偏向锁状态转移原理
当多个处理器同时处理的时候,通常需要处理互斥的问题。
一般的解决方式都会包含 acquire 和 release 这个两种操作,操作保证,一个线程在acquire执行之后,在它执行release之前,其它线程不能完成acquire操作。这个过程经常就涉及到锁。研究表明(L. Lamport A fast mutual execlusion algorithm),通过 fast locks算法可以做到,lock和unlock操作所需的时间与潜在的竞争处理器数无关。
java内置了monitor来处理多线程竞争的情况.
-
一种优化方式是使用 轻量锁来在大多数情况下避免重量锁的使用,轻量锁的主要机制是在monitor entry的时候使用原子操作,某些退出操作也是这样,如果有竞争发生就转而退避到使用操作系统的互斥量
轻量锁认为大多数情况下都不会产生竞争
在锁的使用中一般会使用几种原子指令:
- CAS:检查给定指针位置的值和传入的值是否一致,如果一致,就修改
- SWAP:替换指针原位置的值,并返回旧的值
- membar:内存屏障约束了处理器在处理指令时的重排序情况,比如禁止同读操作被重排序到写操作之后
Java中使用 two-word 对象头
- 是 mark word,它包括同步信息,垃圾回收信息、hash code信息
- 指向对象的指针对象
这些指令的花销很昂贵,因为他们的实现通常会耗尽处理器的重排序缓冲区,从而限制了处理器原本能够像流水线一样处理指令的能力。研究数据发现(Eliminating_synchronization-related_atomic_operations_with_biased_locking_and_bulk_rebiasing)原子操作在真实的应用中,比如javac ,会导致性能下降20%。
此处2006年的文章第4段 大概说CAS和fence在操作系统中是序列化处理的,而序列化指令会使CPU几乎停止,终止并禁止任何无需指令,并等待本地存储耗尽。在多核处理器上,这种处理会导致相当大的性能损失
-
另一种优化的方式是使用偏向锁,它不仅认为大多数情况下是没有竞争的,而且在整个的monitor的一生中,都只会有一个线程来执行enter和exit,这样的监视器就很适合偏向于这个线程了。当然如果这时有另外一个线程尝试进入偏向锁,即使没有发生竞争,也需要执行 偏向锁撤销操作
轻量锁
- 当轻量锁通过monitorenter指令获取锁的时候,锁记录肯定会被记录到线程的栈里面去,以表示锁获取操作。锁记录会持有原始对象的mark word和一些必备的元数据来识别锁住的对象。在获取锁的时候,mark word会被拷贝一份到锁记录(这个操作称为 displaced mark word)然后执行CAS操作尝试是的对象的mark word指针指向锁记录。如果CAS成功,当前线程就持有了锁,如果失败,其它线程获取锁,这是锁就“膨胀”,转而使用了操作系统的互斥量和条件,在“膨胀”的过程中,对象本身的mark word会经过CAS操作指向含有mutex和condition的数据结构。
- 当执行unlock的时候,扔通过CAS来操作mark word,如果CAS成功了,说明没有竞争,同时维持轻量锁;如果失败了,锁就处于竞争态,当被持有时,会以一种“非常慢”的方式来正确的释放锁并通知其他等待线程来获取锁
- 同一个线程重新处理的方式很直白,在轻量锁发现要获取的锁已经被当前线程持有的时候,它会存一个0进去,而不对mark word做任何处理,同样在unlock的时候,如果有看到0,也不会更新对象的mark word.并每次重入,都会明确的记录count。
偏向锁的实现
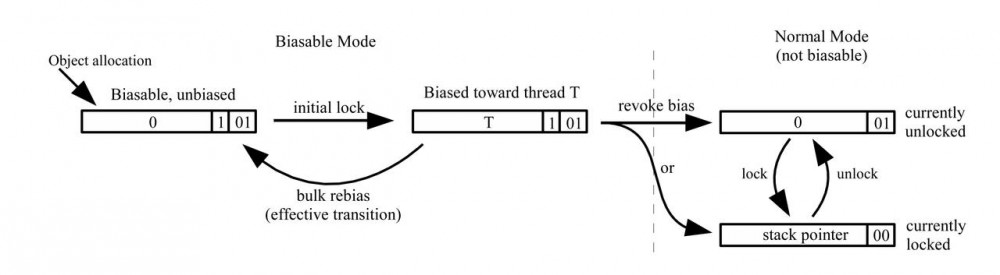
线程指针是NULL(0)表示当前没有线程被偏向这个对象
当分配一个对象并且这个对象能够执行偏向的时候并且还没有偏向时,会执行CAS是的当前线程ID放入到mark word的线程ID区域。
-
如果成功,对象本身就会被偏向到当前线程,当前线程会成为偏向所有者 > 线程ID直接指向JVM内部表示的线程;java虚拟机中则是在最后3bit填充0x5表示偏向模式。
-
如果CAS失败了,即另一个线程已经成为偏向的所有者,这意味着这个线程的偏向必须撤销。对象的状态会变成轻量锁的模式,为了达到这一点,尝试把对象偏向于自己的线程必须能够操作偏向所有者的栈,为此需要全局安全点已经触达(没有线程在执行字节码)。此时偏向拥有者会像轻量级锁操作那样,它的堆栈会填入锁记录,然后对象本身的mark word会被更新成指向栈上最老的锁记录,然后线程本身在安全点的阻塞会被释放 > 如果没有被原有的偏向锁持有者持有,会撤销对象重新回到可偏向但是还没有偏向的状态,然后尝试重新获取锁。如果对象当前锁住了是进入轻量锁,如果没有锁住是进入未被锁定的,不可偏向对象
下一个获取锁的操作会与检测对象的mark word,如果对象是可偏向的,并且偏向的所有者是当前那线程,会没有任何额外操作而立马获取锁。
这个时候偏向锁的持有者的栈不会初始化锁记录,因为对象偏向的时候,是永远不会检验锁记录的
unlock的时候,会测试mark word的状态,看是否仍然有偏向模式。如果有,就不会再做其它的测试,甚至不需要管线程ID是不是当前线程ID
这里通过解释器的保证monitorexit操作只会在当前线程执行,所以这也是一个不需要检查的理由
不适用偏向锁的模式
- 生产生-消费者模式,会有过个线程参与竞争;
- 一个线程分配多个对象,然后给每个对象执行初始的同步操作,再有其它线程来处理子流程
批量回到可偏向状态还是撤销可偏向?
经验发现为特定的数据结构选择性的禁用偏向锁(Store-fremm biased lock SFBL)来避免不合适的情况是合理的。为此需要考虑每个数据结构到底是执行撤销偏向的消耗小还是重新回到可偏向的状态消耗下。一种启发式的方式来决定到底是执行那种方式,在每个类的元数据里面都会包含一个counter和时间戳,每次偏向锁的实例执行一次偏向撤销,都会自增,时间戳用于记录上次执行bulk rebias的时间。
撤销计数并统计那些处于可偏向但是未偏向状态的撤销,这些操作的撤销只需要一次CAS就可以
counter本身有两个阈值,一个是bulk rebias阈值,一个是bulk revocation。刚开始的时候,这种启发式的算法可以单独的决定执行rebias还是revoke,一单bulk rebias的阈值达到,就会执行bulk rebias,转移到 rebiasable状态 time阈值用来重置撤销的计数counter,如果自从上次执行bulk bias已经超过了这个阈值时间,就会发生counter的重置。
这意味着从上次执行bulk rebias到现在并没有执行多次的撤销操作,也就是说执行bias仍然是个不错的选择
但是如果在执行了bulk rebias之后,在时间阈值之内,仍然一直有撤销数量增长,一旦达到了bulk revocation的阈值,就会执行bulk revocation,此时这个类的对象不会再被允许使用偏向锁。
Hotspot中的阈值如下 Bulk rebias threshold 20 Bulk revoke threshold 40 Decay time 25s
撤销偏向本身是一个消耗很大的事情,因为它必须挂起线程,遍历栈找到并修改lock records(锁记录)
最明显的查找某个数据结构的所有对象实例的方式就是遍历堆,这种方式在堆比较小的时候还可以,但是堆变大就显得性能不好。为类解决这个为题,使用 epoch 。 epoch是一个时间戳,用来表明偏向的合法性,只要这个数据接口是可偏向的,那么就会在mark word上有一个对应的epoch bit位
这个时候,一个对象被认为已经偏向了线程T必须满足两个条件,1: mark word中偏向所有这的标记必须是这个线程,2:实例的epoch必须是和数据结构的epoch相等 epoch本身的大小是限制的,也就是有可能出现循环,但这并不影响方案的正确性
通过这种方式,类C的bulk rebiasing操作会少去很多的花销。具体操作如下
- 增大类C的epoch,它本身是一个固定长度的integer,和对象头中的epoch拥有一样的bit位数
- 扫描所有的线程栈来定位当前类C的实例中已经锁住的,更新他们的epoch为类C的新的epoch或者是,根据启发式策略撤销偏向
这样就不用扫描堆了, 对于那些没有被改变epoch的实例(和类的epoch不同),会被自动当做可偏向但是还没有偏向的状态
这种状态可看做 rebiaseable
膨胀与偏向源码
当前HotSpot虚拟机的实现
批量撤销本身存在着性能问题,一般的解决方式如下
- 添加epoch,如前所诉
- 线程第一次获取的时候不偏向,而是在执行一定数量后都有同一个线程获取再偏向
- 允许锁具有永远改变(或者很少)的固定偏向线程,并且允许非偏向线程获取锁而不是撤销锁。
这种方式必须确保获取锁的线程必须确保进去临界区之前没有其它线程持有锁,并且不能使用 read-modify-write的指令,只能使用read和write
当前Hotspot JVM中的在32位和64位有不同的形式 64bit为
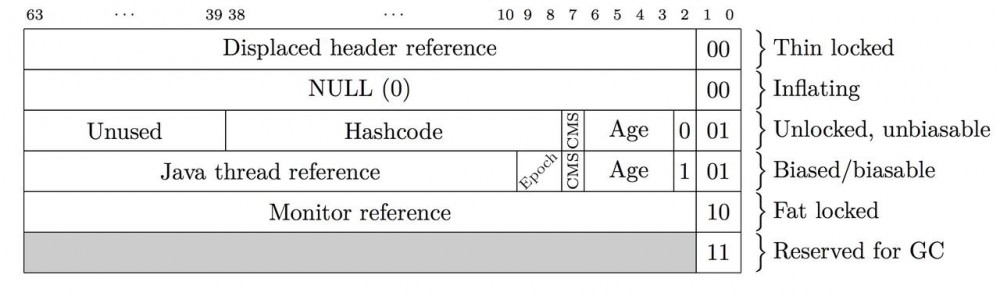
32bit为
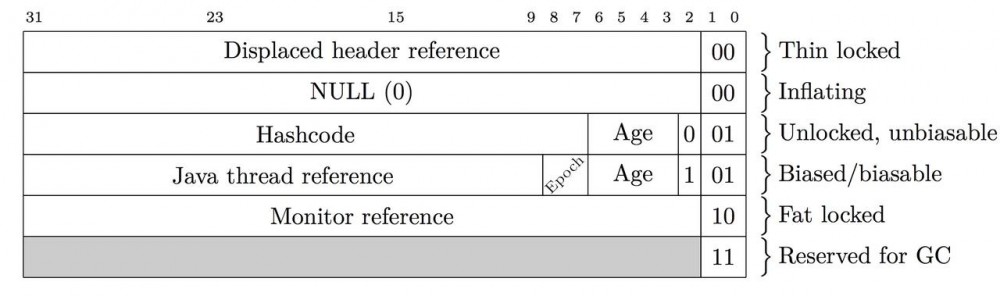
轻量锁(thin locks),细节如前所述。它在HotSpot中使用displaced header的方式实现,又被称作栈锁
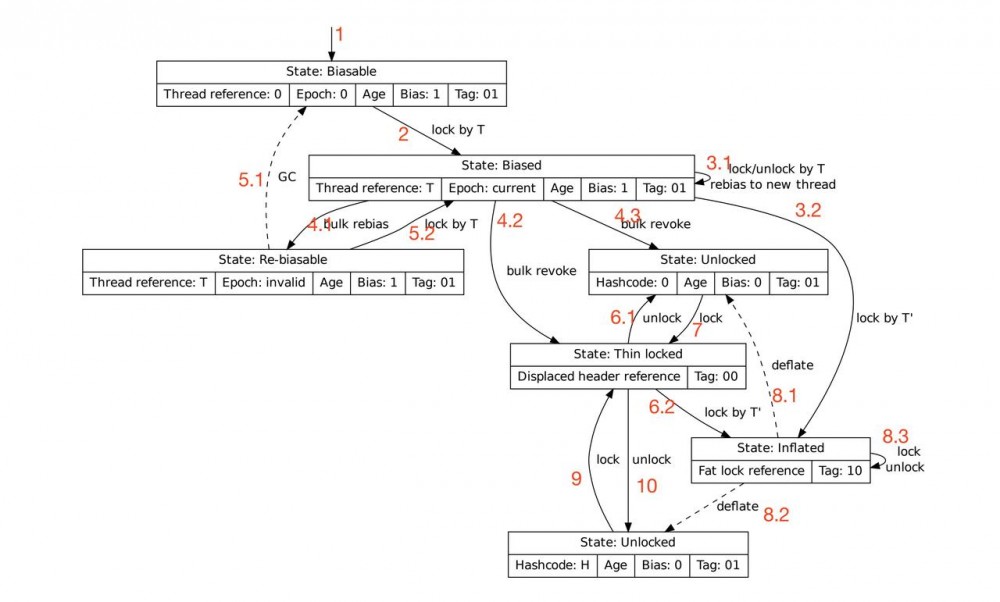
mark完整的状态转换关系如下
-
刚分配对象,此时对象是可偏向并且未偏向的
-
对象偏向于线程T,并记下epoch
-
此时有新线程来竞争
- 3.1一种策略是T执行对应的unlock,并重新分配给新的线程,以便不需要执行撤销操作
- 3.2 如果已经偏向的对象被其它线程通过wait或者notify操作了,里面进入膨胀装态,使用重量锁
-
此时有新的线程来竞争,一种策略是使用启发式的方式来统计撤销的次数
- 4.1 当撤销达到bulk rebias的阈值时,执行bulk rebias
- 4.2 当撤销达到bulk revoke,并且此时所仍然被持有(原偏向锁持有者),转向轻量锁(hashcode的计算依赖于膨胀来支持修改displaced mark word)
- 4.3 当撤销达到bulk revoke,并且此时所没有被持有(原偏向锁持有者),转向未被锁定不可偏向的状态,此时没有进行hashcode计算
-
对于经过bulk rebias的对象,检查期间没有锁定的实例,它的epoch会和class的不一样,变成过期,但是可以偏向
- 5.1 如果 发生垃圾回收,lock会被初始化成可偏向但未偏向的状态(这也可以降低epoch循环使用的影响)
- 5.2 如果重新被线程获取偏向锁,回到偏向锁获取状态
-
处于轻量锁状态,它可能没有hashcode计算,可能有,这依赖于inflat
- 6.1 没有hashcode,此时解锁回到没有hashcode计算的不可偏向的状态
- 6.2 又被其它线程占有,转移到重量锁(比如使用POXIS操作系统的mutex和condition)
-
未被锁定不可偏向的状态同时没有hashcode计算加锁后转移到轻量锁
-
处于重量锁状态
- 8.1 8.2 如果在Stop-The-Word期间没有竞争了,就可以去膨胀(STW期间没有其它线程获取和释放锁,是安全的),根据是否有hashcode,退到对应的状态(就是就退回使用偏向锁 )
- 8.3 重量锁期间的lock/unlock仍然处于重量锁
-
计算过hashcode,再加锁和解锁对应状态转换(9.10)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

