一个 JVM 参数引发的频繁 CMS GC
涤生的博客。 转载请注明原创出处,谢谢! 如果读完觉得有收获的话,欢迎关注公共号。
前言
了解 CMS GC 的同学,一定知道 -XX:CMSScavengeBeforeRemark 参数,它是用来开启或关闭在 CMS-remark 阶段之前的清除(Young GC)尝试。
大家都知道CMS GC 只会回收 OldGen 的对象,那为什么需要这个参数? 由于 YoungGen 存在引用 OldGen 对象的情况,因此 CMS-remark 阶段会将 YoungGen 作为 OldGen 的 “GC ROOTS” 进行扫描,防止回收了不该回收的对象。而配置 -XX:+CMSScavengeBeforeRemark 参数,在 CMS GC 的 CMS-remark 阶段开始前先进行一次 Young GC,有利于减少 Young Gen 对 Old Gen 的无效引用,降低 CMS-remark 阶段的时间开销。
这篇文章的内容是业务开发同学遇到的奇怪的频繁 CMS GC 问题,我们一起定位排查,最终发现跟 -XX:CMSScavengeBeforeRemark 参数相关。
问题
频繁 Full GC
业务开发同学通过监控发现线上一台机器频繁 CMS GC,下图是 CMS GC 监控图,大约从 20 点 5-15 分,每分钟 8-11 次的持续 CMS GC。 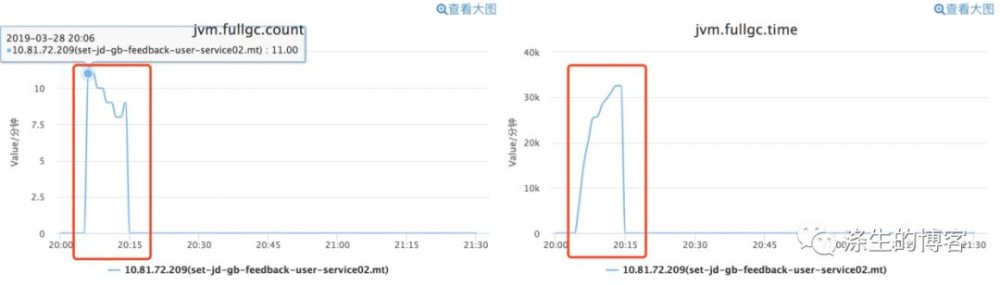
说明:公司监控对 Old GC 与 Full GC 是不区分的,案例中讲的其实是 CMS GC。
OldGen 使用空间占比
从下图 OldGen 的使用监控图来看,刚开始 OldGen 对象占用 OldGen 约 80% 的空间,经过 CMS GC 后,几乎立马空间使用的占用比例约在 30% 以下。 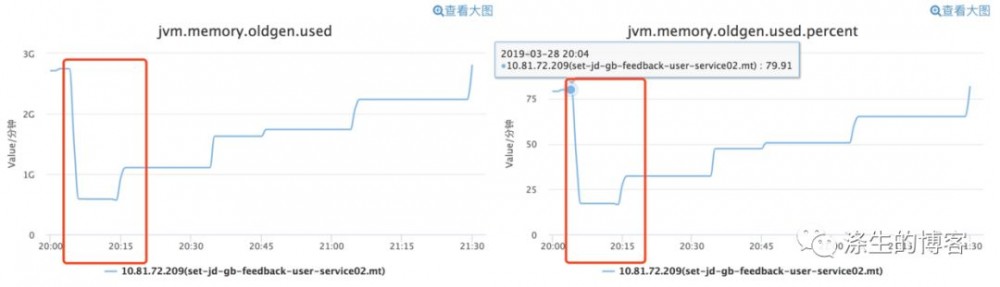
JVM 参数
结合 OldGen 的使用空间占比与 JVM 参数(-XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80),几乎可以断定第一次 CMS GC 是因为 OldGen 的使用占比到达了 OldGen 总量的 80%。
疑惑
第一次触发 CMS GC 可以通过 OldGen 的使用占比到达了 OldGen 总量的 80% 来解释,但是通过监控可以看到后来 OldGen 使用占比降低到 30% 以下,为什么还一直频繁进行 CMS GC?
分析
GC 监控图展示的还不够全面,具体问题还是要通过 GC 日志进行定位,因为 GC 日志中的信息更丰富。
GC 日志
为了分析问题,这里选取了第一次、第二次、第三次-第 N 次的 CMS GC 日志。
第一次 CMS GC日志
看第一次 CMS GC 日志,有以下四个发现:
-
由日志 “CMS-initial-mark: 2935428K(3354624K)”可知,第一次 CMS GC 是因为 2935428 / 3354624 = 87.5% > 80%,与此前监控图分析一致。
-
由日志 “2019-03-28T20:05:22.211+0800: 3644474.678: [CMS-concurrent-reset: 0.007/0.007 secs]” 可知,第一次 CMS GC 完成具体时间是 20:05:22.211。
-
由日志 “[GC (Allocation Failure) 3644462.647: [ParNew: 1887488K->201195K(1887488K), 0.4228807 secs]” 和日志 “[GC (CMS Final Remark) 3644463.375: [ParNew (promotion failed): 434406K->315478K(1887488K), 5.8407801 secs]”可知,第一次 CMS GC 日志中包含两次 Young GC,并且第一次 YoungGC 是由于 Allocation Failure,而第二次是因为什么呢,其实是因为配置了-XX:+CMSScavengeBeforeRemark 参数,因此在 CMS-remark 阶段前进行了一次 YoungGC。
-
除了以上的信息,还有个奇怪的现象是,Young GC 后 eden、from、to 三个 space 的使用量都不是 0 使用的情况,正常情况 Young GC 后 eden 和 to space 的使用量应该是 0。
这里其实不奇怪,通过日志 “concurrent mark-sweep generation total 3354624K, used 3171231K” 可知,OldGen 所剩无几,而且还可能存在碎片,这会导致 Young GC 晋升的对象,无处安放,导致 Young GC 回收停止了。
第二次 CMS GC 日志
看第二次 CMS GC 日志,有以下四个发现:
-
由日志 “CMS-initial-mark: 899032K(3354624K)” 可知,其实第一次 CMS GC 是已经回收了 OldGen,而且释放了大量空间,OldGen 的使用占比只有 899032 / 3354624 = 26.8%,很奇怪为什么会进行 CMS GC?
-
由日志 “2019-03-28T20:05:24.213+0800: 3644476.680: [GC (CMS Initial Mark)” 可知,第二次 CMS GC 开始的具体时间是 20:05:24.213,上次 CMS GC 结束时间 20:05:22.211 相差 2s。
-
由日志 “[GC (CMS Final Remark) 3644477.934: [ParNew: 649871K->649871K(1887488K), 0.0000289 secs]” 可知,第二次 CMS GC 日志中包含一次 Young GC,毫无疑问是因为配置了-XX:+CMSScavengeBeforeRemark 参数导致的。
-
Young GC 后 eden、from、to 三个 space 的使用量都不是 0 的情况依然存在,只是 eden space 由使用比率 13% 增加到 33%。
很奇怪,此时通过日志 “concurrent mark-sweep generation total 3354624K, used 899032K” 可知,OldGen 空闲空间很大,为什么 Young GC 好像没起作用。
第三次-第 N 次 CMS GC 日志
看第三次-第 N 次 CMS GC 日志,有三个发现:
-
由日志 “CMS-initial-mark: 573449K(3354624K)” 可知,OldGen 的使用占比只有 573449 / 3354624= 17.1%,很奇怪为什么会进行 CMS GC?
-
由日志 “2019-03-28T20:05:34.478+0800: 3644486.945: [GC (CMS Initial Mark)” 可知,第三次 CMS GC 的开始时间 20:05:34.478 与 第二次 CMS GC 结束时间 20:05:32.476 又相差 2s。
-
由于配置了 -XX:+CMSScavengeBeforeRemark 参数,CMS GC 过程中依然包含一次 Young GC。
-
Young GC 后 eden、from、to 三个 space 的使用量都不是 0 的情况依然存在,只是 eden space 由使用比率增长。 很奇怪,OldGen 空闲空间很大,为什么 Young GC 好像没起作用?
根源定位
通过日志分析,,大家很容易发现三个问题:
-
每次 CMS GC 都是相隔 2s? 这其实是 CMS background collector 的策略,每隔 CMSWaitDuration(默认为2000ms) 时间进行一次检测,若发现满足 CMS GC 触发条件,就进行一次 CMS background collector。
-
第二次及后面的 CMS GC,OldGen 的使用占比情况都没有达到 80%,很疑惑是什么导致了 CMS GC? 通过上面的分析,其实只要知道是什么满足了 CMS GC 触发条件而导致了 CMS GC,就能回答第二个问题。
-
Young GC 后 eden、from、to 三个 space 的使用量都不是 0 的情况,而且 OldGen 空闲空间很大,为什么 Young GC 好像没起作用。
源码排查
OldGen 的使用占比情况都没有达到 80%,什么原因导致的 CMS GC
下面我们来看下 CMS GC 触发条件,触发条件都在 shouldConcurrentCollect 函数里,返回 true 的都是可能的情况,这里分别解释下。
-
“if ( full gc_requested)” 这是由 System.gc() 调用且配置了 -XX:+ExplicitGCInvokesConcurrent 参数的情况下,会触发一次 CMS GC。但如果是 System.gc(),每次 CMS GC 的间隔时间不可能一直是 2s,故显然不符合。
-
“if (!UseCMSInitiatingOccupancyOnly)” 这是在没有配置 -XX:+UseCMSInitiatingOccupancyOnly 参数的情况下,可能触发 CMS GC 的情况,故显然不符合。
-
“if ( cmsGen->should concurrent_collect())” 这是 -XX:+UseCMSInitiatingOccupancyOnly 参数的情况下,如果 OldGen 使用占比达到 -XX:CMSInitiatingOccupancyFraction 参数设置值,就会触发 CMS GC,但第二次、第三-第 N 次明显不符合情况。
-
“if (gch->incremental collection will fail(true /* consult young */))” 这是一种悲观策略,判断新生代回收是否会失败,如果最近一次 Young GC 已经失败或者可能会失败,就会触发一次 CMS GC。这是符合本文说的情况的。
-
“if (MetaspaceGC::should concurrent collect())” 这是 Metaspace 满足 CMS GC 触发条件的情况,根据日志 “ Metaspace used 90199K, capacity 91456K, committed 91776K, reserved 1130496K” 中 Metaspace 空间使用情况,显然不符合。
-
“if (CMSTriggerInterval >= 0)” 这是配置了 -XX:CMSTriggerInterval 参数的情况,显然不符合。
接下来,我们具体分析下 incremental collection will fail(true) 函数,这个函数有两个判断条件 incremental collection failed() 或者 ! young gen->collection attempt is safe(),有一个成立就会返回 true。
我们先来看 incremental collection failed() 函数,这个函数返回的是 incremental collection failed 这个成员的值,这个值只有两个情况下会通过 set incremental collection failed() 函数设置成 true,并且会在 CMS GC 的 sweep 阶段会设置为 false。 第一种情况是: 晋升失败 Promotion failed,但是只有第一次 CMS GC 出现过一次,后续的Young GC 都不是 promotion failed,说明不是这种情况。
第二种情况是: Young GC 过程中,if (!collection attempt is safe()) 为 true,也会通过 set incremental collection failed() 函数设置。
我们再看看 collection attempt is safe() 函数的实现,会让你豁然开朗,if (!to()->is empty()) return false,刚好满足了每次 YoungGC to space 不为空。因此,是在这里 incremental collection_failed 被设置成 true,导致每隔 2s 触发一次 CMS GC,这就解释了为什么 OldGen 的使用占比情况都没有达到 80%,也会触发 CMS GC。
Young GC 后 eden、from、to 三个 space 的使用量都不是 0 的情况
看到这里,其实这个问题也很好解释了,我们看 ParNewGeneration::collect 函数中的这段代码就明白了,YoungGC 遇到 to space 不为空的情况下,直接 set incremental collection_failed() 完就返回了,并没有进行真正的 Young GC。
罪魁祸首
看到这里,你一定在想,那罪魁祸首到底是谁呢?表面上看是 to space 不为空导致触发了 Young GC,然后设置了 incremental collection failed 参数,进而满足了 CMS GC 触发条件。实质上是因为配置了 -XX:CMSScavengeBeforeRemark 参数,CMS GC 阶段强制进行了 Young GC,导致 to space 不为空,因此这个锅得由 -XX:CMSScavengeBeforeRemark 参数来背。
你可能要问即使不设置 -XX:CMSScavengeBeforeRemark 参数 CMS GC 阶段也是有可能会触发 Young GC,凭什么要让 -XX:CMSScavengeBeforeRemark 参数来背锅。
如果是 Allocation Failure 触发的 Young GC 也会有问题吗?
答案是不会,这里可以借助最后一次 CMS GC 日志来分析。
最后一次 CMS GC 日志
看上面的日志,你会发现这次 CMS GC 日志跟以往的都不太一样,CMS-concurrent-mark-start 日志出现后,后面的日志都不是按照 CMS GC 的各个阶段打出来的。 是的,后面其实是由于 Allocation Failure 而发生了一次 Young GC,从而中断了 CMS background collector,而进行了一次 CMS foreground collector,有 “concurrent mode failure” 为证。
也就是说一般的 Allocation Failure 引起的 YoungGC 在这种情况下,不会出现频繁 CMS GC,因此,把问题归结到 -XX:CMSScavengeBeforeRemark 参数不为过吧。
总结
本文主要是由于 -XX:CMSScavengeBeforeRemark 参数触发了 Young GC,但该 YoungGC 并没有成功进行的,反而促使 CMS background collector 触发条件满足,进而引发了频繁 CMS GC。
该怎么避免呢
一时也没有想到很好的办法,两个参考方案:
-
去掉 -XX:CMSScavengeBeforeRemark 参数
-
降低 YoungGen 大小,加快因 Allocation Failure 而触发正常 Young GC
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

