使用Neo4j和Java进行大数据分析 第1部分
几十年来,关系数据库一直主导着数据管理,但它们最近已经失去了NoSQL的替代品。虽然NoSQL数据存储不适合每个用例,但它们通常更适合 大数据 ,这是处理大量数据的系统的简写。四种类型的数据存储用于大数据:
- 键/值存储,例如Memcached和Redis
- 面向文档的数据库,如MongoDB,CouchDB和DynamoDB
- 面向列的数据存储,如Cassandra和HBase
- 图形数据库,如Neo4j和OrientDB
本文介绍Neo4j,它是用于与 高度相关的数据 进行交互的图形数据库。虽然关系数据库擅长管理数据 之间的 关系,但图形数据库更擅长管理 n维关系的数据 。例如,在社交网络中,您要分析涉及朋友,朋友的朋友等模式。一个图形数据库可以很容易地回答一个问题,“给定五个分离度,我的社交网络中未看过的流行的五部电影是什么?” 这些问题在推荐软件中很常见,图形数据库非常适合解决它们。此外,图形数据库擅长表示分层数据,例如访问控制,产品目录,电影数据库,甚至网络拓扑和组织结构图。当您拥有具有多个关系的对象时,您会很快发现图形数据库提供了一种优雅的,面向对象的范例来管理这些对象。
图数据库的情况
顾名思义,图形数据库擅长表示数据图形。这对社交软件特别有用,每次与某人联系时,你们之间就会建立关系。可能在你上次求职时,你选择了一些你感兴趣的公司,然后搜索你的社交网络以获取与他们的联系。虽然你可能不知道有那些人为这些公司工作,但你的社交网络中的某些人可能会这样做。很容易在一个或两个分离度(你的朋友或朋友的朋友)内解决这样的问题,但当你开始在网络中扩展搜索时会发生什么?
在他们的书中, Neo4j In Action ,Aleksa Vukotic和Nicki Watt探讨了关系数据库和图形数据库之间的差异,以解决社交网络问题。为了向你展示为什么图形数据库正成为关系数据库日益流行的替代方案,我将在接下来的几个示例中使用它们的工作。
建模复杂的关系:Neo4j与MySQL
从计算机科学的角度来看,当我们考虑在社交网络中建模用户之间的关系时,我们可能会绘制如图1所示的图形。
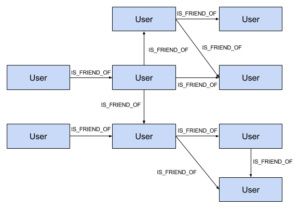
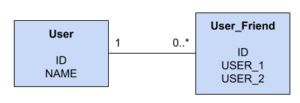
用户与其他用户有 IS_FRIEND_OF 关系,这些用户与其他用户也有 IS_FRIEND_OF 关系,等等。图2显示了我们如何在关系数据库中表示这一点。
USER 表与 USER_FRIEND 表具有一对多的关系, USER_FRIEND 表模拟两个用户之间的“朋友”关系。现在我们已经建立了关系模型,我们将如何查询数据?Vukotic和Watt测量了查询性能,用于计算出五个级别深度的不同朋友的数量(朋友的朋友的朋友的朋友)。在关系数据库中,查询看起来如下:
# Depth 1 select count(distinct uf.*) from user_friend uf where uf.user_1 = ? # Depth 2 select count(distinct uf2.*) from user_friend uf1 inner join user_friend uf2 on uf1.user_1 = uf2.user_2 where uf1.user_1 = ? # Depth 3 select count(distinct uf3.*) from t_user_friend uf1 inner join t_user_friend uf2 on uf1.user_1 = uf2.user_2 inner join t_user_friend uf3 on uf2.user_1 = uf3.user_2 where uf1.user_1 = ? # And so on...
这些查询的有趣之处在于,每次我们再出一个级别时,我们都需要自己加入 USER_FRIEND 表格。表1显示了研究人员Vukotic和Watt在插入1,000个用户时发现了什么,每个用户大约有50个关系(50,000个关系)并运行查询。
表1.各种关系深度的MySQL查询响应时间
深度执行时间(秒)计数结果
2 0.028〜900
3 0.213〜999
4 10.273〜999
5 92.613〜999
MySQL可以很好地将数据连接到三个级别,但之后性能会迅速下降。原因是每次 USER_FRIEND 表与自身连接时,MySQL必须计算表的笛卡尔积,即使大部分数据将被丢弃。例如,当执行该连接五次时,笛卡尔积产生50,000 ^ 5行,或102.4 * 10 ^ 21行。当我们只对其中的1000个感兴趣时,这是一种浪费!
接下来,Vukotic和Watt尝试对Neo4j执行相同类型的查询。这些完全不同的结果如表2所示。
表2.各种关系深度的Neo4j响应时间
深度执行时间(秒)计数结果
2 0.04〜900
3 0.06〜999
4 0.07〜999
5 0.07〜999
从这些执行比较中得出的结论 并不是 Neo4j比MySQL更好。相反,当遍历这些类型的关系时,Neo4j的性能取决于检索的记录数,而MySQL的性能取决于 USER_FRIEND 表中的记录数。因此,随着关系数量的增加,MySQL查询的响应时间也会增加,而Neo4j查询的响应时间将保持不变。这是因为Neo4j的响应时间取决于特定查询的关系数,而不取决于关系总数。
扩展Neo4j以获取大数据
将这个思想项目进一步扩展,Vukotic和Watt接下来创建了一百万用户,他们之间有5000万个关系。表3显示了该数据集的结果。
表3.对于5000万关系的Neo4j响应时间
深度执行时间(秒)计数结果
2 0.01〜2500
3 0.168〜11万
4 1.359〜60万
5 2.132〜80万
毋庸置疑,我非常感谢Aleksa Vukotic和Nicki Watt,并强烈建议您查看他们的作品。我从本书的第一章 Neo4j in Action中 提取了本节中的所有测试。
Neo4j入门
您已经看到Neo4j能够非常快速地执行大量高度相关的数据,毫无疑问,它比MySQL(或任何关系数据库)更适合某些类型的问题。如果您想了解有关Neo4j如何工作的更多信息,最简单的方法是通过Web控制台与其进行交互。
首先 下载Neo4j 。对于本文,您将需要Community Edition,在撰写本文时版本为3.2.3。
- 在Mac上,下载DMG文件并像安装任何其他应用程序一样进行安装。
- 在Windows上,要么下载EXE并浏览安装向导,要么下载ZIP文件并在硬盘驱动器上解压缩。
- 在Linux上,下载TAR文件并在硬盘驱动器上解压缩。
- 或者,在任何操作系统上使用 Docker镜像 。
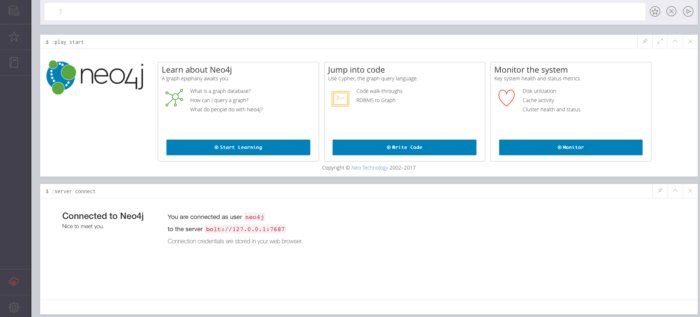
安装Neo4j后,启动它并打开浏览器窗口到以下URL:
http://127.0.0.1:7474/browser/
使用默认用户名 neo4j 和默认密码登录 neo4j 。您应该看到类似于图3的屏幕。
Neo4j中的节点和关系
Neo4j是围绕节点和关系的概念设计的:
- 一个 节点 代表一个东西,比如一个用户,电影,或者一本书。
- 节点包含一组 键/值对 ,例如名称,标题或发布者。
- 节点的 标签 定义了它的类型 - 用户,电影或书籍。
- 关系 定义节点之间的关联,并且是特定类型。
举个例子,我们可以定义像钢铁侠和美国队长这样的角色节点; 定义一个名为“复仇者”的电影节点; 然后定义 APPEARS_IN 为钢铁侠和复仇者之间以及美国队长和复仇者之间的关系。所有这些都显示在图4中。
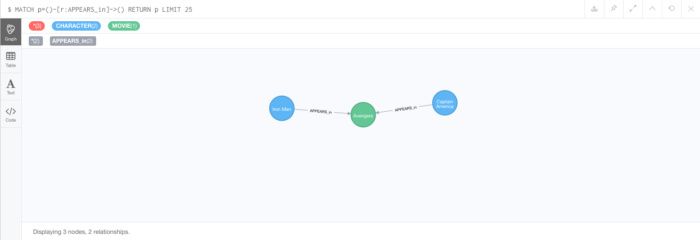
图4显示了三个节点(两个Character节点和一个Movie节点)和两个关系(两种类型 APPEARS_IN )。
建模和查询节点和关系
与关系数据库如何使用结构化查询语言(SQL)与数据交互类似,Neo4j使用 Cypher查询语言 与节点和关系进行交互。
让我们使用Cypher创建一个简单的家庭表示。在Web界面的顶部,查找美元符号。这表示允许您直接对Neo4j执行Cypher查询的字段。在该字段中输入以下Cypher查询(我以我的家人为例,但如果您愿意,可以随意更改细节以建模您自己的家庭):
CREATE (person:Person {name: "Steven", age: 45}) RETURN person
结果如图5所示。
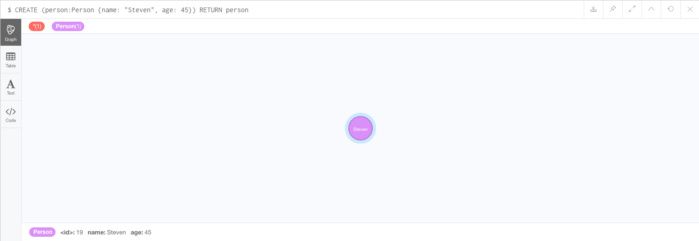
在图5中,您可以看到一个标记为Person且名称为Steven的新节点。如果将鼠标悬停在Web控制台中的节点上,您将在底部看到其属性。在这种情况下,属性是ID:19,名称:Steven,年龄:45。现在让我们分解Cypher查询:
- CREATE :该
CREATE关键字用于创建节点和关系。在这种情况下,我们传递一个参数,它Person括在括号中,因此它意味着创建一个单独的节点。 - (person:Person {...}) :小写“
person”是一个变量名称,通过它我们可以访问正在创建的人,而大写“Person”是标签。请注意,冒号将变量名称与标签分开。 - {name:“Steven,年龄:45} :这些是我们为我们正在创建的节点定义的键/值属性.Neo4j不要求您在创建节点之前定义架构,并且每个节点都可以具有唯一性元素集。(大多数情况下,您使用相同的标签定义具有相同属性的节点,但这不是必需的。)
- 返回人 :创建节点后,我们要求Neo4j将其返回给我们。这就是我们看到节点出现在用户界面中的原因。
该 CREATE 命令(不区分大小写)用于创建节点,可以按如下方式读取: 使用包含名称和年龄属性的Person标签创建一个新节点; 将其分配给person变量并将其返回给调用者 。
查询Cypher查询语言
接下来我们想尝试一下Cypher的查询。首先,我们需要创建更多人,以便我们可以定义它们之间的关系。
CREATE (person:Person {name: "Michael", age: 16}) RETURN person
CREATE (person:Person {name: "Rebecca", age: 7}) RETURN person
CREATE (person:Person {name: "Linda"}) RETURN person
创建四个人后,您可以单击 节点标签 下的“ 人员” 按钮(如果单击网页左上角的数据库图标,则可见)或执行以下Cypher查询:
MATCH (person: Person) RETURN person
Cypher使用 MATCH 关键字在Neo4j中查找内容。在此示例中,我们要求Cypher匹配所有标记为Person的节点,将这些节点分配给 person 变量,并返回与该变量关联的值。因此,你应该看到您创建的四个节点。如果将鼠标悬停在Web控制台中的每个节点上,你将看到每个人的属性。(你可能会注意到我将我妻子的年龄排除在她的节点之外,说明属性不需要在节点之间保持一致,即使是相同的标签。我也不会愚蠢地公布我妻子的年龄。)
我们可以通过 MATCH 向我们想要返回的节点添加条件来进一步扩展此示例。例如,如果我们只想要“Steven”节点,我们可以通过匹配name属性来检索它:
MATCH (person: Person {name: "Steven"}) RETURN person
或者,如果我们想要归还所有孩子,我们可以要求所有18岁以下的人:
MATCH (person: Person) WHERE person.age < 18 RETURN person
在此示例中,我们 WHERE 在查询中添加了子句以缩小结果范围。 WHERE 与其SQL等价物非常相似: MATCH (person: Person) 查找具有Person标签的所有节点,然后该 WHERE 子句过滤结果集中的值。
关系中的建模方向
我们有四个节点,所以让我们创建一些关系。首先,让我们创建史蒂文和琳达之间的 IS_MARRIED_TO 关系:
MATCH (steven:Person {name: "Steven"}), (linda:Person {name: "Linda"}) CREATE (steven)-[:IS_MARRIED_TO]->(linda) return steven, linda
在这个例子中,我们匹配标记为Steven和Linda的两个Person节点,并且我们创建了一个从Steven到Linda 的 IS_MARRIED_TO 类型关系。创建关系的格式如下:
(node1)-[relationshipVariable:RELATIONSHIP_TYPE->(node2)
这 relationshipVariable 是可选的,但如果您希望能够在RETURN语句(或WHERE子句)中访问它,则需要它。箭头 ()-[]->() 表示Cypher要求的关系方向。如果你想表达Linda与Steven结婚,那么你可以按照以下方式在另一个方向写下这段关系: ()<-[]-() 。如果你想创建一个双向关系,表明Linda和Steve彼此结婚,那么你需要创建两个独立的关系。虽然Cypher要求您定义关系的方向,但您可以使用方向查询,也可以不使用方向查询。
以下查询查找此系列中已结婚的所有人(请注意查询中缺少任何方向):
MATCH (p1:Person)-[:IS_MARRIED_TO]-(p2:Person) RETURN p1, p2
结果如图6所示。

现在让我们创建一些关系:
MATCH (michael:Person {name: "Michael"}), (rebecca:Person {name: "Rebecca"}) CREATE (michael)-[:IS_SIBLILNG]->(rebecca) return michael, rebecca
MATCH (steven:Person {name: "Steven"}), (michael:Person {name: "Michael"}) CREATE (steven)-[:HAS_CHILD]->(michael) return steven, michael
MATCH (steven:Person {name: "Steven"}), (rebecca:Person {name: "Rebecca"}) CREATE (steven)-[:HAS_CHILD]->(rebecca) return steven, rebecca
MATCH (linda:Person {name: "Linda"}), (michael:Person {name: "Michael"}) CREATE (linda)-[:HAS_CHILD]->(michael) return linda, michael
MATCH (linda:Person {name: "Linda"}), (rebecca:Person {name: "Rebecca"}) CREATE (linda)-[:HAS_CHILD]->(rebecca) return linda, rebecca
我们现在可以通过以下查询查看所有人及其关系:
MATCH (p:Person) RETURN p
结果如图7所示。

遍历社交图
要真正探索图数据库的力量,我们需要扩展我们的社交图。首先,让我们添加一些 FRIEND 关系:
MATCH (michael:Person {name: "Michael"}) CREATE (michael)-[:FRIEND]->(charlie:Person {name: "Charlie", age: 16}) RETURN michael, charlie
MATCH (michael:Person {name: "Michael"}) CREATE (michael)-[:FRIEND]->(koby:Person {name: "Koby"}) RETURN michael, koby
MATCH (michael:Person {name: "Michael"}) CREATE (michael)-[:FRIEND]->(grant:Person {name: "Grant"}) RETURN michael, grant
MATCH (rebecca:Person {name: "Rebecca"}) CREATE (rebecca)-[:FRIEND]->(jordyn:Person {name: "Jordyn"}) RETURN rebecca, jordyn
MATCH (rebecca:Person {name: "Rebecca"}) CREATE (rebecca)-[:FRIEND]->(katie:Person {name: "Katie"}) RETURN rebecca, katie
关于这些关系的一些有趣的事情是朋友节点与 FRIEND 关系同时创建。例如,执行第一个语句时,“Charlie”Person节点不存在,但该语句创建了从现有“Michael”Person节点到名为“Charlie”的新Person节点的 FRIEND 关系。您可以拉出所有Person节点并验证节点是否已创建,如图8所示。
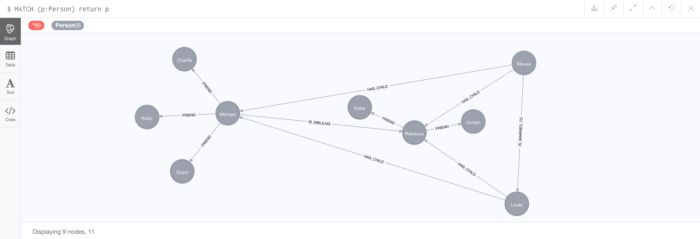
我们已经启动了一个非常好的社交图,所以让我们尝试编写一个更复杂的查询来查找我孩子的所有朋友:
MATCH (steven:Person {name:"Steven"})-[:HAS_CHILD]-(:Person)-[:FRIEND]-(friend:Person) RETURN friend
结果如图9所示。
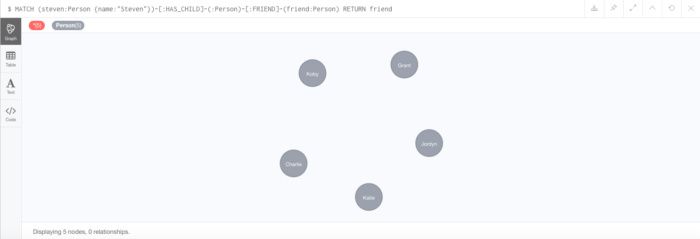
在此查询中,我们从名为“Steven”的 HAS_CHILD Person节点开始,遍历所有与Person节点的 FRIEND 关系,遍历所有Person节点的关系,并返回朋友列表。我们可以包含方向关系,但省略箭头可以让我们遍历两个方向。
社交图中的键/值对
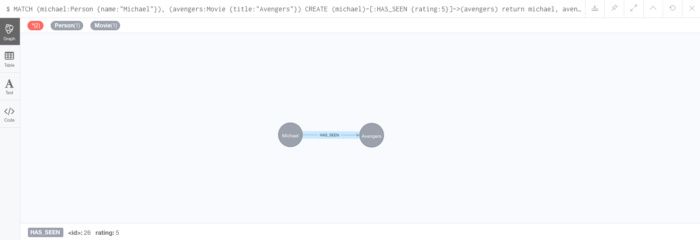
除了定义两个节点之间的关系之外,关系本身可以具有键/值对。例如,我们可能决定创建Movie节点,然后 HAS_SEEN 在他们看到的人和电影之间创建关系。在这些 HAS_SEEN 关系中,我们还可以添加“评级”属性。下面的代码创建一个标题为Avengers的电影,然后 HAS_SEEN 在Michael和电影复仇者之间创建一个关系,评级为5。
CREATE (movie:Movie {title:"Avengers"}) RETURN movie
MATCH (michael:Person {name:"Michael"}), (avengers:Movie {title:"Avengers"}) CREATE (michael)-[:HAS_SEEN {rating:5}]->(avengers) return michael, avengers
图10显示了结果。
Java中的图形分析对于我们在进入Java代码之前的最后一个例子,让我们尝试使用图形分析进行简单的实验。我们会给孩子们的朋友添加一些电影,设置我孩子的性别,然后查询我的一个孩子(迈克尔)可能想要看的电影。结果如图11所示。
CREATE (movie:Movie {title:"Batman"}) RETURN movie
CREATE (movie:Movie {title:"Gone with the Wind"}) RETURN movie
CREATE (movie:Movie {title:"Spongebob Square Pants"}) RETURN movie
CREATE (movie:Movie {title:"Avengers 2"}) RETURN movie
MATCH (charlie:Person {name:"Charlie"}), (movie:Movie {title:"Batman"}) CREATE (charlie)-[:HAS_SEEN {rating:4}]->(movie) return charlie, movie
MATCH (charlie:Person {name:"Charlie"}), (movie:Movie {title:"Gone with the Wind"}) CREATE (charlie)-[:HAS_SEEN {rating:0}]->(movie) return charlie, movie
MATCH (koby:Person {name:"Koby"}), (movie:Movie {title:"Batman"}) CREATE (koby)-[:HAS_SEEN {rating:4}]->(movie) return koby, movie
MATCH (koby:Person {name:"Koby"}), (movie:Movie {title:"Avengers 2"}) CREATE (koby)-[:HAS_SEEN {rating:5}]->(movie) return koby, movie
MATCH (grant:Person {name:"Grant"}), (movie:Movie {title:"Spongebob Square Pants"}) CREATE (grant)-[:HAS_SEEN {rating:1}]->(movie) return grant, movie
MATCH (jordyn:Person {name:"Jordyn"}), (movie:Movie {title:"Spongebob Square Pants"}) CREATE (jordyn)-[:HAS_SEEN {rating:5}]->(movie) return jordyn, movie
MATCH (michael:Person {name: "Michael"}) SET michael.gender = "male" RETURN michael
MATCH (rebecca:Person {name: "Rebecca"}) SET rebecca.gender = "female" RETURN rebecca
MATCH (steven:Person {name:"Steven"})-[:HAS_CHILD]-(child:Person)-[:FRIEND]-(friend:Person)-[hasSeen:HAS_SEEN]-(movie:Movie) WHERE child.gender = "male" AND hasSeen.rating > 3 RETURN DISTINCT movie.title
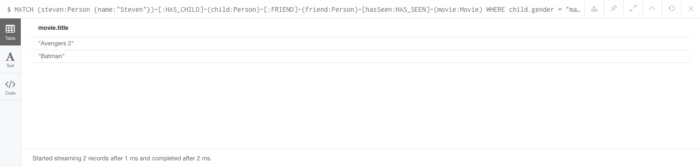
图11.查询我孩子的朋友看过并且评分大于3的所有电影的结果
上面的前四个陈述创造了四部电影。接下来的六个陈述创造了我的孩子的朋友和他们看过的电影之间的 HAS_SEEN 关系,具有不同的评级。接下来的两个语句为我的孩子添加了一个性别,这是通过按名称查找Person节点然后调用来完成的 SET childName.gender = "male|female" 。在Cypher中,该 SET 语句允许您通过将值设置为更改现有属性,添加新属性或删除属性 NULL 。最后的查询需要一些工作才能理解。我们从名为“Steven”的Person开始,跟随他与子节点Person关系的 HAS_CHILD 关系,跟随那些Person节点到 FRIEND Person节点,通过 HAS_SEEN 关系跟随那些朋友Person节点到Movie节点,然后添加一个 WHERE 检查两者性别的子句史蒂文的孩子和评级属性的 HAS_SEEN 价值。最后,因为有些孩子看过同一部电影(蝙蝠侠),我们只想要回归 DISTINCT 电影片头。在这种情况下,我们不返回电影节点,而是返回电影的标题属性,这就是输出显示在表格中的原因。对于聪明的观察者,我们可以通过将性别添加到子节点查询来简化这一点,如下所示:
MATCH (steven:Person {name:"Steven"})-[:HAS_CHILD]-(child:Person {gender:"male"})-[:FRIEND]-(friend:Person)-[hasSeen:HAS_SEEN]<-(movie:Movie) WHERE hasSeen.rating > 3 RETURN DISTINCT movie.title
第1部分的结论
Cypher是一种考虑编写查询的不同方式,我鼓励您阅读 正式文档 以了解更多信息。一旦掌握了编写Cypher查询的过程,Java编程将是最简单的部分!我们将在本简介的后半部分中对图形数据和与Neo4j的关系进行选择。
英文原文: https://www.javaworld.com/article/3256278/big-data-analytics-with-neo4j-and-java-part-1.html
正文到此结束
- 本文标签: zip 家庭 sql 代码 Docker src 十年 java https HBase 管理 Select dist IO 目录 ip 标题 大数据 遍历 操作系统 cache mysql db 产品 redis MongoDB 缩小 Action 回答 linux node 美国 数据 Cassandra 一对多 社交网络 mongo windows 数据库 UI HTML 参数 下载 模型 测试 tar 安装 App 软件 删除 id web NOSQL 时间 组织 http 希望
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

