Mybatis缓存原理
概述
Mybatis 是目前Java开发中最常用的轻量级ORM框架。正如大多数持久层框架一样,MyBatis同样提供了一级缓存和二级缓存的特性以提高性能。两种缓存的粒度是一样的,都对应一条sql查询语句。但二者的生命周期不同,一级缓存的生命周期是 SqlSession 对象的使用期间,随着SqlSession对象的死亡而消失;二级缓存的生命周期是同外部缓存生命周期一样长的;并且是首先查询二级缓存,然后再查询一起缓存。了解Mybatis缓存原理,能够使我们在开发中避免踩一些坑。
一级缓存
默认情况下一级缓存是开启的,且是不能关闭的。一级缓存是指SqlSession级别的缓存,当在同一个SqlSession中执行相同的SQL语句查询时,第二次以后的查询不会从数据库查询,而是直接从sqlSession中的本地缓存获取。
通常我们会使用Spring集成Mybatis通过mapper接口进行数据库操作。此时SqlSession的生命周期会和Spring事物一致。如果不是在事物中执行查询则每次都会新建SqlSession查询完之后就会销毁,否则会复用同一个通过ThreadLocal与事物进行了绑定的SqlSession。
有时在一个复杂的业务方法事物中,我们会拆分为多个子方法处理不同的子逻辑,这样可能会导致查询同一个对象多次,一级缓存的方案优化这部分场景,如果是相同的SQL语句且未执行过update,最终会命中一级缓存,避免多次直接查询数据库,提高性能。
对SqlSession的操作Mybatis内部都是通过Executor来执行的。Executor的生命周期和SqlSession是一致的。Mybatis在Executor中创建了本地缓存(一级缓存)。如下图: 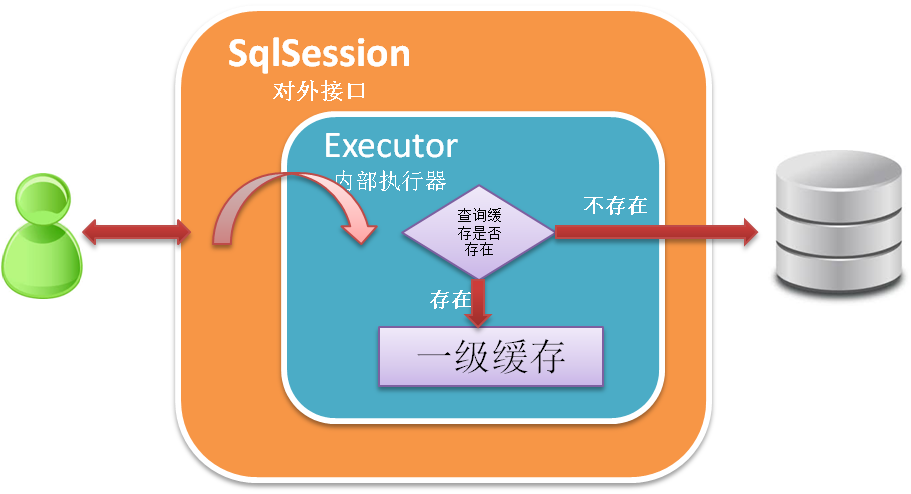
所有Executor都是继承自BaseExecutor,一级缓存的创建就在此类构造函数中:
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
this.deferredLoads = new ConcurrentLinkedQueue<DeferredLoad>();
//Mybatis一级缓存,在创建SqlSession->Executor时候动态创建,随着sqlSession销毁而销毁
this.localCache = new PerpetualCache("LocalCache");
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
this.wrapper = this;
}
一级缓存的实现很简单,不能像二级缓存那样设置淘汰规则过期时间等,底层使用HashMap存储
一级缓存的配置方式:
<setting name="localCacheScope" value="SESSION"/>
scope有SESSION或STATEMENT两个选项,默认为SESSION级别,即在一个SqlSession中执行的所有语句,都会共享这一个缓存。STATEMENT级别可以理解为缓存只对当前执行的这一个Statement有效,每次执行完查询就会清空缓存,相当一级缓存失效
继续看下Executor中是怎么使用缓存的。具体入口为BaseExecutor的query方法:
//SqlSession.select*会调用此方法(总是先查询一级缓存,缓存中不存在再查询数据库)
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
// 通过sql,参数构建缓存的key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
首先会将MappedStatement的Id、对应sql的offset、limit、Sql本身以及Sql中的参数传入了CacheKey这个类,最终构成CacheKey。 CacheKey中有hashcode,checksum和count,updateList等属性,两个CacheKey相等必须hashcode,checksum和count都相等,且updateList中的元素一一对应相同
对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
1. 传入的statementId (namespace+mapperId)分别对应接口名和方法名 2. 查询时要求的结果集中的结果范围 (结果的范围通过rowBounds.offset和rowBounds.limit表示); 3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() ) 4. 传递给java.sql.Statement要设置的参数值,包括顺序
继续往下看:
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//先清一级缓存,再查询,但仅仅查询堆栈为0才清,为了处理递归调用
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//查询localCache缓存
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//从数据库中查询数据
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 如果配置的一级缓存scope为STATEMENT而非SESSION则,每次清空本地缓存,相当于一级缓存被禁用
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
如果缓存未命中,实际查询数据库:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 由SimpleExecutor、BatchExecutor、ReuseExecutor实现具体的数据库查询方式
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将结果放入本地缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
如果遇到insert/delete/update方法,一级缓存就会被清空。 SqlSession的delete和insert方法统一会走Executor的update流程。
在BaseExecutor的update方法中会清空本地缓存:
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空本地缓存
clearLocalCache();
return doUpdate(ms, parameter);
}
实验1
一级缓存默认配置,非事物中多次执行相同语句:  可以看到两次查询返回的不是同一个对象,两者的hashCode不同,两次都真正查询了数据库。
可以看到两次查询返回的不是同一个对象,两者的hashCode不同,两次都真正查询了数据库。
实验2
一级缓存默认配置,事物中多次执行相同语句:  可以看到前两次查询返回的是同一个对象,且两者hashCode相同。 之后执行了一次update,一级缓存被清空,再次查询访问了数据库返回的是不同的对象
可以看到前两次查询返回的是同一个对象,且两者hashCode相同。 之后执行了一次update,一级缓存被清空,再次查询访问了数据库返回的是不同的对象
二级缓存
如果需要在多个SqlSession间共享缓存,则需要使用Myabtis二级缓存。二级缓存具体实现可由Redis,EhCache等外部缓存代替HashMap,功能更丰富,容量更大
二级缓存实现由CachingExecutor装饰BaseExecutor的具体子类,默认是SimpleExecutor。首先会在CachingExecutor查询二级缓存中是否存在,实现了二级缓存的查询和写入功能,若查询不存在则委托具体职责给delegate Executor。查询执行的流程为 二级缓存 -> 一级缓存 -> 数据库
具体类关系图如下图所示: 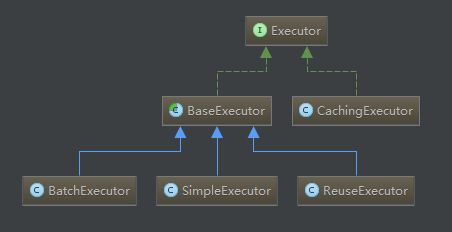
二级缓存的使用只需要完成三步:
1、 mapper返回的实体需要可序列化
2、 Myabtis配置文件中开启二级缓存,生成的执行器为CachingExecutor
<setting name="cacheEnabled" value="true"/>
3、 在映射XML中配置cache或者cache-ref(代表引用别的命名空间的Cache配置,两个命名空间的操作使用的是同一个Cache)
<cache type="com.dianwoda.RedisCache eviction="LRU" flushInterval="60000" size="512""></cache> type: org.apache.ibatis.cache.Cache的实现类 eviction: 回收的策略,有FIFO,LRU flushInterval:自动刷新缓存时间间隔,单位毫秒 (仅对PerpetualCache有效,底层为HashMap) size:最多缓存对象个数上限 (仅对PerpetualCache有效) readOnly:是否只读,若配置可读写,则需要对应的实体类能够序列化。 (仅对PerpetualCache有效) blocking 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。 (仅对PerpetualCache有效)
这里使用redis作为cache实际实现,每个mapper namespace使用一个Redis Hash结构存储:
public class MybatisCache implements Cache {
private RedisTemplate<String, Object> redisTemplate;
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private String id;
public MybatisCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public void putObject(Object key, Object value) {
getRedisTempalte().opsForHash().put(id, key.toString(), value);
}
@Override
public Object getObject(Object key) {
return getRedisTempalte().opsForHash().get(id, key.toString());
}
@Override
public Object removeObject(Object key) {
getRedisTempalte().opsForHash().delete(id, key.toString());
return null;
}
@Override
public void clear() {
getRedisTempalte().delete(id);
}
@Override
public int getSize() {
return Math.toIntExact(getRedisTempalte().opsForHash().size(id));
}
@Override
public ReadWriteLock getReadWriteLock() {
return readWriteLock;
}
public RedisTemplate getRedisTempalte() {
if (redisTemplate != null) {
return redisTemplate;
}
redisTemplate = SpringCtxUtils.getBean("redisTemplate");
return redisTemplate;
}
}
cache的初始化在 org.mybatis.spring.CacheBuilder的build方法中
源码分析
一次select首先会执行CachingExecutor的query方法:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
Cache cache = ms.getCache() 会获取对应MappedStatement中配置的Cache  cache应用了装饰模式,LoggingCache提供日志功能,并记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志。
cache应用了装饰模式,LoggingCache提供日志功能,并记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志。
flushCacheIfRequired 然后判断是否要强制刷新缓存。如果select sql设置了 flushCache="true" 则会在select之后刷新缓存。insert/update/delte将会强制刷新缓存。
对于具体配置的Cache的操作是委托给TransactionalCacheManager进行操作的,其中持有了一个Map
private Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
TransactionalCache也实现了Cache接口,装饰了具体的初始生成的cache,作用是如果事务提交,对缓存的操作才会生效,如果事务回滚或者不提交事务,则不对缓存产生影响。
如果不调用commit方法的话,由于TranscationalCache的作用,并不会对二级缓存造成直接的影响。在commit时依据标志位、entriesToAddOnCommit等临时数据委托给装饰的Cache进行清空缓存,方式缓存对象等操作
rollback仅仅清空标志位、entriesToAddOnCommit等临时数据,不影响实际二级缓存
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
public void rollback() {
unlockMissedEntries();
reset();
}
继续往下走,如果查询语句开启了useCache并且resultHandler为null则会查询二级缓存 尝试从tcm中获取缓存的数据
List<E> list = (List<E>) tcm.getObject(cache, key);
这个方法会将获取值的职责不断传递给每个装饰者,最终到达具体的实现类MybatisCache。如果没有命中二级缓存,会把key加入Miss集合,这个主要是为了统计命中率。 如果查询不到数据,在二级缓存执行流程后就会进入一级缓存的执行流程。如果从一级缓存或数据库中查询到数据,则调用tcm.putObject方法,往二级缓存中放入值
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
由于任何的更新修改删除操作都会导致一个mapper namespace下的所有缓存被清空,在清空频繁的情况下,性能是较差的。Mybatis二级缓存的粒度为mapper namespace级别,粒度较粗适用于读多写少的情况,且不太适合连表查询的sql,不过对业务代码入侵较少。
总结
本文介绍了MyBatis一二级缓存的基本概念,并简单对其原理机制进行了分析。个人建议MyBatis二级缓存特性在生产环境中进行关闭,一级缓存可以开启对性能影响不大,仅作为一个ORM框架使用可能较为合适。
reference
- https://zhuanlan.zhihu.com/p/33179093
- https://blog.csdn.net/qq_25689397/article/details/52066179
- https://www.cnblogs.com/xrq730/p/6991655.html
正文到此结束
- 本文标签: dist queue executor HashMap db UI 空间 mybatis build Logging cache bug tab 配置 时间 list ACE sqlsession id 源码 map 代码 value 总结 生命 myabtis MQ 递归 apache sql SDN key final 删除 mapper iBATIS 缓存 update cat NSA XML 开发 http ORM IO Statement java 数据库 IDE Select mybatis缓存 统计 bean 一级缓存 JDBC spring redis HTML spring集成 src Action 二级缓存 session https 数据 App 参数
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

