前后端分离看阿里Web应用架构
| 编辑推荐: |
| 本文来自于infoq,本文主要介绍了阿里过去的几年都在和数据分析类产品打交道,经历了几代数据产品的演变和架构变迁(淘宝数据平台的数据魔方、面向精准营销的全景洞察、面向数据分析的 DataV)。 |
前后端分离为什么出现?本质上是什么?前后端分离运动对 web 应用的架构带来了怎么样的变化?前后端分离怎么分离?为什么是 Node.js? 前后端分离的未来怎样?
阿里前端技术专家剪巽 老师在今年 7 月 ArchSummit 大会深圳站上探讨了这个话题。
前后端分离走过了一段历程,最根本的原因是传统的后段服务支撑不了现代化的前端开发。平时工作中用到的工具链、开发框架、规范协议、浏览器等在不断涌现,这些新的技术在给开发环境、开发流程提了更多新需求。Node.js 在这个背景下能够把这些工具串联起来。以前 Java 的同学在开发、调试的时候要泡一杯咖啡,非常耗时。
前后端分离的 3 个阶段
1. 模板层的分工
最早的 Java 开发阶段需要一个包含所有内容的 war 包,整个前端的编排,像 HTML 页面、CSS、JS 很多时候包含在 HTML 页面,也会出现脚本复用、样式复用抽离出来。所以前端开发当时是围绕著名的 velocity 模版。这一层最大的问题是,后端的同学看前端资源像看天书,前端同学看后端模版也像是看天书,融合效率非常低。
2. 静态资源独立部署
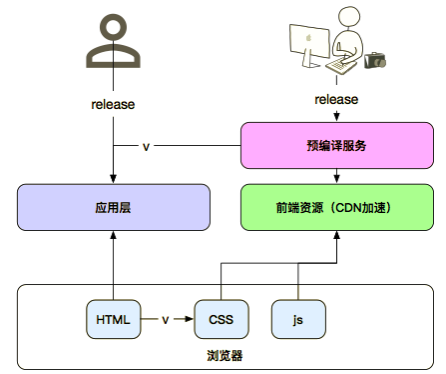
Web 2.0 之后,大量的前端资源需求出现,Web 前端体验最大的改进就是副客户端,客户端资源非常庞大,代码不再是直接发布到线上,而是要编译,做预处理,可能还要做 CDN 的加速。整个应用被分割成两部分,后端服务发布之后,前端服务要独立更新,这样就给应用的更新带来了便利。这里存在一个问题是接口的协调,前端的需求变更,数据的要求也会变化,需要后端去协调资源的编排。另外一个问题是测试,前端持有脚本,样式资源,而模版却在应用层,应用层的开发、发布也是很复杂的。
3. 独立应用层
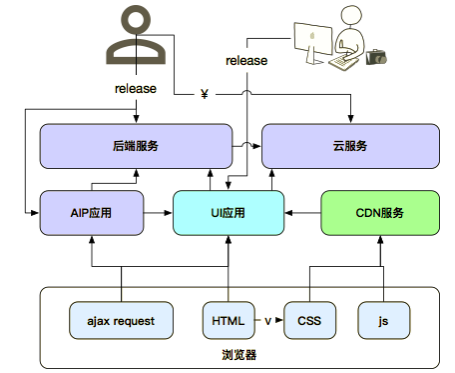
这一层的变化在于,Node.js 可以提供工具能力之外,还具备很强的服务能力,从 mock 数据开始,到前端代码的预编译,资源编排,这些动作都合并到一个应用里面,前端形成 UI 应用层。后端相关的接口回退到 API,或者云端。在这一层,前端具备了更灵活、强大的能力,在数据编排这一层,Node.js 可以做轻量的粘合,服务端的开发也在往微服务方向发展,提升了开发效率。
为什么是 Node.js
在语言特性方面,Node.js 无需切换,整个开发、工具、日常工作中 Node.js 一种语言就可以满足所有需求。此外 Node.js 还有优异的性能,一直在迭代。
其次是在社区生态上,在语言模块包上的贡献数据,NPM 库的数据量很高。Node.js 能从服务端框架去链接服务,整合成前端所需数据资源。
另外在生产周边,Node.js 的语言成熟度很有优势,社区里关于泄漏、性能调优的工具也有很多研究,对前端开发更友好。
产品中的实践:
通常大数据服务里,需要解决计算和存储能力。业务曾有很多的需求,从数据接入,到离线处理,到实时分析,所以它的特点是有很多的依赖,而前端无法做到相应每一个需求,大量需要 mock。
另外就是业务的需求很多,在流程控制、数据转换、数据安全、分析展现等方面需要有大量的组件沉淀。最大的特点是有众多独立的功能模块。
而要想让这些模块和功能实现有什么解法呢?就需要这三个方法:制定框架,微应用分割,运维工程化。
1. 定制应用框架就是来解决前端的编译,工程管理,数据 mock 等问题。
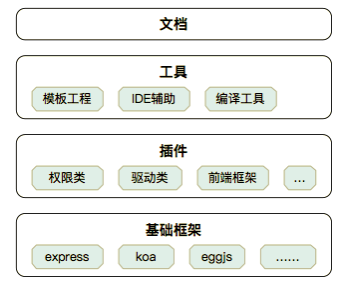
面向应用的时候,更多的是在第二层和第三层做定制化封装,把业务插件都封装起来。应用层在运行过程中,前端会托管所有权限相关的事情,包括登录系统,中间件等等。此外还会连接很多服务和驱动,把前端框架集成起来,这是一个完整的开发环境。
2. 把各自独立的模块应用切割成微应用,一个微应用解决一个问题,便于分工和隔离处理。
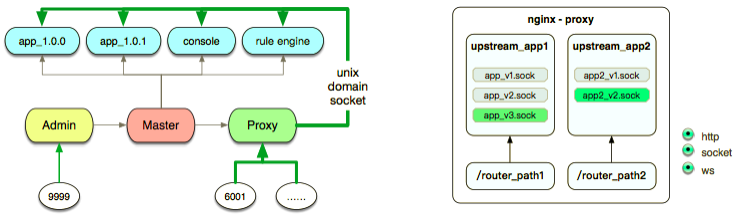
具体做法是微服务拆分,搭建微应用服务,承载大量的小服务,同时也会出现很多域名的问题,很多访问入口。这里做了一些小创新,在入口可以定义端口,sever name,访问 path,当把一个场景分成 10 个应用发布,发布之后再根据不同的路径拼接成一个应用,对体验没有影响。
除了路由自动化规划之后,对应用的发布做到上下平滑,不会影响流量。前端人员自己打包发布就可以了。
3. 当这些应用被分割的很细致之后,随之而来的是如何管理这些小应用。
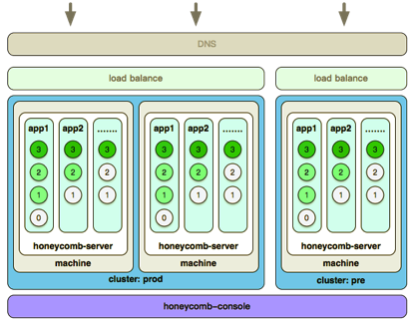
比如有两台机器做互备,把所有小 App 都发布到上面之后,由一个个小颗粒组成一个大应用,看上去很像一个蜂巢,因此命名 honeycomb,这些蜂巢组成一个大蜂窝,完成一个主功能。在应用推进过程中,有些应用压力大,需要把应用集群隔离开,把有不同业务需求场景环境,例如开发环境、预发环境、线上环境隔离开来,不同环境配置的集群资源和机器数量都不一样。随着业务发展,隔离的事情会教给容器去执行。
分层设计解决 Node.js 密集计算问题
社区里有一个讨论,Node.js 是否适合密集计算?密集计算分成两层,绿色部分会接收用户请求,第二层浅蓝色会处理用户请求,写很多的 processor,提供大量的进程去提供密集计算。主要问题在于 CPU 容量是恒定的,当有很多并发请求的时候,如何保证在服务层去很好的分配计算任务。拆成两层之后,保证用户请求不会被 block 掉。如果第一层大量的密集计算,会导致用户的请求或者连接的需求被挡住,接收不到响应,所以要往后堆,做成队列,可扩容的大集群。整个结果在 Java 里就可以理解为 Java 庞大线程的处理过程。
社区里在线程库里还有一些尝试,Napa.js 是微软开源的线程库,前端同构的需求可以探索使用 Napa.js 这个工具。
DataV 场景使用案例
DataV 是一个可视化产品,类似于 PPT,有编辑器,最主要的功能是把各种组件挂到浏览器屏幕上,组件和组件之间形成事件绑定,事件驱动组件去调用数据服务,数据从计算层返回。
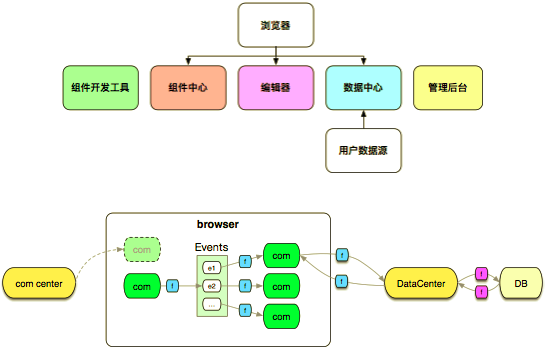
它的特点之一是,数据请求量非常多,请求排队之后,要把数据合并起来,在服务器端请求太多数据源会出现慢的情况,导致请求驻留在服务器端,内存的波动会很严重。这里的解决方案是先到先返回。另外一个是在提供组件自定义开发功能的时候会遇到代码转换的需求,我们是在线帮助用户转代码,这里存在很多动态编译的过程,以及数据处理。
Node.js 应用层带来的便捷
Node.js 在这个场景下是有很多优势的,例如在 server 层可以更便捷的去完成这些开发以及支持,Babeljs 可以做代码转换的事情,Bigpipe 可以优化服务端的内存,可以缩减渲染时间,提升体验优化。在前面的数据流里有很多的 filter,给数据链中插入 processor,来定义处理微小的数据。用户在原始的数据到完整的可视化展现不需要再搭建一个产品去支持,只需要搭几个 filter,配几个数据源,拖几个组件就可以完成。Node.js 在这一层提供了很多便捷之处,例如创新实现。
所以,Node.js 在微应用体系里有很多优势,开发、测试、运维可维护性上有独立性。Node.js 给前端带来创新的便利性也体现在另外一点,那就是在云端的一些服务上,前端有能力在 service 集成、改变使用流程做很多事情。
前端接下来的变化
HTTP2/WebSocket 在网络层会在更多的场景里带来不同的体验。
还有前后端同构、WebGL、WebWorker、工具链的继续进化,前端的工具、资源编排、框架等都在快速变化。
而服务端趋势:云化(更细粒度的虚拟化)、服务化(API、可编程)、智能化(数据智能普及)、编排(微服务、微应用运维便捷),也给前端带来更多的机遇。
前端的边界会在这些变化中被拓宽,新一轮的创新会在这其中迸发。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

