SOFARPC 性能优化实践(下)| SOFAChannel#3 直播整理
<SOFA:Channel/>,有趣实用的分布式架构频道。
本次是 SOFAChannel 第三期,SOFARPC 性能优化(下),进一步分享 SOFARPC 在性能上做的一些优化。
本期你将收获:
- 如何控制序列化和反序列化的时机;
- 如何通过线程池隔离,避免部分接口对整体性能的影响;
- 如何进行客户端权重调节,优化启动期和故障时的性能;
- 服务端 Server Fail Fast 支持,减少无效操作;
- 在 Netty 内存操作中,如何优化内存使用。
欢迎加入直播互动钉钉群:23127468,不错过每场直播。

大家好,今天是 SOFAChannel 第三期,欢迎大家观看。
我是来自蚂蚁金服中间件的雷志远,花名碧远,目前负责 SOFARPC 框架的相关工作。在上一期直播中,给大家介绍了 SOFARPC 性能优化方面的关于自定义协议、Netty 参数优化、动态代理等的优化。
往期的直播回顾,可以在文末获取。 本期互动中奖名单:
今天我们会从序列化控制、内存操作优化、线程池隔离等方面来介绍剩余的部分。
序列化优化
上次介绍了序列化方式的选择,这次主要介绍序列化和反序列化的时机、处理的位置以及这样的好处,如避免占用 IO 线程,影响 IO 性能等。
上一节,我们介绍的 BOLT 协议的设计,回顾一下:
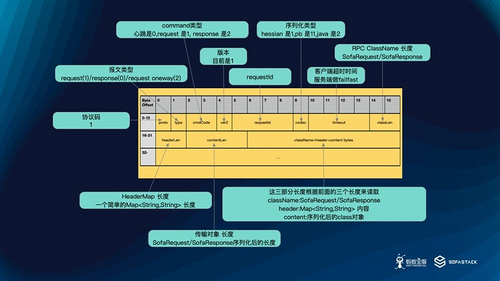
可以看到有这三个地方不是通过原生类型直接写的:ClassName,Header,Content 。其余的,例如 RequestId 是直接写的,或者说跟具体请求对象无关的。所以在选择序列化和反序列化时机的时候,我们根据自己的需求,也精确的控制了协议以上三个部分的时机。
对于序列化
serializeClazz 是最简单的:
byte[] clz = this.requestClass.getBytes(Configs.DEFAULT_CHARSET);复制代码
直接将字符串转换成 Byte 数组即可,跟具体的任何序列化方式,比如跟采用 Hessian 还是 Pb 都是无关的。
serializeHeader 则是序列化 HeaderMap。这时候因为有了前面的 requestClass,就可以根据这个名字拿到SOFARPC 层或者用户自己注册的序列化器。然后进行序列化 Header,这个对应 SOFARPC 框架中的 SofaRpcSerialization 类。在这个类里,我们可以自由使用本次传输的对象,将一些必要信息提取到Header 中,并进行对应的编码。这里也不跟具体的序列化方式有关,是一个简单 Map 的序列化,写 key、写 value、写分隔符。有兴趣的同学可以直接看源码。
源码链接:
github.com/alipay/sofa…
serializeContent 序列化业务对象的信息,这里 RPC 框架会根据本次用户配置的信息决定如何操作序列化对象,是调用 Hessian 还是调用 Pb 来序列化。
至此,完成了序列化过程。可以看到,这些操作实际上都是在业务发起的线程里面的,在请求发送阶段,也就是在调用 Netty 的写接口之前,跟 IO 线程池还没什么关系,所以都会在业务线程里先做好序列化。
对于反序列化
介绍完序列化,反序列化的时机就有一些差异,需要重点考虑。在服务端的请求接收阶段,我们有 IO 线程、业务线程两种线程池。为了最大程度的配合业务特性、保证整体吞吐,SOFABolt 设计了精细的开关来控制反序列化时机。
具体选择逻辑如下:
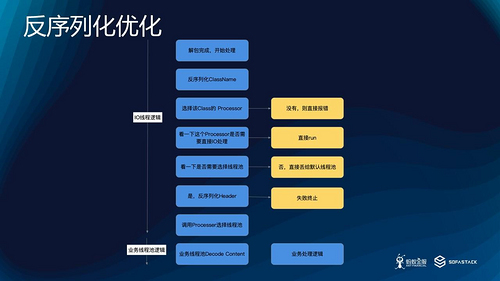
用户请求处理器图
体现在代码的这个类中。
com.alipay.remoting.rpc.protocol.RpcRequestProcessor#process复制代码
从上图可以看到 反序列化 大致分成以下三种情况,适用于不同的场景。
| IO 线程池动作 |
业务线程池 |
使用场景 |
| 反序列化 ClassName |
反序列化 Header 和 Content 处理业务 |
一般 RPC 默认场景。IO 线程池识别出来当前是哪个类,调用用户注册的对应处理器 |
| 反序列化 ClassName 和 Header |
仅反序列化 Content 和业务处理 |
希望根据 Header 中的信息,选择线程池,而不是直接注册的线程池 |
| 一次性反序列化 ClassName、Header 和 Content,并直接处理 |
没有逻辑 |
IO 密集型的业务 |
线程池隔离
经过前面的介绍,可以了解到,由于业务逻辑通常情况下在 SOFARPC 设置的一个默认线程池里面处理,这个线程池是公用的。也就是说, 对于一个应用,当他作为服务端时,所有的调用请求都会在这个线程池中处理。
举个例子:如果应用 A 对外提供两个接口,S1 和 S2,由于 S2 接口的性能不足,可能是下游系统的拖累,会导致这个默认线程池一直被占用,无法空闲出来被其他请求使用。这会导致 S1 的处理能力受到影响,对外报错,线程池已满,导致整个业务链路不稳定,有时候 S1 的重要性可能比 S2 更高。
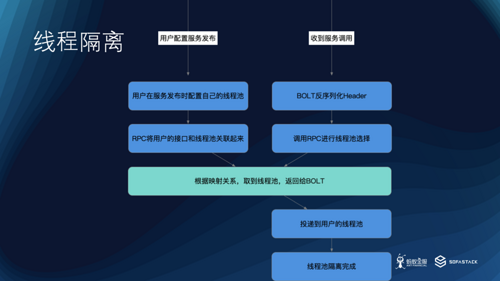
线程池隔离图
因此,基于上面的设计,SOFARPC 框架允许在序列化的时候,根据用户对当前接口的线程池配置将接口和服务信息放到 Header 中,反序列化的时候,根据这个 Header 信息选择到用户自定义的线程池。这样,用户可以针对不同的服务接口配置不同的业务线程池,可以避免部分接口对整个性能的影响。在系统接口较多的时候,可以有效的提高整体的性能。
内存操作优化
介绍完线程池隔离之后,我们介绍一下 Netty 内存操作的一些注意事项。在 Netty 内存操作中,如何尽量少的使用内存和避免垃圾回收,来优化性能。先看一些基础概念。
内存基础
在 JVM 中内存可分为两大块,一个是堆内存,一个是直接内存。
堆内存是 JVM 所管理的内存。所有的对象实例都要在堆上分配,垃圾收集器可以在堆上回收垃圾,有不同的运行条件和回收区域。
JVM 使用 Native 函数在堆外分配内存。为什么要在堆外分配内存?主要因为在堆上的话, IO 操作会涉及到频繁的内存分配和销毁,这会导致 GC 频繁,对性能会有比较大的影响。
注意:直接分配本身也并不见得性能有多好,所以还要有池的概念,减少频繁的分配。
因此 JVM 中的直接内存,存在堆内存中的其实就是 DirectByteBuffer 类,它本身其实很小,真的内存是在堆外,通过 JVM 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。直接内存不会受到 Java 堆的限制,只受本机内存影响。当然可以设置最大大小。也并不是 Direct 就完全跟 Heap 没什么关系了,因为堆中的这个对象持有了堆外的地址,只有这个对象被回收了,直接内存才能释放。
其中 DirectByteBuffer 经过几次 young gc 之后,会进入老年代。当老年代满了之后,会触发 Full GC。
因为本身很小,很难占满老年代,因此基本不会触发 Full GC,带来的后果是大量堆外内存一直占着不放,无法进行内存回收,所以这里要注意 -XX:+DisableExplicitGC 不要关闭。
Pool 还是 UnPool
Netty 从 4.1.x 开始,非 Android 平台默认使用池化(PooledByteBufAllocator)实现,能最大程度的减少内存碎片。另外一种方式是非池化(UnpooledByteBufAllocator),每次返回一个新实例。可以查看 io.netty.buffer.ByteBufUtil 这个工具类。
在 4.1.x 之前,由于 Netty 无法确认 Pool 是否存在内存泄漏,所以并没有打开。目前,SOFARPC 的 SOFABolt 中目前对于 Pool 和 Upool 是通过参数决定的,默认是 Unpool。使用 Pool 会有更好的性能数据。在 SOFABolt 1.5.0 中进行了打开,如果新开发 RPC 框架,可以进行默认打开。SOFARPC 下个版本会进行打开。
可能大家对这个的感受不是很直观,因此我们提供了一个测试 Demo。
注意:
- 如果 DirectMemory 设置过小,是不会启用 Pooled 的。
- 另外需要注意 PooledByteBufAllocator 的 MaxDirectMemorySize 设置。本机验证的话,大概需要 96M 以上,在 Demo中有说明。
- Demo地址: github.com/leizhiyuan/…
DEFAULT_NUM_DIRECT_ARENA = Math.max(0,
SystemPropertyUtil.getInt(
"io.netty.allocator.numDirectArenas",
(int) Math.min(
defaultMinNumArena,
PlatformDependent.maxDirectMemory() / defaultChunkSize / 2 / 3)));复制代码
Direct 还是 Heap
目前 Netty 在 write 的时候默认是 Direct ,而在 read 到字节流时会进行选择。可以查看如下代码, io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe#read` 。框架所采取的策略是:如果所运行的平台提供了Unsafe 相关的操作,则调用 Unsafe 在 Direct 区域进行内存分配,否则在 Heap 上进行分配。
有兴趣的同学可以通过 Demo 3 中的示例来 debug,断点打在如下位置,就可以看到 Netty 选择的过程。
io.netty.buffer.AbstractByteBufAllocator#ioBuffer(int)复制代码
正常 RPC 的开发中,基本上都会在 Direct 区域进行内存分配,在 Heap 中进行内存分配本身也不符合 RPC 的性能要求。因为 GC 有比较大的性能影响,而 GC 在运行中,业务的代码影响比较大,可控性不强。
其他注意事项
一般来说,我们不会主动去分配 ByteBuf ,只要去操作读写 ByteBuf。所以:
- 使用 Bytebuf.forEachByte() ,传入 Processor 来代替循环 ByteBuf.readByte() 的遍历操作,避免rangeCheck() 。因为每次 readByte() 都不是读一个字节这么简单,首先要判断 refCnt() 是否大于0,然后再做范围检查防止越界。getByte(i=int) 又有一些检查函数,JVM 没有内连的时候,性能就有一定的损耗。
- 使用 CompositeByteBuf 来避免不必要的内存拷贝。在操作一些协议包数据拼接时会比较有用,比如在 Service Mesh 的场景,如果我们需要改变 Header 中的 RequestId,然后和原始的 Body 数据拼接。
- 如果要读1个 int , 用 Bytebuf.readInt() , 不要使用 Bytebuf.readBytes(buf, 0, 4) 。这样能避免一次内存拷贝,其他 long 等同理,毕竟还要转换回来,性能也更好。在 Demo 4 中有体现。
- RecyclableArrayList ,在出现频繁 new ArrayList 的场景可考虑 。例如:SOFABolt 在批量解包的时候使用了 RecyClableList ,可以让 Netty 来回收。上期分享中有介绍到这个功能,详情可以见文末上期回顾链接。
- 避免拷贝,为了失败时重试,假设要保留内容稍后使用。不想 Netty 在发送完毕后把 buffer 就直接释放了,可以用 copy() 复制一个新的 ByteBuf。但是下面这样更高效,Bytebuf newBuf=oldBuf.duplicate().retain(); 只是复制出独立的读写索引, 底下的 ByteBuffer 是共享的,同时将 ByteBuffer 的计数器+1,这样可以避免释放,而不是通过拷贝来阻止释放。
- 最后可能出现问题,使用 PooledBytebuf 时要善于利用 -Dio.netty.leakDetection.level 参数,可以定位内存泄漏出现的信息。
客户端权重调节
下面,我们说一下权重。在路由阶段的权重调节,我们通常能够拿到很多可以调用的服务端。这时候通常情况下,最好的负载均衡算法应该是随机算法。当然如果有一些特殊的需求,比如希望同样的参数落到固定的机器组,一致性 Hash 也是可以选择的。
不过,在系统规模到达很高的情况下,需要对启动期间和单机故障发生期间的调用有一定调整。
启动期权重调节
如果应用刚刚启动完成,此时 JIT 的优化以及其他相关组件还未充分预热完成。此时,如果立刻收到正常的流量调用可能会导致当前机器处理非常缓慢,甚至直接当机无法正常启动。这时需要的操作:先关闭流量,然后重启,之后开放流量。
为此,SOFARPC 允许用户在发布服务时,设置当前服务在启动后的一段时间内接受的权重数值,默认是100。
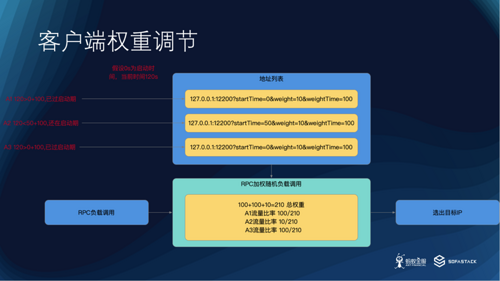
权重负载均衡图
如上图所示,假设用户设置了某个服务 A 的启动预热时间为 60s,期间权重是10,则 SOFARPC 在调用的时候会进行如图所示的权重调节。
这里我们假设有三个服务端,两个过了启动期间,另一个还在启动期间。在负载均衡的时候,三个服务器会根据各自的权重占总权重的比例来进行负载均衡。这样,在启动期间的服务方就会收到比较少的调用,防止打垮服务端。当过了启动期间之后,会使用默认的 100 权重进行负载均衡。这个在 Demo 5 中有示例。
运行时单机故障权重调节
除了启动期间保护服务端之外,还有个情况,是服务端在运行期间假死,或者其他故障。现象会是:服务发现中心认为机器存活,仍然会给客户端推送这个地址,但是调用一直超时,或者一直有其他非业务异常。这种情况下,如果还是调用,一方面会影响链路的性能,因为线程占用等;另一方面会有持续的报错。因此,这种情况下还需要通过单机故障剔除的功能,对异常机器的权重进行调整,最终可以在负载均衡的时候生效。
对于单机故障剔除,本次我们不做为重点讲解,有兴趣的同学可以看下相关文章介绍。
附: 【剖析 | SOFARPC 框架】系列之 SOFARPC 单机故障剔除剖析
Server Fail Fast 支持
服务端根据客户端的超时时间来决定是否丢弃已经超时的结果,并且不返回,以减少网络数据以及减少不必要的处理,带来性能提升。
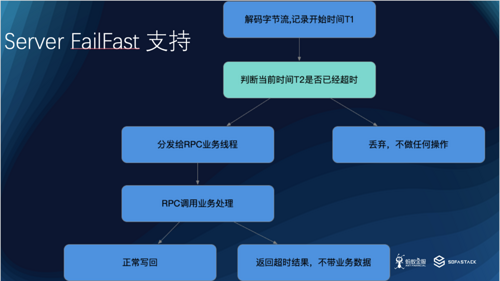
这里面分两种。
第一种是 SOFABolt 在网络层的 Server Fail Fast
对于 SOFABolt 层面, SOFABolt 会在 Decode 完字节流之后,记录一个开始时间,然后在准备分发给 RPC 的业务线程池之前,比较一下当前时间,是否已经超过了用户的超时时间。如果超过了,直接丢弃,不分发给 RPC,也不会给客户端响应。
第二种是 SOFARPC 在业务层的 Server Fail Fast
如果 SOFABolt 分发给 SOFARPC 的时候,还没有超时,但是 SOFARPC 走完了服务端业务逻辑之后,发现已经超时了。这时候,可以不返回业务结果,直接构造异常超时结果,数据更少,但结果是一样的。
注意:这里会有个副作用,虽然服务端处理已经完成,但是日志里可能会打印一个错误码,需要根据实际情况开启。
之后我们也会开放参数,允许用户设置。
用户可调节参数
对用户的配置,大家都可以通过 com.alipay.sofa.rpc.boot.config.SofaBootRpcProperties 这个类来查看。
使用方式和标准的 SpringBoot 工程一致,开箱即可。
如果是特别特殊的需求,或者并不使用 Spring 作为开发框架,我们也允许用户通过定制 rpc-config.json 文件来进行调整,包括动态代理生成方式、默认的 tracer、超时时间的控制、时机序列化黑名单是否开启等等。这些参数在有特殊需求的情况下可以优化性能。
线程池调节
以业务线程数为例,目前默认线程池,20核心线程数,200最大线程数,0队列。可以通过以下配置项来调整:
com.alipay.sofa.rpc.bolt.thread.pool.core.size # bolt 核心线程数 com.alipay.sofa.rpc.bolt.thread.pool.max.size # bolt 最大线程数 com.alipay.sofa.rpc.bolt.thread.pool.queue.size # bolt 线程池队列复制代码
这里在线程池的设置上,主要关注队列大小这个设置项。如果队列数比较大,会导致如果上游系统处理能力不足的时候,请求积压在队列中,等真正处理的时候已经过了比较长的时间,而且如果请求量非常大,会导致之后的请求都至少等待整个队列前面的数据。
所以如果业务是一个延迟敏感的系统, 建议不要设置队列大小;如果业务可以接受一定程度的线程池等待,可以设置。这样,可以避过短暂的流量高峰。
总结
SOFARPC 和 SOFABolt 在性能优化上做了一些工作,包括一些比较实际的业务需求产生的性能优化方式。两篇文章不足以介绍更多的代码实现细节和方式。错过上期直播的可以点击文末链接进行回顾。
相信大家在 RPC 或者其他中间件的开发中,也有自己独到的性能优化方式,如果大家对 RPC 的性能和需求有自己的想法,欢迎大家在钉钉群(搜索群号即可加入:23127468)或者 Github 上与我们讨论交流。
到此,我们 SOFAChannel 的 SOFARPC 系列主题关于性能优化相关的两期分享就介绍完了,感谢大家。
关于 SOFAChannel 有想要交流的话题可以在文末留言或者在公众号留言告知我们。
本期视频回顾
tech.antfin.com/activities/…
往期直播精彩回顾
- SOFAChannel#2 SOFARPC 性能优化实践(上): tech.antfin.com/activities/…
- SOFA Channel#1 从蚂蚁金服微服务实践谈起: tech.antfin.com/activities/…
相关参考链接
- Demo 链接: github.com/leizhiyuan/…
- 【剖析 | SOFARPC 框架】系列之 SOFARPC 单机故障剔除剖析: mp.weixin.qq.com/s/WusXmhMns…
- bolt enable Pooled: github.com/alipay/sofa…
- Netty pooled release note: netty.io/wiki/new-an…
讲师观点

公众号:金融级分布式架构(Antfin_SOFA)
正文到此结束
- 本文标签: 源码 数据 时间 参数 线程池 NIO 一致性 微服务 测试 负载均衡 UI 需求 list 文章 ORM springboot Full GC 定制 js 金融 代码 value ACE 业务层 分布式 JVM 协议 https 配置 GitHub key http Service id ArrayList 服务器 git map 可控性 json core Property 服务端 索引 java ip cat Netty 实例 src 钉钉 希望 性能优化 spring db 线程 管理 遍历 总结 处理器 垃圾回收 tab tar NSA Android 开发 queue IO bug
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

