jvm垃圾回收算法
前言
java相较于c、c++语言的优势之一是自带垃圾回收器,程序开发人员不用手动管理内存,内存的分配和释放完全由gc(Garbage Collector)来做,极大地提高了软件开发效率及程序健壮性(手动管理内存容易造成内存泄漏)。凡事皆有两面性,java gc在给我们带来内存管理便捷性的同时,也面临STW(Stop The World)影响程序吞吐的缺陷。作为java开发人员,只有深入理解jvm垃圾回收的机制,才能在程序性能出现瓶颈时,更好的对程序进行优化。笔者通过拜读《深入理解java虚拟机》,总结书中内容,给大家分享下java虚拟机常见的垃圾回收算法。
垃圾确定
在垃圾回收之前,jvm需要确定哪些对象已死,即需要当做垃圾被回收。垃圾确认的方法传统的有引用计数法:用一个引用计数器来标记对象当前的引用次数,当引用计数为0时,对象可回收。这种方法有个弊端是无法解决循环引用的问题,如两个对象相互引用则它们永远不会释放。另外一种方法是可达性分析算法,目前主流的语言(java、c#、golang等)都是采用这种方法来判定一个对象是否存活。可达性分析算法的思路是:将一系列根对象作为起点,沿着这些起点向下搜索,搜索经过的所有路径成为引用链,没有在引用链中的对象则为不可达对象,这类对象会被判断为可回收对象。可达性分析图如下:
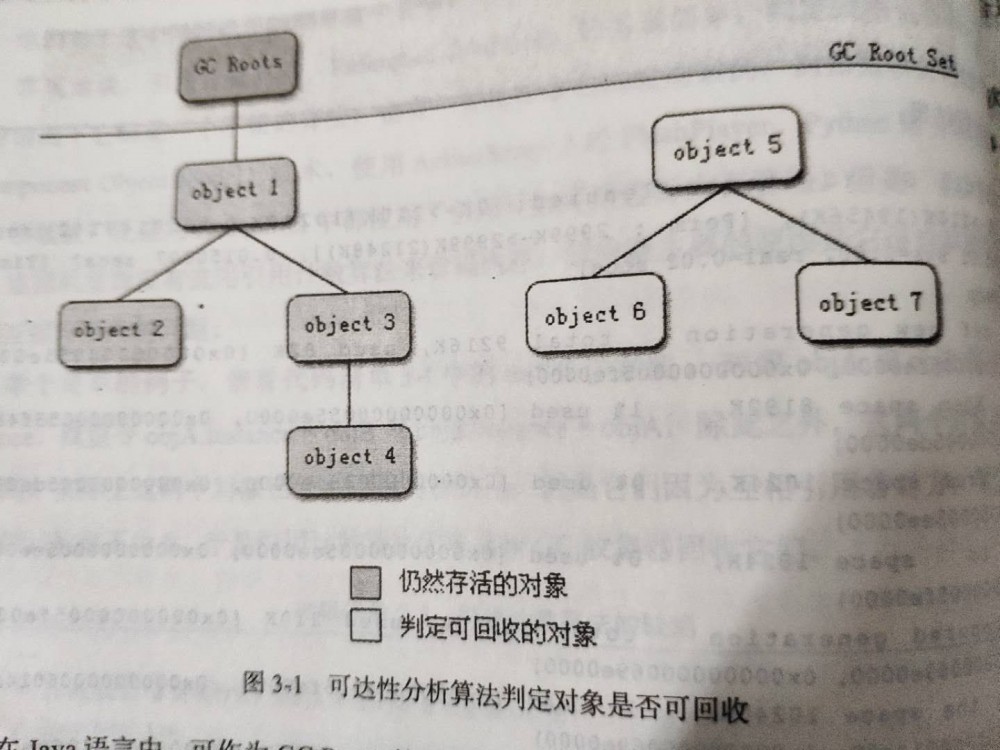
可达性分析
标记-清除算法(Mark-Sweep)
标记清除算法是最基础的收集算法,顾名思义,算法分为两个阶段:首先标记需要回收的对象,然后统一回收所有被标记的对象。这种垃圾回收算法比较简单,但是存在两个不足之处:一个是效率问题,标记和清除都需要扫描整个内存空间的对象,效率较低;另一个是标记清除后会产生大量的内存碎片。标记-清除算法流程如下所示:
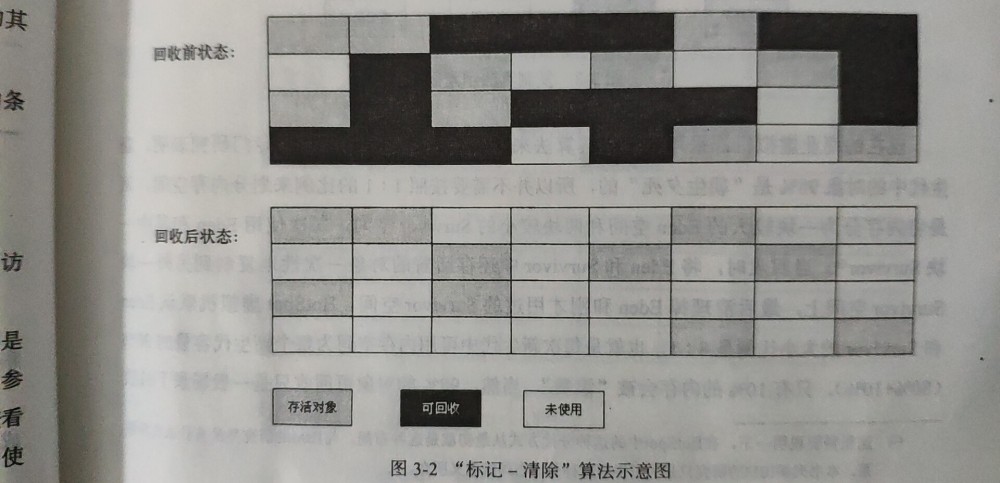
标记-清除算法
复制算法
为了解决上面的效率和内存碎片问题,有人提出了“复制”算法,它的思路是将内存一分为二,每次分配对象时只使用其中一半内存空间,当一块内存空间用完时,就将该块内存空间上存活的对象复制到另外一块内存上,然后将已使用过的内存空间一次清理掉,这样每次只对一半的内存进行回收,同时也解决了内存碎片的问题。同样,复制算法也有很明显的缺点:1. 牺牲了一半的内存空间,内存利用率最大也就50%;2. 当内存中存活的对象较多时,会进行大量的复制操作,效率会较低。复制算法的执行过程如下所示:
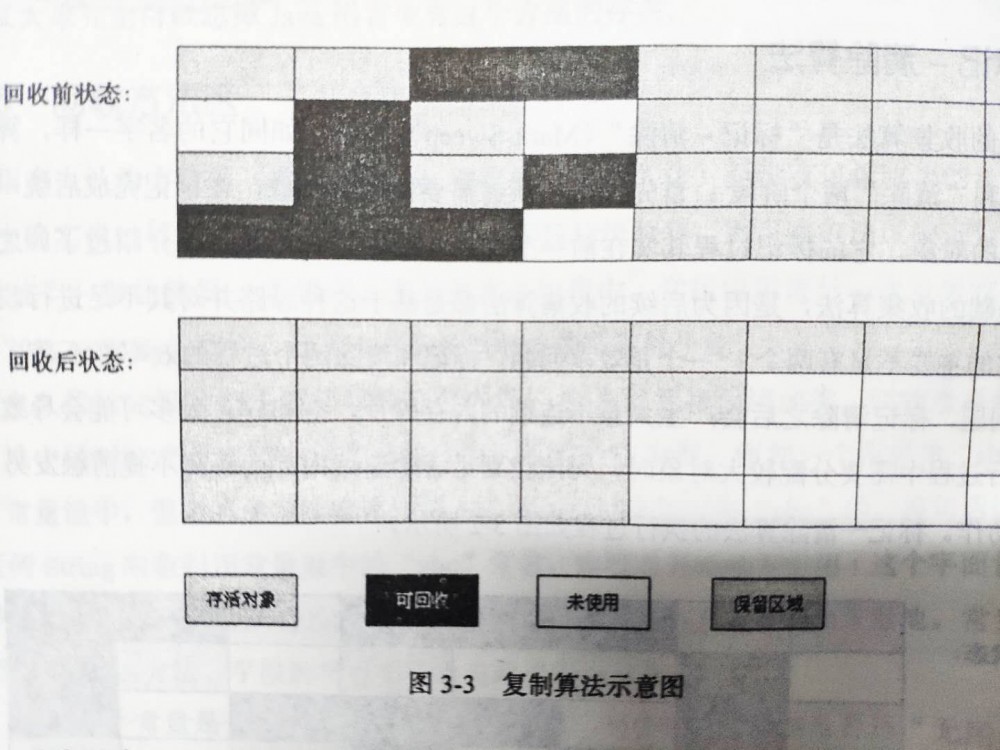
复制算法
标记-整理算法(Mark-Compact)
复制算法在存在大量存活对象的情况下效率低下,更关键的是50%的内存空间得不到利用,如果存活对象过多,内存空间可能不够,则需要额外的空间作为担保,因此,对于老年代不适合使用这种算法(新生代有老年代做担保)。
因此,根据老年代的特点,有人提出了“标记-整理”算法,标记-整理算法和标记-清除算法的第一步相同,即对所有需要回收的对象进行标记,不同的是,标记-整理算法在第二阶段并不是直接对可回收的对象进行清理,而是将所有存活的对象向一端移动,然后一把清理掉存活边界之外的内存。这种算法结合了标记-清除和复制算法的思想,即未浪费内存也避免了内存碎片的产生。“标记-整理”算法如下所示:
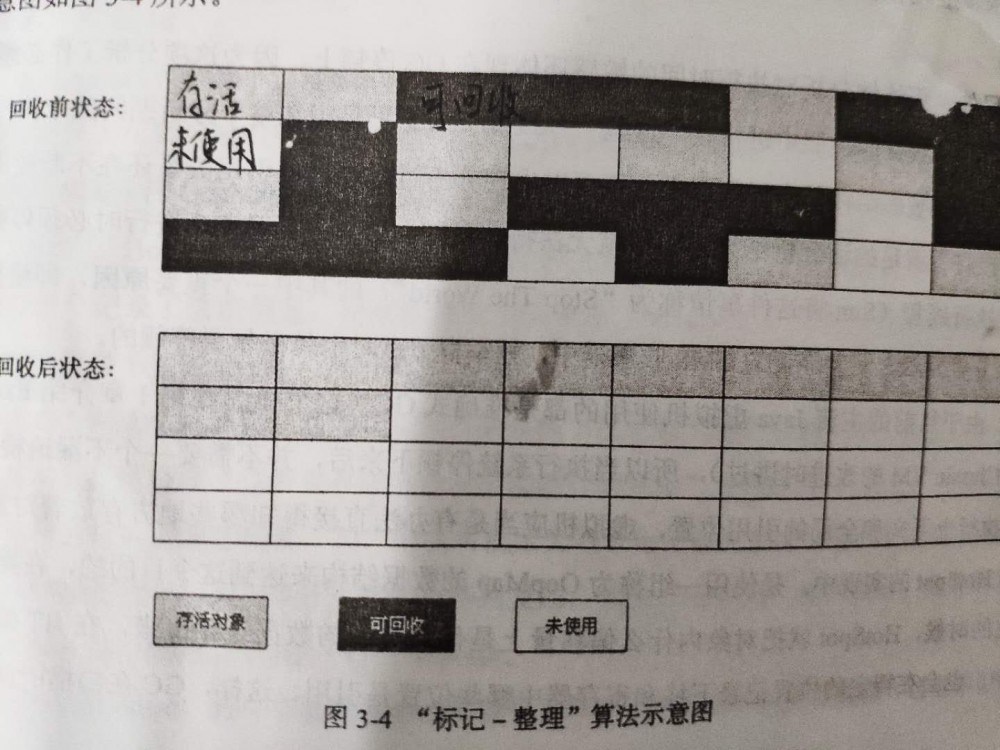
标记-整理算法
分代收集算法
分代收集并没有什么创新之处,这种算法只是将jvm堆内存分为不同的区域,再根据区域的特点采用不同的垃圾回收算法。一般分为新生代和老年代,新生代在再细分为Eden和Survivor区(8:1),在新生代中,对象的存活率低,因此采用“复制”算法,将Edian区存活的对象复制到Survivor区,而老年代中对象存活率高且没有额外的中间做担保,因此采用“标记-清除”或者“标记-整理”算法来进行垃圾回收。
总结
本文抛砖引玉,介绍了目前主流的垃圾回收算法的原理并未对主流的垃圾回收器的实现就行剖析,更详细的细节可以研读《深入理解java虚拟机》。笔者后续将分享主流的jvm实现原理,同时欢迎大家多多交流。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

