Netty内存池之PoolChunk原理详解 原 荐
PoolChunk 是Netty内存池中的重要组成部分,其作用主要在于维护了一个较大的内存块,当需要申请超过8KB的内存时,就会从 PoolChunk 中获取。本文首先会对 PoolChunk 的整体结构进行讲解,然后会讲解其各个主要属性的作用,最后会从源码的角度对 PoolChunk 是如何实现对大块内存的申请和释放的。
1. PoolChunk整体结构
PoolChunk 默认申请的内存大小是16M,在结构上,其会将这16M内存组织成为一颗平衡二叉树,二叉树的每一层每个节点所代表的内存大小都是均等的,并且每一层节点所代表的内存大小总和加起来都是16M,整颗二叉树的总层数为12,层号从0开始。其结构示意图如下:
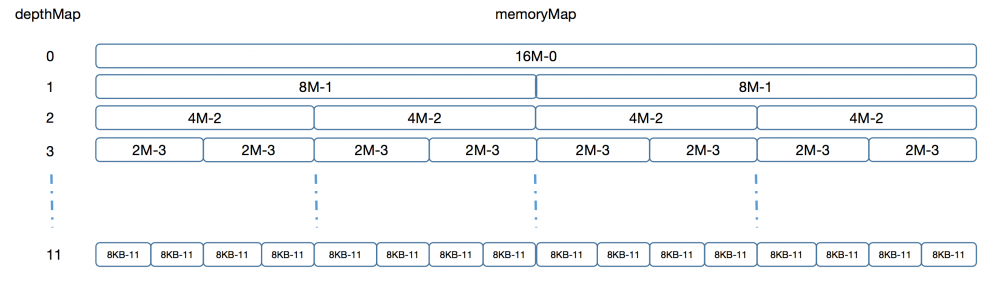
关于上图,我们主要有如下几点需要说明:
- 一个PoolChunk占用的总内存是16M,其会按照当前二叉树所在的层级将16M内存进行划分,比如第1层将其划分为两个8M,第二层将其划分为4个4M等等,整颗二叉树最多有12层,因而每个叶节点的内存大小为8KB,也就是说,PoolChunk能够分配的内存最少为8KB,最多为16M;
- 可以看出,图中的二叉树叶子节点有2^11=2048个,因而整颗树的节点数有4095个。PoolChunk将这4095个节点平铺到了一个长度为4096的数组上,其第1号位存储了0,第2~3号位存储了1,第4~7号位存储了2,依次类推,整体上其实就是将这棵以层号表示的二叉树存入了一个数组中。这里的数组就是左边的depthMap,通过这棵二叉树,可以快速通过下标得到其层数,比如2048号位置的值为11,表示其在二叉树的第11层。depthMap的结构如下图所示:

- 在图中二叉树的每个节点上,我们为当前节点所代表的内存大小标记了一个数字,这个数字其实就表示了当前节点所能够分配的内存大小,比如0代表16M,1代表了8M等等。这些数字就是由memoryMap来存储的,表示二叉树中每个节点代表的可分配内存大小,其数据结构与depthMap完全一样。图中,每一个父节点所代表的可分配内存大小都等于两个子节点的和,如果某个子节点的内存已经被分配了,那么该节点就会被标记为12,表示已分配,而它们的父节点则会被更新为另一个子节点的值,表示父节点可分配的内存就是其两个子节点所能提供的内存之和;
- 对于PoolChunk对内存的申请和释放的整体流程,我们以申请的是9KB的内存进行讲述:
- 首先将9KB=9126拓展为大于其的第一个2的指数,也就是2<<13=16384,由于叶节点8KB=2 << 12,其对应的层数为11,因而16384所在的层数为10,也就是说从内存池中找到一个第10层的未分配的节点即可;
- 得出目标节点在第10层后,这里就会从头结点开始比较,如果头结点所存储的值比10要小,那么就说明其有足够的内存用于分配目标内存,然后就会将其左子节点与10进行比较,如果左子节点比10要大(一般此时左子节点已经被分配出去了,其值为12,因而会比10大),那么就会将右子节点与10进行比较,此时右子节点肯定比10小,那么就会从右子节点的左子节点开始继续上面的比较;
- 当比较到某一个时刻,有一个节点的数字与10相等,就说明这个位置就是我们所需要的内存块,那么就会将其标注为12,然后递归的回溯,将其父节点所代表的内存值更新为其另一个子节点的值;

- 关于内存的分配,这里需要说明的最后一个问题就是,通过上面的计算方式,我们可以找到一个节点作为我们目标要分配的节点,此时就需要将此节点所代表的内存起始地址和长度返回。由于我们只有整个PoolChunk所申请的16M内存的地址值,而通过目标节点所在的层号和其是该层第几个节点就可以计算出该节点相对于整个内存块起始地址的偏移量,从而就可以得到该节点的起始地址值;关于该节点所占用的内存长度,直观的感觉可以理解为一个映射,比如11代表8KB长度,10代表16KB长度等等。当然这里的起始地址和偏移量的计算,PoolChunk并不是通过这种算法直接实现的,而是通过更高效的位运算来实现的。
2. PoolChunk主要属性的作用
在阅读Netty内存池源码的时候,相信大多数读者都会被其各种纷繁复杂的属性所混淆,从而感觉阅读起来艰涩难懂。这里我们单独将其属性列出来,以方便读者在阅读源码时能够更快的理解其各个属性的作用。
// netty内存池总的数据结构,该类我们后续会对其进行讲解 final PoolArena<T> arena; // 当前申请的内存块,比如对于堆内存,T就是一个byte数组,对于直接内存,T就是ByteBuffer, // 但无论是哪种形式,其内存大小都默认是16M final T memory; // 指定当前是否使用内存池的方式进行管理 final boolean unpooled; // 表示当前申请的内存块中有多大一部分是用于站位使用的,整个内存块的大小是16M+offset,默认该值为0 final int offset; // 存储了当前代表内存池的二叉树的各个节点的内存使用情况,该数组长度为4096,二叉树的头结点在该数组的 // 第1号位,存储的值为0;两个一级子节点在该数组的第2号位和3号位,存储的值为1,依次类推。二叉树的叶节点 // 个数为2048,因而总节点数为4095。在进行内存分配时,会从头结点开始比较,然后比较左子节点,然后比较右 // 子节点,直到找到能够代表目标内存块的节点。当某个节点所代表的内存被申请之后,该节点的值就会被标记为12, // 表示该节点已经被占用 private final byte[] memoryMap; // 这里depthMap存储的数据结构与memoryMap是完全一样的,只不过其值在初始化之后一直不会发生变化。 // 该数据的主要作用在于通过目标索引位置值找到其在整棵树中对应的层数 private final byte[] depthMap; // 这里每一个PoolSubPage代表了二叉树的一个叶节点,也就是说,当二叉树叶节点内存被分配之后, // 其会使用一个PoolSubPage对其进行封装 private final PoolSubpage<T>[] subpages; // 其值为-8192,二进制表示为11111111111111111110000000000000,它的后面0的个数正好为12,而2^12=8192, // 因而将其与用户希望申请的内存大小进行“与操作“,如果其值不为0,就表示用户希望申请的内存在8192之上,从而 // 就可以快速判断其是在通过PoolSubPage的方式进行申请还是通过内存计算的方式。 private final int subpageOverflowMask; // 记录了每个业节点内存的大小,默认为8192,即8KB private final int pageSize; // 页节点所代表的偏移量,默认为13,主要作用是计算目标内存在内存池中是在哪个层中,具体的计算公式为: // int d = maxOrder - (log2(normCapacity) - pageShifts); // 比如9KB,经过log2(9KB)得到14,maxOrder为11,计算就得到10,表示9KB内存在内存池中为第10层的数据 private final int pageShifts; // 默认为11,表示当前你最大的层数 private final int maxOrder; // 记录了当前整个PoolChunk申请的内存大小,默认为16M private final int chunkSize; // 将chunkSize取2的对数,默认为24 private final int log2ChunkSize; // 指定了代表叶节点的PoolSubPage数组所需要初始化的长度 private final int maxSubpageAllocs; // 指定了某个节点如果已经被申请,那么其值将被标记为unusable所指定的值 private final byte unusable; // 对创建的ByteBuffer进行缓存的一个队列 private final Deque<ByteBuffer> cachedNioBuffers; // 记录了当前PoolChunk中还剩余的可申请的字节数 private int freeBytes; // 在Netty的内存池中,所有的PoolChunk都是由当前PoolChunkList进行组织的, // 关于PoolChunkList和其前置节点以及后置节点我们会在后续进行讲解,本文主要专注于PoolChunk的讲解 PoolChunkList<T> parent; // 在PoolChunkList中当前PoolChunk的前置节点 PoolChunk<T> prev; // 在PoolChunkList中当前PoolChunk的后置节点 PoolChunk<T> next;
3. 源码实现
关于 PoolChunk 的功能,我们这里主要对其内存的分配和回收过程进行讲解。
3.1 内存分配
PoolChunk 的内存分配主要在其 allocate() 方法中,而分配的整体描述前面已经进行了讲解,这里不再赘述,我们直接进入其源码进行阅读:
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
final long handle;
// 这里subpageOverflowMask=-8192,通过判断的结果可以看出目标容量是否小于8KB。
// 在下面的两个分支逻辑中,都会返回一个long型的handle,一个long占8个字节,其由低位的4个字节和高位的
// 4个字节组成,低位的4个字节表示当前normCapacity分配的内存在PoolChunk中所分配的节点在整个memoryMap
// 数组中的下标索引;而高位的4个字节则表示当前需要分配的内存在PoolSubPage所代表的8KB内存中的位图索引。
// 对于大于8KB的内存分配,由于其不会使用PoolSubPage来存储目标内存,因而高位四个字节的位图索引为0,
// 而低位的4个字节则还是表示目标内存节点在memoryMap中的位置索引;
// 对于低于8KB的内存分配,其会使用一个PoolSubPage来表示整个8KB内存,因而需要一个位图索引来表示目标内存
// 也即normCapacity会占用PoolSubPage中的哪一部分的内存。
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
// 申请高于8KB的内存
handle = allocateRun(normCapacity);
} else {
// 申请低于8KB的内存
handle = allocateSubpage(normCapacity);
}
// 如果返回的handle小于0,则表示要申请的内存大小超过了当前PoolChunk所能够申请的最大大小,也即16M,
// 因而返回false,外部代码则会直接申请目标内存,而不由当前PoolChunk处理
if (handle < 0) {
return false;
}
// 这里会从缓存的ByteBuf对象池中获取一个ByteBuf对象,不存在则返回null
ByteBuffer nioBuffer = cachedNioBuffers != null ? cachedNioBuffers.pollLast() : null;
// 通过申请到的内存数据对获取到的ByteBuf对象进行初始化,如果ByteBuf为null,则创建一个新的然后进行初始化
initBuf(buf, nioBuffer, handle, reqCapacity);
return true;
}
可以看到对于内存的分配,主要会判断其是否大于8KB,如果大于8KB,则会直接在PoolChunk的二叉树中年进行分配,如果小于8KB,则会直接申请一个8KB的内存,然后将8KB的内存交由一个PoolSubpage进行维护。关于PoolSubpage的实现原理,我们后续会进行讲解,这里我们只是对其进行简单的讲解,以帮助读者理解位图索引的概念。当我们从PoolChunk的二叉树中申请到了8KB内存之后,会将其交由一个PoolSubpage进行维护。在PoolSubpage中,其会将整个内存块大小切分为一系列的16字节大小,这里就是8KB,也就是说,它将被切分为512 = 8KB / 16byte份。为了标识这每一份是否被占用,PoolSubpage使用了一个long型数组来表示,该数组的名称为bitmap,因而我们称其为位图数组。为了表示512份数据是否被占用,而一个long只有64个字节,因而这里就需要8 = 512 / 64个long来表示,因而这里使用的的是long型数组,而不是单独的一个long字段。但是读者应该发现了,这里的handle高32位是一个整型值,而我们描述的bitmap是一个long型数组,那么一个整型是如何表示当前申请的内存是bitmap数组中的第几号元素,以及该元素中整型64字节中的第几位的。这里其实就是通过整型的低67位来表示的,第64~67位用来表示当前是占用的bitmap数组中的第几号long型元素,而1~64位则用来表示该long型元素的第多少位是当前申请占用的。因而这里只需要一个长整型的handle即可表示当前申请到的内存在整个内存池中的位置,以及在PoolSubpage中的位置。这里我们首先阅读 allocateRun() 方法的源码:
private long allocateRun(int normCapacity) {
// 这里maxOrder为11,表示整棵树最大的层数,log2(normCapacity)会将申请的目标内存大小转换为大于该大小的
// 第一个2的指数次幂数然后取2的对数的形式,比如log2(9KB)转换之后为14,这是因为大于9KB的第一个2的指数
// 次幂为16384,将其取2的对数后为14。pageShifts默认为13,这里整个表达式的目的就是快速计算出申请目标
// 内存(normCapacity)需要对应的层数。
int d = maxOrder - (log2(normCapacity) - pageShifts);
// 通过前面讲的递归方式从先父节点,然后左子节点,接着右子节点的方式依次判断其是否与目标层数相等,
// 如果相等,则会将该节点所对应的在memoryMap数组中的位置索引返回
int id = allocateNode(d);
// 如果返回值小于0,则说明在当前PoolChunk中无法分配目标大小的内存,这一般是由于目标内存大于16M,
// 或者当前PoolChunk已经分配了过多的内存,剩余可分配的内存不足以分配目标内存大小导致的
if (id < 0) {
return id;
}
// 更新剩余可分配内存的值
freeBytes -= runLength(id);
return id;
}
这里 allocateRun() 方法首先会计算目标内存所对应的二叉树层数,然后递归的在二叉树中查找是否有对应的节点,找到了则直接返回。这里我们继续看 allocateNode() 方法看其是如何对二叉树进行递归遍历的:
private int allocateNode(int d) {
int id = 1;
int initial = -(1 << d);
// 获取memoryMap中索引为id的位置的数据层数,初始时获取的就是根节点的层数
byte val = value(id);
// 如果更节点的层数值都比d要大,说明当前PoolChunk中没有足够的内存用于分配目标内存,直接返回-1
if (val > d) {
return -1;
}
// 这里就是通过比较当前节点的值是否比目标节点的值要小,如果要小,则说明当前节点所代表的子树是能够
// 分配目标内存大小的,则会继续遍历其左子节点,然后遍历右子节点
while (val < d || (id & initial) == 0) {
id <<= 1;
val = value(id);
// 这里val > d其实就是表示当前节点的数值比目标数值要大,也就是说当前节点是没法申请到目标容量的内存,
// 那么就会执行 id ^= 1,其实也就是将id切换到当前节点的兄弟节点,本质上其实就是从二叉树的
// 左子节点开始查找,如果左子节点无法分配目标大小的内存,那么就到右子节点进行查找
if (val > d) {
id ^= 1;
val = value(id);
}
}
// 当找到之后,获取该节点所在的层数
byte value = value(id);
// 将该memoryMap中该节点位置的值设置为unusable=12,表示其已经被占用
setValue(id, unusable);
// 递归的更新父节点的值,使其继续保持”父节点存储的层数所代表的内存大小是未分配的
// 子节点的层数所代表的内存之和“的语义。
updateParentsAlloc(id);
return id;
}
这里 allocateNode() 方法主要逻辑就是查找目标内存在memoryMap中的索引下标值,并且对所申请的节点的父节点值进行更新。下面我们来看看 allocateSubpage() 的实现原理:
private long allocateSubpage(int normCapacity) {
// 这里其实也是与PoolThreadCache中存储PoolSubpage的方式相同,也是采用分层的方式进行存储的,
// 具体是取目标数组中哪一个元素的PoolSubpage则是根据目标容量normCapacity来进行的。
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
int d = maxOrder;
synchronized (head) {
// 这里调用allocateNode()方法在二叉树中查找时,传入的d值maxOrder=11,也就是说,其本身就是
// 直接在叶节点上查找可用的叶节点位置
int id = allocateNode(d);
// 小于0说明没有符合条件的内存块
if (id < 0) {
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;
// 计算当前id对应的PoolSubpage数组中的位置
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
// 这里主要是通过一个PoolSubpage对申请到的内存块进行管理,具体的管理方式我们后续文章中会进行讲解。
if (subpage == null) {
// 这里runOffset()方法会返回该id在PoolChunk中维护的字节数组中的偏移量位置,
// normCapacity则记录了当前将要申请的内存大小;
// pageSize记录了每个页的大小,默认为8KB
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
} else {
subpage.init(head, normCapacity);
}
// 通过PoolSubpage申请一块内存,并且返回代表该内存块的位图索引,位图索引的具体计算方式,
// 我们前面已经简要讲述,详细的实现原理我们后面会进行讲解。
return subpage.allocate();
}
}
这里可以看到, allocateSubpage() 方法主要是将申请到的8KB内存交由一个PoolSubpage进行管理,并且由其返回响应的位图索引。这里关于handle参数的产生方式已经讲解完成,关于 allocate() 方法中 initBuf() 方法的调用,其原理比较简单,本质上就是首先计算申请到的内存块的起始位置地址值,以及申请的内存块的长度,然后将其设置到一个ByteBuf对象中,以对其进行初始化,这里不再赘述其实现原理。
3.2 内存释放
关于内存释放的原理,其比较简单,通过前面的讲解,我们可以看到,内存的申请就是在主内存块中查找可以申请的内存块,然后将代表其位置的比如层号,或者位图索引标志为已经分配。那么这里的释放过程其实就是返回来,然后将这些标志进行重置。这里我们以直接内存(ByteBuffer)的释放过程讲解内存释放的源码:
void free(long handle, ByteBuffer nioBuffer) {
int memoryMapIdx = memoryMapIdx(handle); // 根据当前内存块在memoryMap数组中的位置
int bitmapIdx = bitmapIdx(handle); // 获取当前内存块的位图索引
// 如果位图索引不等于0,说明当前内存块是小于8KB的内存块,因而将其释放过程交由PoolSubpage进行
if (bitmapIdx != 0) {
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
PoolSubpage<T> head = arena.findSubpagePoolHead(subpage.elemSize);
synchronized (head) {
// 由PoolSubpage释放内存
if (subpage.free(head, bitmapIdx & 0x3FFFFFFF)) {
return;
}
}
}
// 走到这里说明需要释放的内存大小大于8KB,这里首先计算要释放的内存块的大小
freeBytes += runLength(memoryMapIdx);
// 将要释放的内存块所对应的二叉树的节点对应的值进行重置
setValue(memoryMapIdx, depth(memoryMapIdx));
// 将要释放的内存块所对应的二叉树的各级父节点的值进行更新
updateParentsFree(memoryMapIdx);
// 将创建的ByteBuf对象释放到缓存池中,以便下次申请时复用
if (nioBuffer != null && cachedNioBuffers != null &&
cachedNioBuffers.size() < PooledByteBufAllocator
.DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK) {
cachedNioBuffers.offer(nioBuffer);
}
}
可以看到,这里对内存的释放,主要是判断其是否小于8KB,如果低于8KB,则将其交由PoolSubpage进行处理,否则就通过二叉树的方式对其进行重置。
4. 小结
本文首先对PoolChunk的整体结构进行了讲解,并且详细讲解了PoolChunk中平衡二叉树的实现原理。然后对PoolChunk中各个属性值进行了描述,以帮助读者后续阅读源码时更容易理解。最后我们对PoolChunk的两个主要功能:内存分配和释放的实现原理进行了详细讲解。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

