )。
这种非与生俱来的联系惊人的普遍。它们会在程序员为了使用对象而需要去维持必不可少的上下文时出现。有时这些联系被运行环境默默管理,例如servlet Session 对象;有时这些联系需要被程序员明确地管理,例如对象流;还有些时候,这种联系只有当生产环境的服务抛出内存耗尽的错误时才会被发现,比如埋藏在程序代码深处的静态 Map 。
弱引用提供了一种维持这种联系的同时还能让垃圾回收器做它的工作的方式,弱引用只有在同时还有强引用时才保持有效。回到对象流的例子,如果你用流来通信,一旦消息被写完就可以被回收了。另一方面,当流用来RMI访问一个生命周期很长的数据结构时,它能保持它一致。
不幸的是,尽管对象流通信协议在JDK 1.2时被更新了。虚引用也是这样被加入的,但JDK的开发者并没有选择把二者结合到一起,所以记得调用 reset() 。
用 Canonicalizing Maps 消除重复数据
尽管存在对象流这种情况,但我不认为有很多你应该关联两个没有内在关系的对象的情行。我所看到的一些例子,例如Swing监听器,它们会自我清理,看起来更像是黑客,而不是有效的设计选择。
当我最初写这篇文章的时候,大约是在2007年,我提出了 canonicalizing map 作为 String.intern() 的替代物,是在假设被存入常量池的字符串永远不会被清理的前提下。后来我得知这种担心是毫无根据的。更重要的是,从JDK 8开始,OpenJDK已经完全去掉了永久代。因此,没有必要害怕 intern() ,但是 canonicalizing map 对于字符串以外的对象仍然有用。
在我看来,弱引用的最佳用途是实现 canonicalizing map ,这是一种确保同时只存在一个值对象实例的办法。 String.intern() 是这种map的典型例子:当你把一个字符串存入常量池时,JVM会将它添加到一个特殊的map中,这个map也用于保存字符串文本。这样做的原因不是像一些人认为的那样为了更快地进行比较。这是为了最大限度地减少重复的非文字字符串(如从文件或消息队列中读取的字符串)占用的内存量。
简单的 canonicalizing map 通过使用相同的对象作为key和value来工作:你用任意实例传给map,如果map中已经有一个值,你就返回它。如果map中没有值,则存储传入的实例(并返回它)。当然,这仅适用于可用作map的key的对象。如果我们不担心内存泄漏,下面可能是我们实现 String.intern() 的方式:
private Map<String,String> _map = new HashMap<String,String>();
public synchronized String intern(String str)
{
if (_map.containsKey(str))
return _map.get(str);
_map.put(str, str);
return str;
}
如果你只有少量字符串要放入常量池,例如也许在处理一个文件的简单方法中,这个实现没什么问题。然而,假设你正在编写一个长期运行的应用程序,该应用程序必须处理来自多个来源的输入,其中包含范围广泛的字符串,但仍有高度的重复。例如,一台处理上传的邮政地址数据文件的服务: New York 将会有很多条目, Temperanceville VA 的条目就不多了。你会想要消除前者的重复,但是不想保留后者超过必要的时间。
这就是弱引用的 canonicalizing map 有所帮助的地方:只有程序中的一些代码正在使用它,它才允许你创建一个规范的实例。最后一个强引用消失后,这个规范的字符串将被回收。如果稍后再次出现该字符串,它将成为新的规范的实例。
为了改进我们的“规范化工具”,我们可以用 WeakHashMap 替换 HashMap :
private Map<String,WeakReference<String>> _map
= new WeakHashMap<String,WeakReference<String>>();
public synchronized String intern(String str)
{
WeakReference<String> ref = _map.get(str);
String s2 = (ref != null) ? ref.get() : null;
if (s2 != null)
return s2;
_map.put(str, new WeakReference(str));
return str;
}
首先要注意的是,虽然map的key是字符串,但它的值是 WeakReference<String> 。这是因为 WeakHashMap 对其key使用弱引用,但对其value持有强引用。因为我们的key和value是相同的,所以entry永远不会被回收。通过包装条目,我们让GC回收它。
其次,注意返回字符串的过程:首先我们检索弱引用,如果它存在,那么我们检索引用对象。但是我们也必须检查那个对象。存在引用仍在map中但已经被清除了的可能。只有当引用对象不为空时,我们才返回它;否则,我们认为传入的字符串是新的规范的版本。
第三,请注意我对 intern() 方法用了 synchronized 。 canonicalizing map 最有可能的用途是在多线程环境中,例如应用服务, WeakHashMap 没有内部同步。这个例子中的同步实际上相当幼稚, intern() 方法可能成为争论的焦点。在现实世界的实现中,我可能会使用 ConcurrentHashMap ,但是对于教程来说,这种幼稚的方法更有效。
最后, WeakHashMap 的文档关于条目何时从map中移除有些模糊。它指出,“ WeakHashMap 的行为可能就像一个未知线程正在无声地删除条目。”实际上没有其他线程。相反,每当map被访问时,它就会被清理。为了跟踪哪些条目不再有效,它使用了引用队列。
引用队列
虽然判断一个引用是不是null可以让你知道它的引用对象是不是已经被回收,但是这样做并不是很高效;如果你有很多引用,你的程序会花大部分时间寻找那些已经被清除的引用。
更好的解决方案是引用队列:你在构建时将引用与队列相关联,并且该引用将在被清除后放入队列中。要发现哪些引用已被清除,你需要从队列拉取。这可以通过后台线程来完成,但是在创建新引用时从队列拉取通常更简单( WeakHashMap 就是这样做的)。
引用队列最常与虚引用一起使用,在后面会描述,但是可以与任何引用类型一起使用。下面的代码是一个弱引用的例子:它创建了一组缓冲区,通过 WeakReference 访问,并且在每次创建后查看哪些引用已经被清除。如果运行此代码,你会看到 create 消息的长时间出现,当垃圾回收器运行时偶尔会出现一些 clear 消息。
public static void main(String[] argv) throws Exception
{
Set<WeakReference<byte[]>> refs = new HashSet<WeakReference<byte[]>>();
ReferenceQueue<byte[]> queue = new ReferenceQueue<byte[]>();
for (int ii = 0 ; ii < 1000 ; ii++)
{
WeakReference<byte[]> ref = new WeakReference<byte[]>(new byte[1000000], queue);
System.err.println(ii + ": created " + ref);
refs.add(ref);
Reference<? extends byte[]> r2;
while ((r2 = queue.poll()) != null)
{
System.err.println("cleared " + r2);
refs.remove(r2);
}
}
}
一如既往,关于这个代码有一些值得注意的事情。首先,虽然我们创建的是 WeakReference 实例,但是队列会给我们返回 Reference 。这提醒你,一旦它们入队,你使用的是什么类型的引用就不再重要了,被引用者已经被清除。
第二,我们必须对引用对象本身进行强引用。引用对象知道队列,但是队列在引用进入队列前不知道引用。如果我们没有维护对引用对象的强引用,它本身就会被回收,并且永远不会被添加到队列中。在这个例子中,我使用了一个 Set ,一旦引用被清除,就删除它们(将它们留在 Set 中是内存泄漏)。
虚引用
虚引用不同于软引用和弱引用,它们不用于访问它们的被引用者。相反,他们的唯一目的是当它们的被引用者已经被回收时通知你。虽然这看起来毫无意义,但它实际上允许你比 finalizers 更灵活地执行资源清理。
Finalizers 的问题
这篇文章 中我更详细地讨论了 finalizers 。简而言之,你应该依靠 try/catch/finally 清理资源,而不是 finalizers 或虚引用。
在对象生命周期的描述中,我提到 finalizers 有一些微妙的问题,使得它们不适合清理非内存资源。还有一些非微妙的问题,为了完整起见,我将在这里讨论。
-
finalizer可能永远不会被调用如果你的程序从未用完可用内存,那么垃圾回收器不会运行,你的
finalizer也不会运行。对于长时间运行的应用程序(例如服务)来说,通常不会出现这个问题,但是短时间运行的程序可能会在没有运行垃圾收集的情况下完成。虽然有一种方法可以告诉JVM在程序退出之前运行finalizers,但这是不可靠的,可能会与其他shutdown hooks冲突。 -
Finalizers可能创建一个对象的其他强引用例如,通过将对象添加到集合中。这基本上复活了这个对象,但是,就像
Stephen King's Pet Sematary一样,返回的对象“不太正确”。尤其是,当对象再次符合回收条件时,它的finalizer不会运行。也许你会使用这种复活技巧是有原因的,但是我无法想象,而且在代码上看起来会非常模糊。
现在这些都已经过时了,我相信 finalizers 的真正问题是它们在垃圾回收器首次识别要回收的对象的时间和实际回收其内存的时间之间引入了间隙,因为 finalization 发生在它自己的线程上,独立于垃圾回收器的线程。JVM保证在返回 OutMemoryError 之前执行一次 full collection ,但是如果所有符合回收条件的对象都有 finalizers ,则回收将不起作用:这些对象保留在内存中等待 finalization 。假设一个标准JVM只有一个线程来处理所有对象的 finalization ,一些长时间运行的 finalization ,你就可以看到问题可能会出现。
以下程序演示了这种行为:每个对象都有一个 finalizer 休眠半秒钟。不会有很长时间,除非你有成千上万的对象要清理。每个对象在创建后都会立即超出作用域,但是在某个时候你会耗尽内存(如果你想运行这个例子,我建议使用 -Xmx64m 来使错误快速发生;在我的开发机器上,有3Gb堆,实际上需要几分钟才能失败)。
public class SlowFinalizer
{
public static void main(String[] argv) throws Exception
{
while (true)
{
Object foo = new SlowFinalizer();
}
}
// some member variables to take up space -- approx 200 bytes
double a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z;
// and the finalizer, which does nothing by take time
protected void finalize() throws Throwable
{
try { Thread.sleep(500L); }
catch (InterruptedException ignored) {}
super.finalize();
}
}
虚引用知晓之事
当对象不再被使用时虚引用允许应用程序知晓,这样应用程序就可以清理对象的非内存资源。然而,与 finalizers 不同的是,当应用程序知道到这一点时,对象本身已经被收集了。
此外,与 finalizers 不同,清理由应用程序而不是垃圾回收器来调度。您可以将一个或多个线程专用于清理,如果对象数量需要,可以增加线程数量。另一种方法——通常更简单——是使用对象工厂,并在创建新实例之前清理所有回收的实例。
理解虚引用的关键点是,你不能使用引用来访问对象: get() 总是返回null,即使对象仍然是强可达的。这意味着引用对象持有的不能是要清理的资源的唯一引用。相反,你必须维持对这些资源的至少一个其他强引用,并使用引用队列来通知被引用者已被回收。与其他引用类型一样,您的程序也必须拥有对引用对象本身的强引用,否则它将被回收,资源将内存泄露。
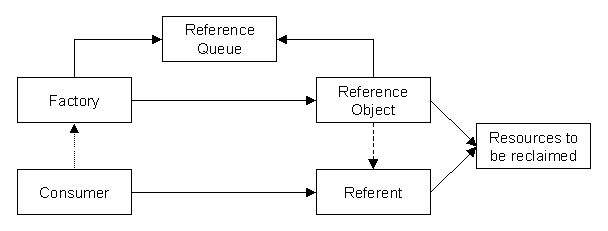
用虚引用实现连接池
数据库连接是任何应用程序中最宝贵的资源之一:它们需要时间来建立,并且数据库服务器严格限制它们将接受的同时打开的连接的数量。尽管如此,程序员对它们非常粗心,有时会为每个查询打开一个新的连接,或者忘记关闭它,或者不在 finally 块中关闭它。
大多数应用服务部署使用连接池,而不是允许应用直接连接数据库:连接池维护一组打开的连接(通常是固定的),并根据需要将它们交给程序。用于生产环境的连接池提供了几种防止连接泄漏的方法,包括超时(识别运行时间过长的查询)和恢复被垃圾回收器回收的连接。
下面这个连接池旨在演示虚引用,不能用于生产环境。Java有几个可用于生产环境的连接池,如 Apache Commons DBCP 和 C3P0 。
后一个特性是虚引用的一个很好的例子。为了使它工作,连接池提供的 Connection 对象只是实际数据库连接的包装,可以在不丢失数据库连接的情况下回收它们,因为连接池保持对实际连接的强引用。连接池将虚引用与“包装成的”连接相关联,如果引用最终出现在引用队列中,则会将实际连接返回给连接池。
连接池中最不有趣的部分是 PooledConnection ,如下所示。正如我说过的,它是一个包装,委派对实际连接的调用。不同的是我使用了反射代理来实现。JDBC接口随着Java的每一个版本而发展,其方式既不向前也不向后兼容;如果我使用了具体的实现,除非你使用了与我相同的JDK版本,否则你将无法编译。反射代理解决了这个问题,也使代码变得更短。
public class PooledConnection
implements InvocationHandler
{
private ConnectionPool _pool;
private Connection _cxt;
public PooledConnection(ConnectionPool pool, Connection cxt)
{
_pool = pool;
_cxt = cxt;
}
private Connection getConnection()
{
try
{
if ((_cxt == null) || _cxt.isClosed())
throw new RuntimeException("Connection is closed");
}
catch (SQLException ex)
{
throw new RuntimeException("unable to determine if underlying connection is open", ex);
}
return _cxt;
}
public static Connection newInstance(ConnectionPool pool, Connection cxt)
{
return (Connection)Proxy.newProxyInstance(
PooledConnection.class.getClassLoader(),
new Class[] { Connection.class },
new PooledConnection(pool, cxt));
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable
{
// if calling close() or isClosed(), invoke our implementation
// otherwise, invoke the passed method on the delegate
}
private void close() throws SQLException
{
if (_cxt != null)
{
_pool.releaseConnection(_cxt);
_cxt = null;
}
}
private boolean isClosed() throws SQLException
{
return (_cxt == null) || (_cxt.isClosed());
}
}
需要注意的最重要的一点是, PooledConnection 同时引用了底层数据库连接和连接池。后者用于那些确实记得关闭连接的应用程序:我们希望立即告知连接池,以便底层连接可以立即被重用。
getConnection() 方法也值得一提:它的存在是为了捕捉那些在显式关闭连接后试图使用该连接的应用程序。如果连接已经交给另一个消费者,这可能是一件非常糟糕的事情。因此 close() 显式清除引用, getConnection() 会检查该引用,并在连接不再有效时抛出异常。 invocation handler 用于所有委托调用。
现在让我们将注意力转向连接池本身,从它用来管理连接的对象开始。
private Queue<Connection> _pool = new LinkedList<Connection>(); private ReferenceQueue<Object> _refQueue = new ReferenceQueue<Object>(); private IdentityHashMap<Object,Connection> _ref2Cxt = new IdentityHashMap<Object,Connection>(); private IdentityHashMap<Connection,Object> _cxt2Ref = new IdentityHashMap<Connection,Object>();
当连接池被构造并存储在 _pool 中时,可用连接被初始化。我们使用引用队列 _refQueue 来标识已回收的连接。最后,我们有连接和引用之间的双向映射,在将连接返回到连接池时使用。
正如我之前说过的,实际的数据库连接将在提交给应用程序代码之前被包装在 PooledConnection 中。这发生在 wrapConnection() 函数中,也是我们创建虚引用和连接-引用映射的地方。
private synchronized Connection wrapConnection(Connection cxt)
{
Connection wrapped = PooledConnection.newInstance(this, cxt);
PhantomReference<Connection> ref = new PhantomReference<Connection>(wrapped, _refQueue);
_cxt2Ref.put(cxt, ref);
_ref2Cxt.put(ref, cxt);
System.err.println("Acquired connection " + cxt );
return wrapped;
}
与 wrapConnection 对应的是 releaseConnection() ,该函数有两种变体。当应用程序代码显式关闭连接时, PooledConnection 调用第一个,这是“快乐的道路”,它将连接放回连接池中供以后使用。它还会清除连接和引用之间的映射,因为它们不再需要。请注意,此方法具有默认(包)同步:它由 PooledConnection 调用,因此不能是私有的,但通常不可访问。
synchronized void releaseConnection(Connection cxt)
{
Object ref = _cxt2Ref.remove(cxt);
_ref2Cxt.remove(ref);
_pool.offer(cxt);
System.err.println("Released connection " + cxt);
}
另一个变体使用虚引用来调用,这是“可悲的道路”,当应用程序不记得关闭连接时才会调用。在这种情况下,我们得到的只是虚引用,我们需要使用映射来检索实际连接(然后使用第一个变体将其返回到连接池中)。
private synchronized void releaseConnection(Reference<?> ref)
{
Connection cxt = _ref2Cxt.remove(ref);
if (cxt != null)
releaseConnection(cxt);
}
有一种边缘情况:如果引用在应用程序调用 close() 之后进入队列,会发生什么?这种情况不太可能发生:当我们清除映射时,虚引用应该已经有资格被回收,这样它就不会进入队列。然而,我们必须考虑这种情况,这导致上面的空检查:如果映射已经被移除,那么连接已经被显式返回,我们不需要做任何事情。
好了,您已经看到了底层代码,现在是时候让应用程序调用唯一的方法了:
public Connection getConnection()
throws SQLException
{
while (true)
{
synchronized (this)
{
if (_pool.size() > 0)
return wrapConnection(_pool.remove());
}
tryWaitingForGarbageCollector();
}
}
getConnection() 的最佳路径是在 _pool 中有可用的连接。在这种情况下,一个连接被移除、包装并返回给调用者。不信的情况是没有任何连接,在这种情况下,调用者希望我们阻塞直到有一个连接可用。这可以通过两种方式发生:要么应用程序关闭连接并返回到 _pool 中,要么垃圾回收器找到一个已被放弃的连接,并将其关联的虚引用加入队列。
为什么我使用 synchronized(this) 而不是显式锁?简而言之,这个实现是作为教学辅助工具,我想用最少的样板来强调同步点。在生产环境使用的连接池中,我实际上会避免显式同步,而是依赖并行数据结构,如 ArrayBlockingQueue 和 ConcurrentHashMap 。
在走这条路之前,我想谈谈同步。显然,对内部数据结构的所有访问都必须同步,因为多个线程可能会尝试同时获取或返回连接。只要 _pool 中有连接,同步代码就能快速执行,竞争的可能性就很低。然而,如果我们必须循环直到连接变得可用,我们希望最大限度地减少同步的时间:我们不希望在请求连接的调用者和返回连接的另一个调用者之间造成死锁。因此,在检查连接时,使用显式同步块。
那么,如果我们调用 getConnection() ,并且池是空的,会发生什么呢?这是我们检查引用队列以找到被废弃的连接的时机。
private void tryWaitingForGarbageCollector()
{
try
{
Reference<?> ref = _refQueue.remove(100);
if (ref != null)
releaseConnection(ref);
}
catch (InterruptedException ignored)
{
// we have to catch this exception, but it provides no information here
// a production-quality pool might use it as part of an orderly shutdown
}
}
这个函数强调了另一组相互冲突的目标:如果引用队列中没有任何引用,我们不想浪费时间,但是我们也不想在一个循环中重复检查 _pool 和 _refQueue 。所以我在轮询队列时使用了一个短暂的超时时间:如果没有准备好,它会给另一个线程返回连接的机会。当然,这也带来了一个公平性问题:当一个线程正在等待引用队列时,另一个线程可能会返回一个被第三个线程立即占用的连接。理论上,等待线程可能会永远等待。在现实世界中,由于不太需要数据库连接,这种情况不太可能发生。
虚引用带来的问题
前面我提到到 finalizers 不能保证被调用。虚引用也是这样,原因相同:如果回收器不运行,不可达的对象不会被回收,对这些对象的引用也不会进入队列。考虑一个程序只在循环中调用 getConnection() ,让返回的连接超出作用域,如果它没有做任何其他事情来让垃圾回收器运行,那么它会很快耗尽连接池然后阻塞,等待永远无法恢复的连接。
当然,有办法解决这个问题。最简单的方法之一是在 tryWaitingForGarbageCollector() 中调用 System.gc() 。尽管围绕这种方法有一些争议,但这是促使JVM回到理想状态的有效方式。这是一种既适用于 finalizers 也适用于虚引用的技术。
这并不意味着你应该忽略虚引用,只使用 finalizer 。例如,在连接池的情况下,你可能希望显式关闭该连接池并关闭所有底层连接。你可以用 finalizer 来完成,但是需要和虚引用一样多的工作。在这种情况下,通过引用获得的可控因素(相对于任意终结线程)使它们成为更好的选择。
最后一些思考:有时候你只需要更多内存
虽然引用对象是管理内存消耗的非常有用的工具,但有时它们是不够的,有时又是过度的。例如,假设你正在构建一些大型对象,其中包含从数据库中读取的数据。虽然你可以使用软引用作为读取的断路器,并使用弱引用将数据规范化,但最终您的程序需要一定量的内存来运行。如果你不能给它足够的内存来实际完成任何工作,那么不管你的错误恢复能力有多强都无济于事。
应对 OutOfMemoryError 时你首先应该搞清楚它为什么会发生。可能你有内存泄露,可能仅仅是你内存的设置太低了。
开发过程中,你应该指定大的堆内存大小——1G或更多——关注程序到底用了多少内存(这种情况jconsole是一个有用的工具)。大多数应用会在模拟的负载下达到一个稳定的状态,这将指引你的生产环境堆配置。如果你的内存使用随时间增长,那很可能你在对象不再使用后仍持有强引用,引用类型可能会有用,但更可能的是有bug需要修复。
底线是你需要理解你的应用。如果没有重复, canonicalizing map 对你没有帮助。如果你希望定期执行数百万行查询,软引用是没有用的。但是在可以使用引用对象的情况下,它们会是你的救命恩人。
正文到此结束
- 本文标签: http 图片 bug JVM stream rmi db 食物 黑客 CTO XML final entity ORM 模型 ArrayList 缓存 协议 线程 调试 空间 消息队列 锁 src queue id LinkedList Proxy 编译 数据库 开发者 时间 实例 开发 Connection 监听器 服务端 索引 newProxyInstance ssl Oracle UI 代码 DOM 操作系统 C3P0 文章 希望 session ResultSet 服务器 tar 配置 多线程 遍历 参数 DBCP ACE 垃圾回收 ConcurrentHashMap JDBC root map 管理 解析 list 同步 生命 Collection HashMap 连接池 递归 apache https sql IDE 程序员 value 总结 删除 IO 回答 synchronized HashSet java servlet cat 数据 App key
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

