你并不了解 String
先说一些话题外话。

上篇文章 Core Java 52 问(含答案) 阅读量意外的高,总算没白费我整理了一个清明假期。其实也挺出乎我的意料的,因为涉及的内容大多数是 Java 基础。但是基础可能也正是很多人所欠缺的,正如我一直在写的 走进 JDK 系列,也算是从 JDK 源码的角度,从 JVM 的角度来梳理 Java 基础。万丈高楼平地起,对于一个程序员来说,抛去现在纷繁复杂,学也学不完的各种框架,计算机、操作系统、网络、语言基础等基础知识,这些东西是更重要的,后续的文章也会朝着这个方向,争取做一个 "基础型" 程序员。大家也可以多多关注我的公众号 秉心说 , 持续输出 Java、Android 原创知识分享,每周也会带来一篇阅读分享。
PS : 之前好像忘记说了,整个 走进 JDK 专栏都是基于 java 1.8 源码进行分析的。关于其他版本的差异,可能会提到,但是不会细说。所有添加注释的代码都上传到我的 Github 了, 传送门
好了,进入今天的正文吧!在走进 JDK 之 String 中,结合源代码分析了 String 的不可变性和它的一些常用方法。那么,你觉得你了解 String 了吗?来考考你吧,看看下面这题:
String str1 = new String("he") + new String("llo");
str1.intern();
String str2 = "hello";
System.out.println(str1 == str2);
String str3 = new String("h") + new String("ello2");
String str4 = "hello2";
str3.intern();
System.out.println(str3 == str4);
复制代码
你能快速准确的给出答案吗?我先剧透一下,打印结果是 :
true false 复制代码
如果你答对了并且能准确的在脑海里回想一遍编译期以及运行期每一行代码都发生了什么,那么就没有往下看的必要了。如果不行,且听我慢慢道来。
在说 String 之前,先说一些基本概念,不然后面的内容很容易看的云里雾里。
Class 常量池
我在之前的一篇文章Class 文件格式详解 中也说到过 Class 常量池 ,这里再总结一下。
常量池中主要存放两大类常量: 字面量(Literal) 和 符号引用(Symbolic Reference) ,字面量比较接近于 Java 语言层面的常量概念,如文本字符串 、声明为 final 的常量值等。而符号引用则属于编译原理方面的概念,包括了下面三类常量:
- 类和接口的全限定名(Fully Qualified Name)
- 字段的名称和描述符(Descriptor)
- 方法的名称和描述符
通过 javap 命令就可以看到 Class 文件的常量池部分了。
运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分,它是 Class 文件中每一个类或接口的常量池表的运行时表示形式。Class 常量池中存放的编译期生成的各种字面量和符号引用,将在类加载后进入方法区的运行时常量池中存放。
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态常量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫 Non-Heap(非堆) 。目的应该是与 Java 堆区分开来。
字符串常量池
字符串常量池是用来缓存字符串的。对于需要重复使用的字符串,每次都去 new 一个 String 实例,无疑是在浪费资源,降低效率。所以,JVM 一般会维护一个字符串常量池,它是全局共享的,你可是把它看成是一个 HashSet<String> 。需要注意的是,它保存的是堆中字符串实例的引用,并不存储实例本身。
看完上面这几个概念的介绍,记住下面几个重点:
-
Class 常量池是编译期生成的 Class 文件中的常量池 -
运行时常量池是Class 常量池在运行时的表示形式 -
字符串常量池是缓存字符串的,全局共享,它保存的是String实例对象的引用
先不看文章开头提出的问题,来看一道经典的面试题:
String str = new String("hello");
复制代码
上面的代码中创建了几个对象?
这样问其实前提还不够明确,再限定一些条件:
假设这行代码就是 main() 方法的第一行代码,且字符串常量池中原本没有 hello 的引用
首先经过编译器编译, Class 常量池 中存储了 hello 字符串。按照 Java 虚拟机规范,在类加载过程的解析(reslove)阶段,JVM 将 Class 常量池 中的符号引用替换为直接引用放入 运行时常量池 , 并将 Class 常量池 中的字面量在堆中生成对应的 String 实例对象。另外,JVM 顺道会把字符串缓存起来,即把它的引用加入到字符串常量池。
那么,在类加载阶段, hello 字符串的实例就已经创建,且字符串常量池也保存了其引用,真的是这样吗?其实不是的。Java 虚拟机规范中并没有规定解析阶段发生的具体时间,只要求了在执行 16 个用于操作符号引用的字节码指令之前,先对它们所使用的符号引用进行解析。所以一般在类加载阶段不会进行解析过程,还是等到一个符号引用将要被使用前才去解析它。也就是说到运行期,才会去创建字符串实例并存入字符串常量池。
接着通过字节码看看 String str = new String("hello") 是如何运行的,通过 javap 查看如下:
0: new #2 // class java/lang/String 3: dup 4: ldc #3 // String hello 6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V 9: astore_1 10: return 复制代码
new 表示新建了一个 String 对象。
dup 表示复制栈顶数值并将复制值压入栈顶。这里压入的是默认参数 this 。
ldc 是个很关键的命令,它表示将 int 、float 或 String 型常量从常量池中推送至栈顶。 ldc 就是之前提到的 16 种字节码指令中的一种。经过编译器和类加载阶段, hello 并不存在,那么此时 ldc 推什么去栈顶呢?其实, ldc 指令就会除触发类加载的解析过程。当字符串常量池中存在 hello 时则直接返回其引用。若不存在,在堆中创建 hello 实例并将其引用存入字符串常量池。
所以上面限定的条件下,会在执行 ldc 命令时,在堆中创建 hello 实例并将其引用存入字符串常量池。
invokespecial 执行了 init() 方法,即 String 的构造函数。
astore_1 表示将引用 str 指向刚刚创建的字符串对象。
大致说一下流程, new 一个 String 对象,然后利用 dup 和 ldc 向操作数栈压入构造函数所需的两个参数,默认参数 this 和字符串 hello ,接着调用 init 执行构造函数。最后,通过 astore_1 将引用 str 指向字符串实例。这样一看,创建了几个对象就显而易见了吧!
趁热打铁,再来一题:
String str1 = "java";
String str2 = new String("java");
System.out.println(str1 == str2);
复制代码
看一下字节码就知道在运行期,第一句代码没有新建对象,即没有使用 new 指令。而第二行代码使用了 new 指令,所以显然结果是 false 。
对照下图理解一下:
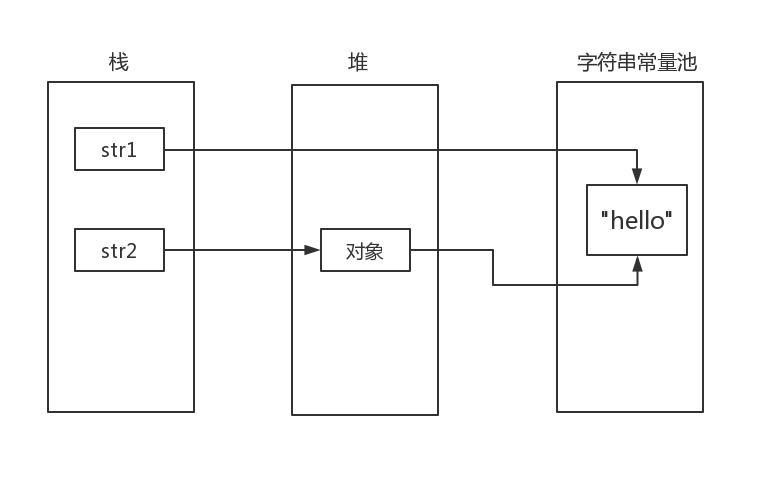
String.intern()
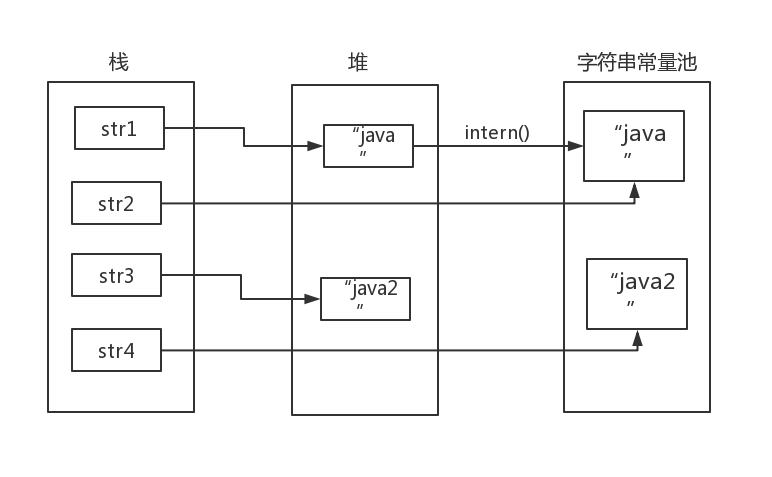
再来说说开头的题目中出现的 intern() 方法。说起来简单,其实也不简单,它的作用是查找当前字符串常量池是否存在该字符串的引用,如果存在直接返回引用;如果不存在,则在堆中创建该字符串实例,并返回其引用。结合下面这题来说明一下:
String str1 = "java"; // 1
String str2 = new String("java"); // 2
String str3 = new String("java").intern(); // 3
System.out.println(str1 == str2);
System.out.println(str1 == str3);
复制代码
s1 == s2 无疑是 false ,前面已经分析过。那么 s1 == s3 呢?老规矩,来分析一下代码,从编译器到运行期。
编译后 "java" 字符串进入 Class 常量池 ,此时并未在堆中创建对象,也未在字符串常量池中缓存 "java" 。运行期,执行第一行代码,创建 "java" 字符串实例并存入字符串常量池, str1 等同于常量池中的引用。第二行代码,会在堆中 new 一个 String 实例,并将 str2 指向它。第三行代码,先在堆中 new 一个 String 实例,然后调用 intern() 方法,尝试将其驻留在字符串常量池, intern() 方法首先会检查字符串常量池中是否已经驻留过该字符串,第一行代码中 "java" 字符串已经缓存到常量池了, intern() 方法会直接返回已经驻留的引用,所以这里 str1 和 str3 是等价的。
图片会更加直观一点:

基本概念都捋清楚之后,回头再来看开头的第一道题目,你会发现其实很简单。
String str1 = new String("j") + new String("ava"); // 1
str1.intern(); // 2
String str2 = "java"; // 3
System.out.println(str1 == str2); // 4
String str3 = new String("ja") + new String("va2"); // 1
String str4 = "java2"; // 2
str3.intern(); // 3
System.out.println(str3 == str4); // 4
复制代码
先看第一部分的 4 行代码。经过编译, j 、 ava 和 java 进入 Class 常量池 中。 类加载阶段并不会创建实例,驻留字符串常量池。到运行期,第一行代码中会创建 j 、 ava 实例并驻留常量池, + 会被 JVM 自动优化为 StringBuilder ,拼接出 java 字符串,将 str1 指向该字符串实例。需要注意的是,这里不会将 java 驻留到常量池。第二行代码调用了 intern() ,由于此时常量池中没有 java ,所以将 str1 的引用存入了常量池。第三行代码, ldc 指令发现常量池中就有 java ,直接返回常量池中其对应的引用,并赋给 str2 。所以 str1 和 str2 是相等的。
再看第二部分的 4 行代码,和第一部分相比,仅仅只是把 intern() 方法的调用往下挪了一行,就造成了最后结果的不同。经过编译, ja 、 va2 和 java2 进入 Class 常量池 中。第一行代码的执行和上一块一样,执行完成后字符串常量池中并没有驻留 java2 的引用, str3 指向堆中实例。第二行代码, ldc 指令发现常量池中没有 java2 ,就创建一个 java2 实例并将其驻留到常量池, str4 指向该实例。第三行代码, str3.intern() ,常量池中已经保存了 java2 的引用,直接返回该引用。只是我们并没有去接收返回值。所以, str3 和 str4 指向的是不同的内存地址。
上面的所有图示中把堆内存和字符串常量池分开画了,其实只是为了看起来清晰一些,实际上字符串常量池就是在堆中的。当然,前提条件是 Java 1.6 之后。在 Java 1.6,常量池是在永久代中的,和 Java 堆是完全分开来的区域,这也会导致上述代码执行结果不一样,有兴趣的可以试一下,我这里就不再展开分析了。
总结
关于 String ,展开来细说的话,涉及的内容十分之广。不可变类的实现,类加载的过程,解析阶段的延迟执行,全局字符串常量池的使用,Java 内存区域 ...... 理解了这些知识点,才能真正的去了解 String ,面对那些刁钻的面试题才可以游刃有余,捋清每一步流程。
最后推荐两篇经典文章,一篇是 R 大 的 请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧 。另一篇是美团技术团队的 深入理解 String.intern() 。
String 系列写了两篇了,
走进 JDK 之 String
你并不了解 String
最后一篇计划写一下关于字符串拼接的知识,回想一下你在代码中使用过哪些拼接字符串的方式,以及它们的区别,敬请期待。
文章首发于微信公众号: 秉心说 , 专注 Java 、 Android 原创知识分享,LeetCode 题解,欢迎关注!

正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

