由Spring应用的瑕疵谈谈DDD的概念与应用(一)
Spring 框架已经成为构建企业级 Java 应用事实上的标准了,众多的企业项目都构建在 Spring 项目及其子项目之上,特别是 Java Web 项目,很多都使用了 Spring 并且遵循着 Web、Service、Dao 这样的分层原则,下层向上层提供服务;不过Petri Kainulainen在其博客中却指出了众多 Spring Web 应用的最大瑕疵。
多数有经验的程序开发者都应该听说过DDD,并且尝试过将其应用在自己的项目中。不知你是否遇到过这样的场景:你创建了一个资源库(Repository),但一段时间之后发现这个资源库和传统的DAO越来越像了,你开始反思自己的实现方式是正确的吗?或者,你创建了一个聚合,然后发现这个聚合是如此的庞大,它为什么引用了如此多的对象,难道又是我做错了吗?
本文将会谈谈有关领域驱动设计,和领域驱动设计中使用贫血、失血和充血模型。
Spring 应用的瑕疵
现在大部分应用Spring框架的Java Web应用都相当关注单一职责原则和关注分离原则,但是在此之上却诞生了一些不太好的反模式和设计原则,比如:
- 领域模型对象只是用来存储应用的数据(领域模型使用了贫血模型这种反模式)。
- 业务逻辑位于服务层中,管理域对象的数据。
- 在服务层中,应用的每个实体对应一个服务类。
使用 Spring 框架构建应用的开发者很乐于谈论依赖注入的好处。但遗憾的是,他们很多人并没有在其应用中很好地利用其优势,如单一职责原则和关注分离原则。如果仔细看看基于 Spring 的 Web 应用,你会发现很多都是使用如下这些常见且错误的设计原则来实现的:
这类设计原则的应用非常广泛,我现在所在的Java Web项目就是使用这样的设计原则进行架构设计的,基本都是常见的三层或多层架构,他们大概是什么样的呢?
- Web层(俗称展现层吧,Presentation Layer):接收用户输入,将数据传至服务层;
- 服务层(Service Layer,可以叫Business Logic Layer):事务边界,处理业务逻辑、权限管理与授权,并与存储层通信;
- 存储层(Data access layer):与数据库进行通信,对数据进行持久化。
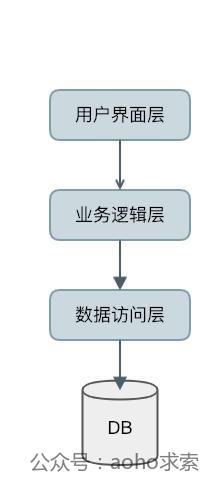
但是发现什么没有?问题出在了服务层,他承受了太多的职责,像事务管理、业务逻辑、权限检查等等,这违反了单一职责原则和关注分离原则,并且产生了大量的依赖和循环依赖。当业务复杂度上升时,服务层所包含的代码将会非常庞大和复杂,直接导致了测试成本的上升。服务层主要有两个问题:
- 应用的业务逻辑来自于服务层。
业务逻辑散落在服务层。如果需要查看某个业务规则是如何实现的,我们需要先找到它。此外,如果有多个服务类都需要相同的业务规则,那么会将这个业务规则从一个服务复制到另一个服务中,大量的代码重复。
- 每个领域模型类在服务层中都有一个服务类。
这违背了单一职责原则:单一职责原则表明每个类都应该只有一个职责,这个职责应该完全被这个类所封装。它的所有服务都应该与这个职责保持一致。
如何改善现状,下面具体介绍领域驱动设计的相关概念和实施策略。
领域驱动设计(DDD)
DDD总体结构分为四层: Infrastructure(基础实施层),Domain(领域层),Application(应用层),Interfaces(表示层,也叫用户界面层或是接口层),各个层面的作用下面介绍。
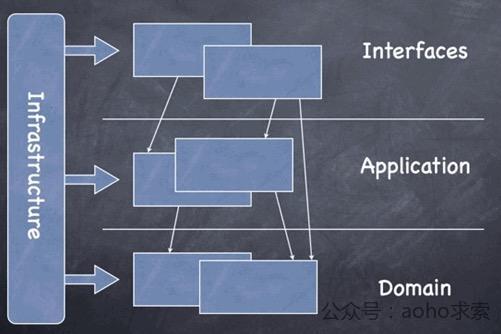
- 用户界面(表现层):负责给用户展示信息,并解释用户命令。
- 应用层:该层协调应用程序的活动。不包括任何业务逻辑,不保存业务对象的状态,但能保存应用程序任务过程的状态。
- 领域层:这一层包括业务领域的信息。业务对象的状态在这里保存。业务对象的持久化和它们的状态可能会委托给基础设施层。
- 基础设施层:对其它层来说,这一层是一个支持性的库。它提供层之间的信息传递,实现业务对象的持久化,包含对用户界面层的支持性库等。
基本概念
实体(Entity)
当一个对象由其标识(而不是属性)区分时,这种对象称为实体(Entity)。比如当两个对象的标识不同时,即使两个对象的其他属性全都相同,我们也认为他们是两个完全不同的实体。
值对象(Value Object)
当一个对象用于对事物进行描述而没有唯一标识时,那么它被称作值对象。因为在领域中并不是任何时候一个事物都需要有一个唯一的标识,也就是说我们并不关心具体是哪个事物,只关心这个事物是什么。比如下单流程中,对于配送地址来说,只要是地址信息相同,我们就认为是同一个配送地址。由于不具有唯一标示,我们也不能说”这一个”值对象或者”那一个”值对象。
领域服务(Domain Service)
一些重要的领域行为或操作,它们不太适合建模为实体对象或者值对象,它们本质上只是一些操作,并不是具体的事物,另一方面这些操作往往又会涉及到多个领域对象的操作,它们只负责来协调这些领域对象完成操作而已,那么我们可以归类它们为领域服务。它实现了全部业务逻辑并且通过各种校验手段保证业务的正确性。同时呢,它也能避免在应用层出现领域逻辑。理解起来,领域服务有点facade的味道。
聚合及聚合根(Aggregate,Aggregate Root)
聚合是通过定义领域对象之间清晰的所属关系以及边界来实现领域模型的内聚,以此来避免形成错综复杂的、难以维护的对象关系网。聚合定义了一组具有内聚关系的相关领域对象的集合,我们可以把聚合看作是一个修改数据的单元。
聚合根属于实体对象,它是领域对象中一个高度内聚的核心对象。(聚合根具有全局的唯一标识,而实体只有在聚合内部有唯一的本地标识,值对象没有唯一标识,不存在这个值对象或那个值对象的说法)
若一个聚合仅有一个实体,那这个实体就是聚合根;但要有多个实体,我们就要思考聚合内哪个对象有独立存在的意义且可以和外部领域直接进行交互。
工厂(Factory)
DDD中的工厂也是一种封装思想的体现。引入工厂的原因是:有时创建一个领域对象是一件相对比较复杂的事情,而不是简单的new操作。工厂的作用是隐藏创建对象的细节。事实上大部分情况下,领域对象的创建都不会相对太复杂,故我们仅需使用简单的构造函数创建对象就可以。隐藏创建对象细节的好处是显而易见的,这样就可以不会让领域层的业务逻辑泄露到应用层,同时也减轻应用层负担,它只要简单调用领域工厂来创建出期望的对象就可以了。
仓储(Repository)
资源仓储封装了基础设施来提供查询和持久化聚合操作。这样能够让我们始终关注在模型层面,把对象的存储和访问都委托给资源库来完成。它不是数据库的封装,而是领域层与基础设施之间的桥梁。DDD 关心的是领域内的模型,而不是数据库的操作。
DDD设计
DDD 概念理解起来有点抽象,这个有点像设计模式,感觉很有用,但是自己开发的时候又不知道怎么应用到代码里面,或者生搬硬套后自己看起来都很别扭。DDD的战略设计主要包括领域/子域、通用语言、限界上下文和架构风格等概念。
领域和子域
现实世界中,领域包含了问题域和解系统。一般认为软件是对现实世界的部分模拟。在DDD中,解系统可以映射为一个个限界上下文,限界上下文就是软件对于问题域的一个特定的、有限的解决方案。
在日常开发中,我们通常会将一个大型的软件系统拆分成若干个子系统。这种划分有可能是基于架构方面的考虑,也有可能是基于基础设施的。但是在DDD中,我们对系统的划分是基于领域的,也即是基于业务的。
限界上下文
一个由显示边界限定的特定职责。领域模型便存在于这个边界之内。在边界内,每一个模型概念,包括它的属性和操作,都具有特殊的含义。
将一个限界上下文中的所有概念,包括名词、动词和形容词全部集中在一起,我们便为该限界上下文创建了一套通用语言。通用语言是一个团队所有成员交流时所使用的语言,业务分析人员、编码人员和测试人员都应该直接通过通用语言进行交流。
对于上文中提到的各个子域之间的集成问题,其实也是限界上下文之间的集成问题。在集成时,我们主要关心的是领域模型和集成手段之间的关系。比如需要与一个REST资源集成,你需要提供基础设施(比如Spring 中的RestTemplate),但是这些设施并不是你核心领域模型的一部分,你应该怎么办呢?答案是防腐层,该层负责与外部服务提供方打交道,还负责将外部概念翻译成自己的核心领域能够理解的概念。当然,防腐层只是限界上下文之间众多集成方式的一种,另外还有共享内核、开放主机服务等,具体细节请参考《实现领域驱动设计》原书。限界上下文之间的集成关系也可以理解为是领域概念在不同上下文之间的映射关系,因此,限界上下文之间的集成也称为上下文映射图。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

